 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Ideate for Machine Learning Engineering Agents
Jan 24, 2026Existing machine learning engineering (MLE) agents struggle to iteratively optimize their implemented algorithms for effectiveness. To address this, we introduce MLE-Ideator, a dual-agent framework that separates ideation from implementation. In our system, an implementation agent can request strategic help from a dedicated Ideator. We show this approach is effective in two ways. First, in a training-free setup, our framework significantly outperforms implementation-only agent baselines on MLE-Bench. Second, we demonstrate that the Ideator can be trained with reinforcement learning (RL) to generate more effective ideas. With only 1K training samples from 10 MLE tasks, our RL-trained Qwen3-8B Ideator achieves an 11.5% relative improvement compared to its untrained counterpart and surpasses Claude Sonnet 3.5. These results highlights a promising path toward training strategic AI systems for scientific discovery.
Diffusion Language Model Inference with Monte Carlo Tree Search
Dec 13, 2025Diffusion language models (DLMs) have recently emerged as a compelling alternative to autoregressive generation, offering parallel generation and improved global coherence. During inference, DLMs generate text by iteratively denoising masked sequences in parallel; however, determining which positions to unmask and which tokens to commit forms a large combinatorial search problem. Existing inference methods approximate this search using heuristics, which often yield suboptimal decoding paths; other approaches instead rely on additional training to guide token selection. To introduce a principled search mechanism for DLMs inference, we introduce MEDAL, a framework that integrates Monte Carlo Tree SEarch initialization for Diffusion LAnguage Model inference. We employ Monte Carlo Tree Search at the initialization stage to explore promising unmasking trajectories, providing a robust starting point for subsequent refinement. This integration is enabled by restricting the search space to high-confidence actions and prioritizing token choices that improve model confidence over remaining masked positions. Across multiple benchmarks, MEDAL achieves up to 22.0% improvement over existing inference strategies, establishing a new paradigm for search-based inference in diffusion language models.
PromptPrism: A Linguistically-Inspired Taxonomy for Prompts
May 19, 2025Prompts are the interface for eliciting the capabilities of large language models (LLMs). Understanding their structure and components is critical for analyzing LLM behavior and optimizing performance. However, the field lacks a comprehensive framework for systematic prompt analysis and understanding. We introduce PromptPrism, a linguistically-inspired taxonomy that enables prompt analysis across three hierarchical levels: functional structure, semantic component, and syntactic pattern. We show the practical utility of PromptPrism by applying it to three applications: (1) a taxonomy-guided prompt refinement approach that automatically improves prompt quality and enhances model performance across a range of tasks; (2) a multi-dimensional dataset profiling method that extracts and aggregates structural, semantic, and syntactic characteristics from prompt datasets, enabling comprehensive analysis of prompt distributions and patterns; (3) a controlled experimental framework for prompt sensitivity analysis by quantifying the impact of semantic reordering and delimiter modifications on LLM performance. Our experimental results validate the effectiveness of our taxonomy across these applications, demonstrating that PromptPrism provides a foundation for refining, profiling, and analyzing prompts.
SLOT: Structuring the Output of Large Language Models
May 06, 2025Structured outputs are essential for large language models (LLMs) in critical applications like agents and information extraction. Despite their capabilities, LLMs often generate outputs that deviate from predefined schemas, significantly hampering reliable application development. We present SLOT (Structured LLM Output Transformer), a model-agnostic approach that transforms unstructured LLM outputs into precise structured formats. While existing solutions predominantly rely on constrained decoding techniques or are tightly coupled with specific models, SLOT employs a fine-tuned lightweight language model as a post-processing layer, achieving flexibility across various LLMs and schema specifications. We introduce a systematic pipeline for data curation and synthesis alongside a formal evaluation methodology that quantifies both schema accuracy and content fidelity. Our results demonstrate that fine-tuned Mistral-7B model with constrained decoding achieves near perfect schema accuracy (99.5%) and content similarity (94.0%), outperforming Claude-3.5-Sonnet by substantial margins (+25 and +20 percentage points, respectively). Notably, even compact models like Llama-3.2-1B can match or exceed the structured output capabilities of much larger proprietary models when equipped with SLOT, enabling reliable structured generation in resource-constrained environments.
Black-Box Visual Prompt Engineering for Mitigating Object Hallucination in Large Vision Language Models
Apr 30, 2025Large Vision Language Models (LVLMs) often suffer from object hallucination, which undermines their reliability. Surprisingly, we find that simple object-based visual prompting -- overlaying visual cues (e.g., bounding box, circle) on images -- can significantly mitigate such hallucination; however, different visual prompts (VPs) vary in effectiveness. To address this, we propose Black-Box Visual Prompt Engineering (BBVPE), a framework to identify optimal VPs that enhance LVLM responses without needing access to model internals. Our approach employs a pool of candidate VPs and trains a router model to dynamically select the most effective VP for a given input image. This black-box approach is model-agnostic, making it applicable to both open-source and proprietary LVLMs. Evaluations on benchmarks such as POPE and CHAIR demonstrate that BBVPE effectively reduces object hallucination.
CSPLADE: Learned Sparse Retrieval with Causal Language Models
Apr 15, 2025In recent years, dense retrieval has been the focus of information retrieval (IR) research. While effective, dense retrieval produces uninterpretable dense vectors, and suffers from the drawback of large index size. Learned sparse retrieval (LSR) has emerged as promising alternative, achieving competitive retrieval performance while also being able to leverage the classical inverted index data structure for efficient retrieval. However, limited works have explored scaling LSR beyond BERT scale. In this work, we identify two challenges in training large language models (LLM) for LSR: (1) training instability during the early stage of contrastive training; (2) suboptimal performance due to pre-trained LLM's unidirectional attention. To address these challenges, we propose two corresponding techniques: (1) a lightweight adaptation training phase to eliminate training instability; (2) two model variants to enable bidirectional information. With these techniques, we are able to train LSR models with 8B scale LLM, and achieve competitive retrieval performance with reduced index size. Furthermore, we are among the first to analyze the performance-efficiency tradeoff of LLM-based LSR model through the lens of model quantization. Our findings provide insights into adapting LLMs for efficient retrieval modeling.
A Systematic Survey of Automatic Prompt Optimization Techniques
Feb 24, 2025Since the advent of large language models (LLMs), prompt engineering has been a crucial step for eliciting desired responses for various Natural Language Processing (NLP) tasks. However, prompt engineering remains an impediment for end users due to rapid advances in models, tasks, and associated best practices. To mitigate this, Automatic Prompt Optimization (APO) techniques have recently emerged that use various automated techniques to help improve the performance of LLMs on various tasks. In this paper, we present a comprehensive survey summarizing the current progress and remaining challenges in this field. We provide a formal definition of APO, a 5-part unifying framework, and then proceed to rigorously categorize all relevant works based on their salient features therein. We hope to spur further research guided by our framework.
Retrieval as Attention: End-to-end Learning of Retrieval and Reading within a Single Transformer
Dec 05, 2022



Systems for knowledge-intensive tasks such as open-domain question answering (QA) usually consist of two stages: efficient retrieval of relevant documents from a large corpus and detailed reading of the selected documents to generate answers. Retrievers and readers are usually modeled separately, which necessitates a cumbersome implementation and is hard to train and adapt in an end-to-end fashion. In this paper, we revisit this design and eschew the separate architecture and training in favor of a single Transformer that performs Retrieval as Attention (ReAtt), and end-to-end training solely based on supervision from the end QA task. We demonstrate for the first time that a single model trained end-to-end can achieve both competitive retrieval and QA performance, matching or slightly outperforming state-of-the-art separately trained retrievers and readers. Moreover, end-to-end adaptation significantly boosts its performance on out-of-domain datasets in both supervised and unsupervised settings, making our model a simple and adaptable solution for knowledge-intensive tasks. Code and models are available at https://github.com/jzbjyb/ReAtt.
Understanding and Improving Zero-shot Multi-hop Reasoning in Generative Question Answering
Oct 09, 2022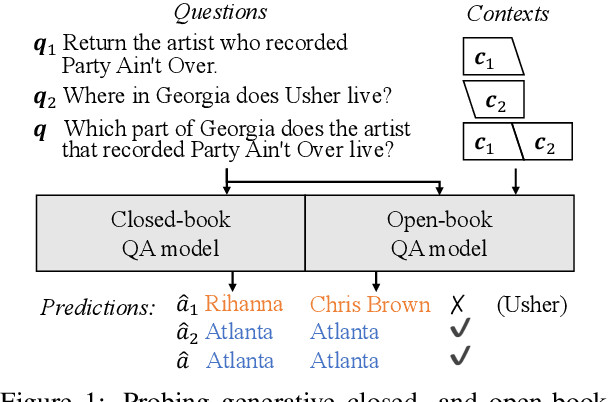

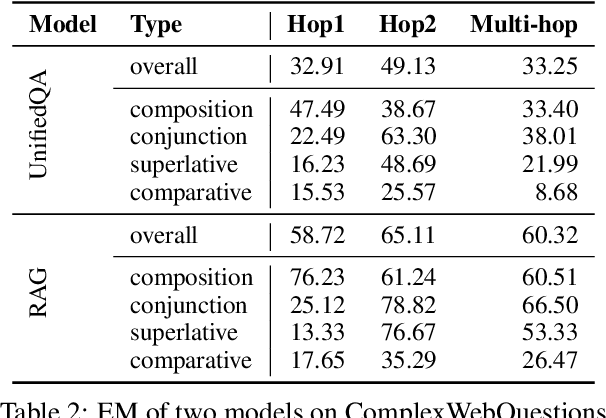
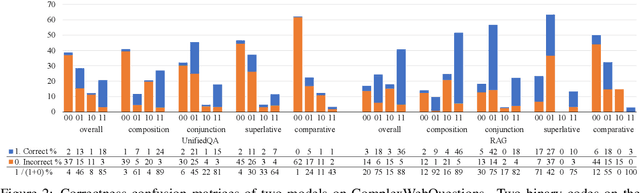
Generative question answering (QA) models generate answers to questions either solely based on the parameters of the model (the closed-book setting) or additionally retrieving relevant evidence (the open-book setting). Generative QA models can answer some relatively complex questions, but the mechanism through which they do so is still poorly understood. We perform several studies aimed at better understanding the multi-hop reasoning capabilities of generative QA models. First, we decompose multi-hop questions into multiple corresponding single-hop questions, and find marked inconsistency in QA models' answers on these pairs of ostensibly identical question chains. Second, we find that models lack zero-shot multi-hop reasoning ability: when trained only on single-hop questions, models generalize poorly to multi-hop questions. Finally, we demonstrate that it is possible to improve models' zero-shot multi-hop reasoning capacity through two methods that approximate real multi-hop natural language (NL) questions by training on either concatenation of single-hop questions or logical forms (SPARQL). In sum, these results demonstrate that multi-hop reasoning does not emerge naturally in generative QA models, but can be encouraged by advances in training or modeling techniques.
Weakly Supervised Named Entity Tagging with Learnable Logical Rules
Jul 05, 2021


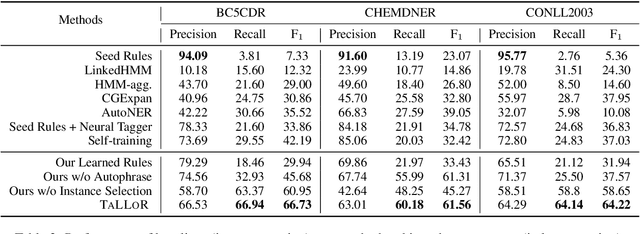
We study the problem of building entity tagging systems by using a few rules as weak supervision. Previous methods mostly focus on disambiguation entity types based on contexts and expert-provided rules, while assuming entity spans are given. In this work, we propose a novel method TALLOR that bootstraps high-quality logical rules to train a neural tagger in a fully automated manner. Specifically, we introduce compound rules that are composed from simple rules to increase the precision of boundary detection and generate more diverse pseudo labels. We further design a dynamic label selection strategy to ensure pseudo label quality and therefore avoid overfitting the neural tagger. Experiments on three datasets demonstrate that our method outperforms other weakly supervised methods and even rivals a state-of-the-art distantly supervised tagger with a lexicon of over 2,000 terms when starting from only 20 simple rules. Our method can serve as a tool for rapidly building taggers in emerging domains and tasks. Case studies show that learned rules can potentially explain the predicted entities.