 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Ideate for Machine Learning Engineering Agents
Jan 24, 2026Existing machine learning engineering (MLE) agents struggle to iteratively optimize their implemented algorithms for effectiveness. To address this, we introduce MLE-Ideator, a dual-agent framework that separates ideation from implementation. In our system, an implementation agent can request strategic help from a dedicated Ideator. We show this approach is effective in two ways. First, in a training-free setup, our framework significantly outperforms implementation-only agent baselines on MLE-Bench. Second, we demonstrate that the Ideator can be trained with reinforcement learning (RL) to generate more effective ideas. With only 1K training samples from 10 MLE tasks, our RL-trained Qwen3-8B Ideator achieves an 11.5% relative improvement compared to its untrained counterpart and surpasses Claude Sonnet 3.5. These results highlights a promising path toward training strategic AI systems for scientific discovery.
Diffusion Language Model Inference with Monte Carlo Tree Search
Dec 13, 2025Diffusion language models (DLMs) have recently emerged as a compelling alternative to autoregressive generation, offering parallel generation and improved global coherence. During inference, DLMs generate text by iteratively denoising masked sequences in parallel; however, determining which positions to unmask and which tokens to commit forms a large combinatorial search problem. Existing inference methods approximate this search using heuristics, which often yield suboptimal decoding paths; other approaches instead rely on additional training to guide token selection. To introduce a principled search mechanism for DLMs inference, we introduce MEDAL, a framework that integrates Monte Carlo Tree SEarch initialization for Diffusion LAnguage Model inference. We employ Monte Carlo Tree Search at the initialization stage to explore promising unmasking trajectories, providing a robust starting point for subsequent refinement. This integration is enabled by restricting the search space to high-confidence actions and prioritizing token choices that improve model confidence over remaining masked positions. Across multiple benchmarks, MEDAL achieves up to 22.0% improvement over existing inference strategies, establishing a new paradigm for search-based inference in diffusion language models.
Black-Box Visual Prompt Engineering for Mitigating Object Hallucination in Large Vision Language Models
Apr 30, 2025Large Vision Language Models (LVLMs) often suffer from object hallucination, which undermines their reliability. Surprisingly, we find that simple object-based visual prompting -- overlaying visual cues (e.g., bounding box, circle) on images -- can significantly mitigate such hallucination; however, different visual prompts (VPs) vary in effectiveness. To address this, we propose Black-Box Visual Prompt Engineering (BBVPE), a framework to identify optimal VPs that enhance LVLM responses without needing access to model internals. Our approach employs a pool of candidate VPs and trains a router model to dynamically select the most effective VP for a given input image. This black-box approach is model-agnostic, making it applicable to both open-source and proprietary LVLMs. Evaluations on benchmarks such as POPE and CHAIR demonstrate that BBVPE effectively reduces object hallucination.
A Systematic Survey of Automatic Prompt Optimization Techniques
Feb 24, 2025Since the advent of large language models (LLMs), prompt engineering has been a crucial step for eliciting desired responses for various Natural Language Processing (NLP) tasks. However, prompt engineering remains an impediment for end users due to rapid advances in models, tasks, and associated best practices. To mitigate this, Automatic Prompt Optimization (APO) techniques have recently emerged that use various automated techniques to help improve the performance of LLMs on various tasks. In this paper, we present a comprehensive survey summarizing the current progress and remaining challenges in this field. We provide a formal definition of APO, a 5-part unifying framework, and then proceed to rigorously categorize all relevant works based on their salient features therein. We hope to spur further research guided by our framework.
Parameter Efficient Mamba Tuning via Projector-targeted Diagonal-centric Linear Transformation
Nov 21, 2024



Despite the growing interest in Mamba architecture as a potential replacement for Transformer architecture, parameter-efficient fine-tuning (PEFT) approaches for Mamba remain largely unexplored. In our study, we introduce two key insights-driven strategies for PEFT in Mamba architecture: (1) While state-space models (SSMs) have been regarded as the cornerstone of Mamba architecture, then expected to play a primary role in transfer learning, our findings reveal that Projectors -- not SSMs -- are the predominant contributors to transfer learning, and (2) Based on our observation that adapting pretrained Projectors to new tasks can be effectively approximated through a near-diagonal linear transformation, we propose a novel PEFT method specialized to Mamba architecture: Projector-targeted Diagonal-centric Linear Transformation (ProDiaL). ProDiaL focuses on optimizing only diagonal-centric linear transformation matrices, without directly fine-tuning the pretrained Projector weights. This targeted approach allows efficient task adaptation, utilizing less than 1% of the total parameters, and exhibits strong performance across both vision and language Mamba models, highlighting its versatility and effectiveness.
Diffusion Model Patching via Mixture-of-Prompts
May 30, 2024



We present Diffusion Model Patching (DMP), a simple method to boost the performance of pre-trained diffusion models that have already reached convergence, with a negligible increase in parameters. DMP inserts a small, learnable set of prompts into the model's input space while keeping the original model frozen. The effectiveness of DMP is not merely due to the addition of parameters but stems from its dynamic gating mechanism, which selects and combines a subset of learnable prompts at every step of the generative process (e.g., reverse denoising steps). This strategy, which we term "mixture-of-prompts", enables the model to draw on the distinct expertise of each prompt, essentially "patching" the model's functionality at every step with minimal yet specialized parameters. Uniquely, DMP enhances the model by further training on the same dataset on which it was originally trained, even in a scenario where significant improvements are typically not expected due to model convergence. Experiments show that DMP significantly enhances the converged FID of DiT-L/2 on FFHQ 256x256 by 10.38%, achieved with only a 1.43% parameter increase and 50K additional training iterations.
Flow-Assisted Motion Learning Network for Weakly-Supervised Group Activity Recognition
May 28, 2024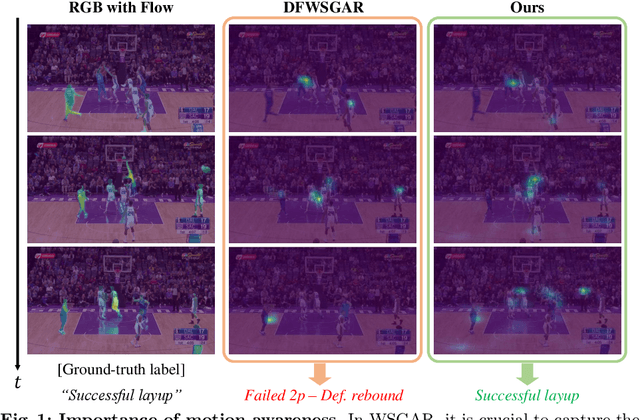



Weakly-Supervised Group Activity Recognition (WSGAR) aims to understand the activity performed together by a group of individuals with the video-level label and without actor-level labels. We propose Flow-Assisted Motion Learning Network (Flaming-Net) for WSGAR, which consists of the motion-aware actor encoder to extract actor features and the two-pathways relation module to infer the interaction among actors and their activity. Flaming-Net leverages an additional optical flow modality in the training stage to enhance its motion awareness when finding locally active actors. The first pathway of the relation module, the actor-centric path, initially captures the temporal dynamics of individual actors and then constructs inter-actor relationships. In parallel, the group-centric path starts by building spatial connections between actors within the same timeframe and then captures simultaneous spatio-temporal dynamics among them. We demonstrate that Flaming-Net achieves new state-of-the-art WSGAR results on two benchmarks, including a 2.8%p higher MPCA score on the NBA dataset. Importantly, we use the optical flow modality only for training and not for inference.
RITUAL: Random Image Transformations as a Universal Anti-hallucination Lever in LVLMs
May 28, 2024



Recent advancements in Large Vision Language Models (LVLMs) have revolutionized how machines understand and generate textual responses based on visual inputs. Despite their impressive capabilities, they often produce "hallucinatory" outputs that do not accurately reflect the visual information, posing challenges in reliability and trustworthiness. Current methods such as contrastive decoding have made strides in addressing these issues by contrasting the original probability distribution of generated tokens with distorted counterparts; yet, generating visually-faithful outputs remains a challenge. In this work, we shift our focus to the opposite: What could serve as a complementary enhancement to the original probability distribution? We propose a simple, training-free method termed RITUAL to enhance robustness against hallucinations in LVLMs. Our approach employs random image transformations as complements to the original probability distribution, aiming to mitigate the likelihood of hallucinatory visual explanations by enriching the model's exposure to varied visual scenarios. Our empirical results show that while the isolated use of transformed images initially degrades performance, strategic implementation of these transformations can indeed serve as effective complements. Notably, our method is compatible with current contrastive decoding methods and does not require external models or costly self-feedback mechanisms, making it a practical addition. In experiments, RITUAL significantly outperforms existing contrastive decoding methods across several object hallucination benchmarks, including POPE, CHAIR, and MME.
Don't Miss the Forest for the Trees: Attentional Vision Calibration for Large Vision Language Models
May 28, 2024This study addresses the issue observed in Large Vision Language Models (LVLMs), where excessive attention on a few image tokens, referred to as blind tokens, leads to hallucinatory responses in tasks requiring fine-grained understanding of visual objects. We found that tokens receiving lower attention weights often hold essential information for identifying nuanced object details -- ranging from merely recognizing object existence to identifying their attributes (color, position, etc.) and understanding their relationships. To counteract the over-emphasis on blind tokens and to accurately respond to user queries, we introduce a technique called Attentional Vision Calibration (AVC). During the decoding phase, AVC identifies blind tokens by analyzing the image-related attention distribution. It then dynamically adjusts the logits for the next token prediction by contrasting the logits conditioned on the original visual tokens with those conditioned on the blind tokens. This effectively lowers the dependency on blind tokens and promotes a more balanced consideration of all tokens. We validate AVC on benchmarks such as POPE, MME, and AMBER, where it consistently outperforms existing decoding techniques in mitigating object hallucinations in LVLMs.
Spatio-Temporal Proximity-Aware Dual-Path Model for Panoramic Activity Recognition
Mar 21, 2024



Panoramic Activity Recognition (PAR) seeks to identify diverse human activities across different scales, from individual actions to social group and global activities in crowded panoramic scenes. PAR presents two major challenges: 1) recognizing the nuanced interactions among numerous individuals and 2) understanding multi-granular human activities. To address these, we propose Social Proximity-aware Dual-Path Network (SPDP-Net) based on two key design principles. First, while previous works often focus on spatial distance among individuals within an image, we argue to consider the spatio-temporal proximity. It is crucial for individual relation encoding to correctly understand social dynamics. Secondly, deviating from existing hierarchical approaches (individual-to-social-to-global activity), we introduce a dual-path architecture for multi-granular activity recognition. This architecture comprises individual-to-global and individual-to-social paths, mutually reinforcing each other's task with global-local context through multiple layers. Through extensive experiments, we validate the effectiveness of the spatio-temporal proximity among individuals and the dual-path architecture in PAR. Furthermore, SPDP-Net achieves new state-of-the-art performance with 46.5\% of overall F1 score on JRDB-PAR dataset.