 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQL-Trail: Multi-Turn Reinforcement Learning with Interleaved Feedback for Text-to-SQL
Jan 25, 2026While large language models (LLMs) have substantially improved Text-to-SQL generation, a pronounced gap remains between AI systems and human experts on challenging benchmarks such as BIRD-SQL. We argue this gap stems largely from the prevailing single-pass paradigm, which lacks the iterative reasoning, schema exploration, and error-correction behaviors that humans naturally employ. To address this limitation, we introduce SQL-Trail, a multi-turn reinforcement learning (RL) agentic framework for Text-to-SQL. Rather than producing a query in one shot, SQL-Trail interacts with the database environment and uses execution feedback to iteratively refine its predictions. Our approach centers on two key ideas: (i) an adaptive turn-budget allocation mechanism that scales the agent's interaction depth to match question difficulty, and (ii) a composite reward panel that jointly incentivizes SQL correctness and efficient exploration. Across benchmarks, SQL-Trail sets a new state of the art and delivers strong data efficiency--up to 18x higher than prior single-pass RL state-of-the-art methods. Notably, our 7B and 14B models outperform substantially larger proprietary systems by 5% on average, underscoring the effectiveness of interactive, agentic workflows for robust Text-to-SQL generation.
PromptPrism: A Linguistically-Inspired Taxonomy for Prompts
May 19, 2025Prompts are the interface for eliciting the capabilities of large language models (LLMs). Understanding their structure and components is critical for analyzing LLM behavior and optimizing performance. However, the field lacks a comprehensive framework for systematic prompt analysis and understanding. We introduce PromptPrism, a linguistically-inspired taxonomy that enables prompt analysis across three hierarchical levels: functional structure, semantic component, and syntactic pattern. We show the practical utility of PromptPrism by applying it to three applications: (1) a taxonomy-guided prompt refinement approach that automatically improves prompt quality and enhances model performance across a range of tasks; (2) a multi-dimensional dataset profiling method that extracts and aggregates structural, semantic, and syntactic characteristics from prompt datasets, enabling comprehensive analysis of prompt distributions and patterns; (3) a controlled experimental framework for prompt sensitivity analysis by quantifying the impact of semantic reordering and delimiter modifications on LLM performance. Our experimental results validate the effectiveness of our taxonomy across these applications, demonstrating that PromptPrism provides a foundation for refining, profiling, and analyzing prompts.
A Systematic Survey of Automatic Prompt Optimization Techniques
Feb 24, 2025Since the advent of large language models (LLMs), prompt engineering has been a crucial step for eliciting desired responses for various Natural Language Processing (NLP) tasks. However, prompt engineering remains an impediment for end users due to rapid advances in models, tasks, and associated best practices. To mitigate this, Automatic Prompt Optimization (APO) techniques have recently emerged that use various automated techniques to help improve the performance of LLMs on various tasks. In this paper, we present a comprehensive survey summarizing the current progress and remaining challenges in this field. We provide a formal definition of APO, a 5-part unifying framework, and then proceed to rigorously categorize all relevant works based on their salient features therein. We hope to spur further research guided by our framework.
Examining Alignment of Large Language Models through Representative Heuristics: The Case of Political Stereotypes
Jan 27, 2025



Examining the alignment of large language models (LLMs) has become increasingly important, particularly when these systems fail to operate as intended. This study explores the challenge of aligning LLMs with human intentions and values, with specific focus on their political inclinations. Previous research has highlighted LLMs' propensity to display political leanings, and their ability to mimic certain political parties' stances on various issues. However, the extent and conditions under which LLMs deviate from empirical positions have not been thoroughly examined. To address this gap, our study systematically investigates the factors contributing to LLMs' deviations from empirical positions on political issues, aiming to quantify these deviations and identify the conditions that cause them. Drawing on cognitive science findings related to representativeness heuristics -- where individuals readily recall the representative attribute of a target group in a way that leads to exaggerated beliefs -- we scrutinize LLM responses through this heuristics lens. We conduct experiments to determine how LLMs exhibit stereotypes by inflating judgments in favor of specific political parties. Our results indicate that while LLMs can mimic certain political parties' positions, they often exaggerate these positions more than human respondents do. Notably, LLMs tend to overemphasize representativeness to a greater extent than humans. This study highlights the susceptibility of LLMs to representativeness heuristics, suggeseting potential vulnerabilities to political stereotypes. We propose prompt-based mitigation strategies that demonstrate effectiveness in reducing the influence of representativeness in LLM responses.
Adaptive Video Understanding Agent: Enhancing efficiency with dynamic frame sampling and feedback-driven reasoning
Oct 26, 2024Understanding long-form video content presents significant challenges due to its temporal complexity and the substantial computational resources required. In this work, we propose an agent-based approach to enhance both the efficiency and effectiveness of long-form video understanding by utilizing large language models (LLMs) and their tool-harnessing ability. A key aspect of our method is query-adaptive frame sampling, which leverages the reasoning capabilities of LLMs to process only the most relevant frames in real-time, and addresses an important limitation of existing methods which typically involve sampling redundant or irrelevant frames. To enhance the reasoning abilities of our video-understanding agent, we leverage the self-reflective capabilities of LLMs to provide verbal reinforcement to the agent, which leads to improved performance while minimizing the number of frames accessed. We evaluate our method across several video understanding benchmarks and demonstrate that not only it enhances state-of-the-art performance but also improves efficiency by reducing the number of frames sampled.
Beyond Binary Gender Labels: Revealing Gender Biases in LLMs through Gender-Neutral Name Predictions
Jul 07, 2024Name-based gender prediction has traditionally categorized individuals as either female or male based on their names, using a binary classification system. That binary approach can be problematic in the cases of gender-neutral names that do not align with any one gender, among other reasons. Relying solely on binary gender categories without recognizing gender-neutral names can reduce the inclusiveness of gender prediction tasks. We introduce an additional gender category, i.e., "neutral", to study and address potential gender biases in Large Language Models (LLMs). We evaluate the performance of several foundational and large language models in predicting gender based on first names only. Additionally, we investigate the impact of adding birth years to enhance the accuracy of gender prediction, accounting for shifting associations between names and genders over time. Our findings indicate that most LLMs identify male and female names with high accuracy (over 80%) but struggle with gender-neutral names (under 40%), and the accuracy of gender prediction is higher for English-based first names than non-English names. The experimental results show that incorporating the birth year does not improve the overall accuracy of gender prediction, especially for names with evolving gender associations. We recommend using caution when applying LLMs for gender identification in downstream tasks, particularly when dealing with non-binary gender labels.
StereoMap: Quantifying the Awareness of Human-like Stereotypes in Large Language Models
Oct 31, 2023Large Language Models (LLMs) have been observed to encode and perpetuate harmful associations present in the training data. We propose a theoretically grounded framework called StereoMap to gain insights into their perceptions of how demographic groups have been viewed by society. The framework is grounded in the Stereotype Content Model (SCM); a well-established theory from psychology. According to SCM, stereotypes are not all alike. Instead, the dimensions of Warmth and Competence serve as the factors that delineate the nature of stereotypes. Based on the SCM theory, StereoMap maps LLMs' perceptions of social groups (defined by socio-demographic features) using the dimensions of Warmth and Competence. Furthermore, the framework enables the investigation of keywords and verbalizations of reasoning of LLMs' judgments to uncover underlying factors influencing their perceptions. Our results show that LLMs exhibit a diverse range of perceptions towards these groups, characterized by mixed evaluations along the dimensions of Warmth and Competence. Furthermore, analyzing the reasonings of LLMs, our findings indicate that LLMs demonstrate an awareness of social disparities, often stating statistical data and research findings to support their reasoning. This study contributes to the understanding of how LLMs perceive and represent social groups, shedding light on their potential biases and the perpetuation of harmful associations.
Examining the Causal Effect of First Names on Language Models: The Case of Social Commonsense Reasoning
Jun 01, 2023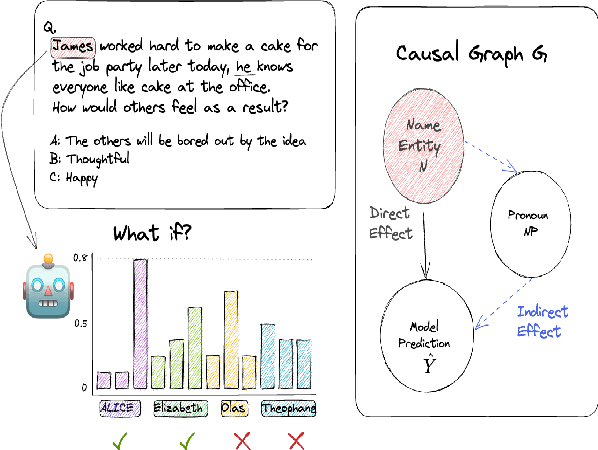
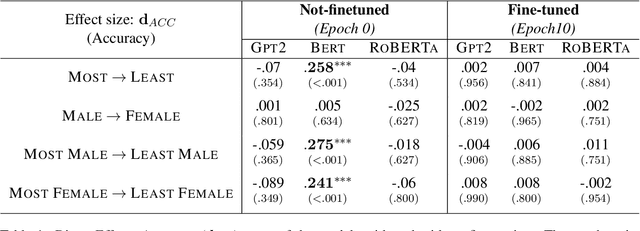
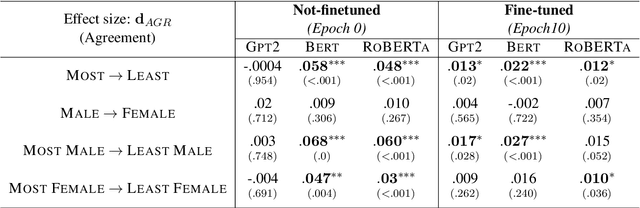
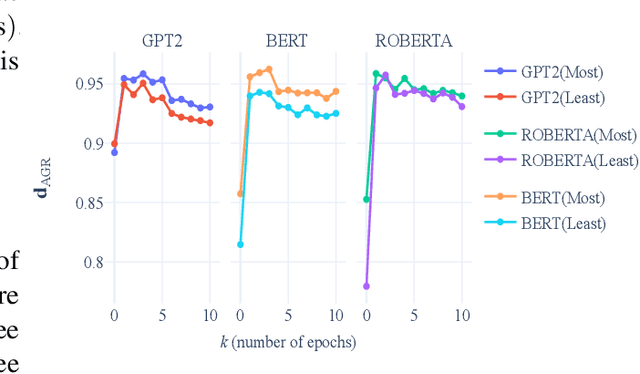
As language models continue to be integrated into applications of personal and societal relevance, ensuring these models' trustworthiness is crucial, particularly with respect to producing consistent outputs regardless of sensitive attributes. Given that first names may serve as proxies for (intersectional) socio-demographic representations, it is imperative to examine the impact of first names on commonsense reasoning capabilities. In this paper, we study whether a model's reasoning given a specific input differs based on the first names provided. Our underlying assumption is that the reasoning about Alice should not differ from the reasoning about James. We propose and implement a controlled experimental framework to measure the causal effect of first names on commonsense reasoning, enabling us to distinguish between model predictions due to chance and caused by actual factors of interest. Our results indicate that the frequency of first names has a direct effect on model prediction, with less frequent names yielding divergent predictions compared to more frequent names. To gain insights into the internal mechanisms of models that are contributing to these behaviors, we also conduct an in-depth explainable analysis. Overall, our findings suggest that to ensure model robustness, it is essential to augment datasets with more diverse first names during the configuration stage.
What Changed? Investigating Debiasing Methods using Causal Mediation Analysis
Jun 01, 2022
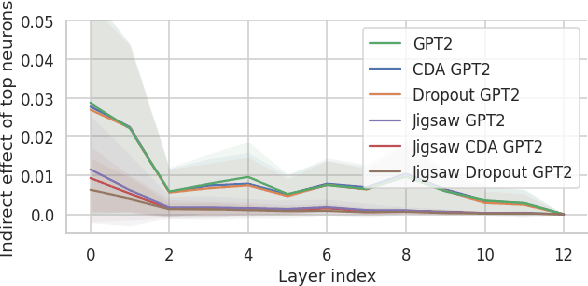
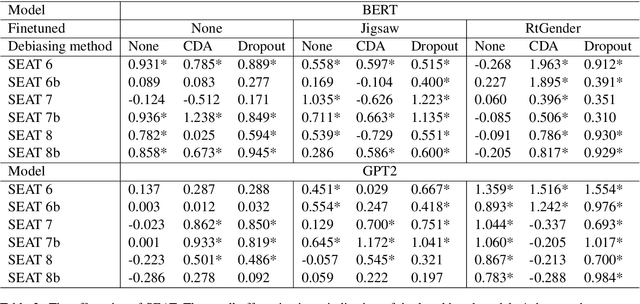
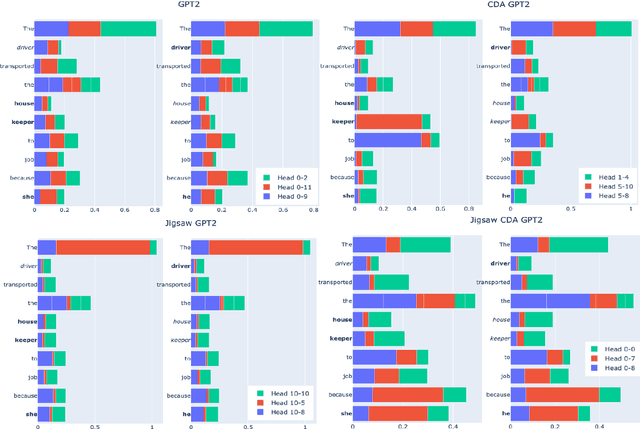
Previous work has examined how debiasing language models affect downstream tasks, specifically, how debiasing techniques influence task performance and whether debiased models also make impartial predictions in downstream tasks or not. However, what we don't understand well yet is why debiasing methods have varying impacts on downstream tasks and how debiasing techniques affect internal components of language models, i.e., neurons, layers, and attentions. In this paper, we decompose the internal mechanisms of debiasing language models with respect to gender by applying causal mediation analysis to understand the influence of debiasing methods on toxicity detection as a downstream task. Our findings suggest a need to test the effectiveness of debiasing methods with different bias metrics, and to focus on changes in the behavior of certain components of the models, e.g.,first two layers of language models, and attention heads.