 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting gender bias research in bibliometrics: Standardizing methodological variability using Scholarly Data Analysis (SoDA) Cards
Jan 30, 2025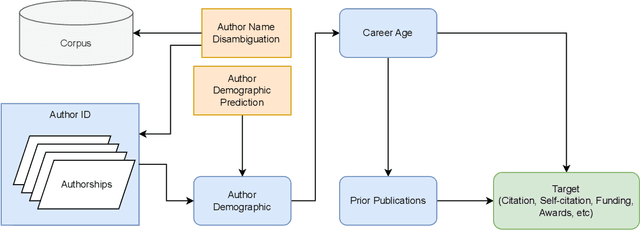



Gender biases in scholarly metrics remain a persistent concern, despite numerous bibliometric studies exploring their presence and absence across productivity, impact, acknowledgment, and self-citations. However, methodological inconsistencies, particularly in author name disambiguation and gender identification, limit the reliability and comparability of these studies, potentially perpetuating misperceptions and hindering effective interventions. A review of 70 relevant publications over the past 12 years reveals a wide range of approaches, from name-based and manual searches to more algorithmic and gold-standard methods, with no clear consensus on best practices. This variability, compounded by challenges such as accurately disambiguating Asian names and managing unassigned gender labels, underscores the urgent need for standardized and robust methodologies. To address this critical gap, we propose the development and implementation of ``Scholarly Data Analysis (SoDA) Cards." These cards will provide a structured framework for documenting and reporting key methodological choices in scholarly data analysis, including author name disambiguation and gender identification procedures. By promoting transparency and reproducibility, SoDA Cards will facilitate more accurate comparisons and aggregations of research findings, ultimately supporting evidence-informed policymaking and enabling the longitudinal tracking of analytical approaches in the study of gender and other social biases in academia.
Beyond Binary Gender Labels: Revealing Gender Biases in LLMs through Gender-Neutral Name Predictions
Jul 07, 2024Name-based gender prediction has traditionally categorized individuals as either female or male based on their names, using a binary classification system. That binary approach can be problematic in the cases of gender-neutral names that do not align with any one gender, among other reasons. Relying solely on binary gender categories without recognizing gender-neutral names can reduce the inclusiveness of gender prediction tasks. We introduce an additional gender category, i.e., "neutral", to study and address potential gender biases in Large Language Models (LLMs). We evaluate the performance of several foundational and large language models in predicting gender based on first names only. Additionally, we investigate the impact of adding birth years to enhance the accuracy of gender prediction, accounting for shifting associations between names and genders over time. Our findings indicate that most LLMs identify male and female names with high accuracy (over 80%) but struggle with gender-neutral names (under 40%), and the accuracy of gender prediction is higher for English-based first names than non-English names. The experimental results show that incorporating the birth year does not improve the overall accuracy of gender prediction, especially for names with evolving gender associations. We recommend using caution when applying LLMs for gender identification in downstream tasks, particularly when dealing with non-binary gender labels.
PyTAIL: Interactive and Incremental Learning of NLP Models with Human in the Loop for Online Data
Nov 24, 2022



Online data streams make training machine learning models hard because of distribution shift and new patterns emerging over time. For natural language processing (NLP) tasks that utilize a collection of features based on lexicons and rules, it is important to adapt these features to the changing data. To address this challenge we introduce PyTAIL, a python library, which allows a human in the loop approach to actively train NLP models. PyTAIL enhances generic active learning, which only suggests new instances to label by also suggesting new features like rules and lexicons to label. Furthermore, PyTAIL is flexible enough for users to accept, reject, or update rules and lexicons as the model is being trained. Finally, we simulate the performance of PyTAIL on existing social media benchmark datasets for text classification. We compare various active learning strategies on these benchmarks. The model closes the gap with as few as 10% of the training data. Finally, we also highlight the importance of tracking evaluation metric on remaining data (which is not yet merged with active learning) alongside the test dataset. This highlights the effectiveness of the model in accurately annotating the remaining dataset, which is especially suitable for batch processing of large unlabelled corpora. PyTAIL will be available at https://github.com/socialmediaie/pytail.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
NTULM: Enriching Social Media Text Representations with Non-Textual Units
Oct 29, 2022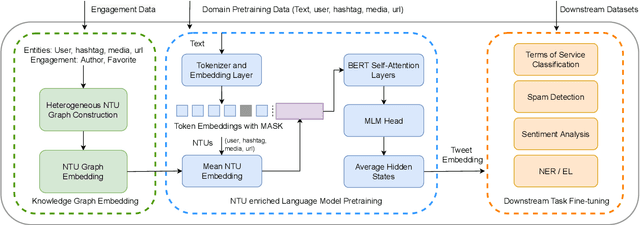

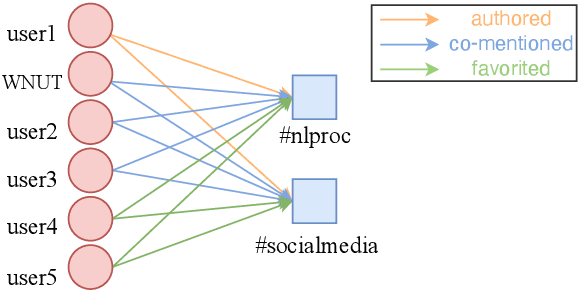
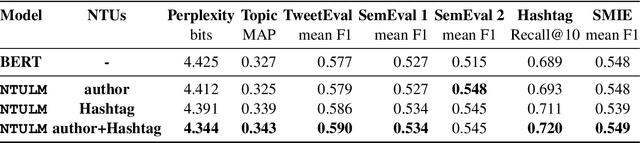
On social media, additional context is often present in the form of annotations and meta-data such as the post's author, mentions, Hashtags, and hyperlinks. We refer to these annotations as Non-Textual Units (NTUs). We posit that NTUs provide social context beyond their textual semantics and leveraging these units can enrich social media text representations. In this work we construct an NTU-centric social heterogeneous network to co-embed NTUs. We then principally integrate these NTU embeddings into a large pretrained language model by fine-tuning with these additional units. This adds context to noisy short-text social media. Experiments show that utilizing NTU-augmented text representations significantly outperforms existing text-only baselines by 2-5\% relative points on many downstream tasks highlighting the importance of context to social media NLP. We also highlight that including NTU context into the initial layers of language model alongside text is better than using it after the text embedding is generated. Our work leads to the generation of holistic general purpose social media content embedding.
TweetNERD -- End to End Entity Linking Benchmark for Tweets
Oct 14, 2022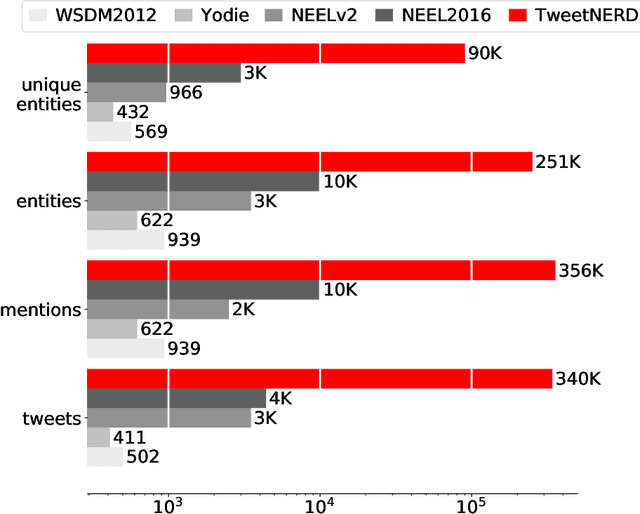


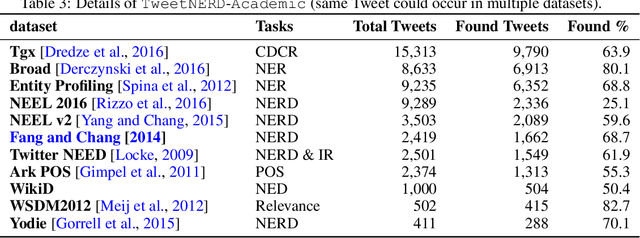
Named Entity Recognition and Disambiguation (NERD) systems are foundational for information retrieval, question answering, event detection, and other natural language processing (NLP) applications. We introduce TweetNERD, a dataset of 340K+ Tweets across 2010-2021, for benchmarking NERD systems on Tweets. This is the largest and most temporally diverse open sourced dataset benchmark for NERD on Tweets and can be used to facilitate research in this area. We describe evaluation setup with TweetNERD for three NERD tasks: Named Entity Recognition (NER), Entity Linking with True Spans (EL), and End to End Entity Linking (End2End); and provide performance of existing publicly available methods on specific TweetNERD splits. TweetNERD is available at: https://doi.org/10.5281/zenodo.6617192 under Creative Commons Attribution 4.0 International (CC BY 4.0) license. Check out more details at https://github.com/twitter-research/TweetNERD.
Robust Candidate Generation for Entity Linking on Short Social Media Texts
Oct 14, 2022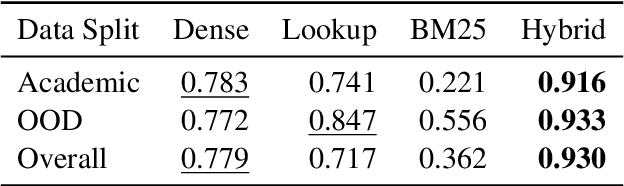
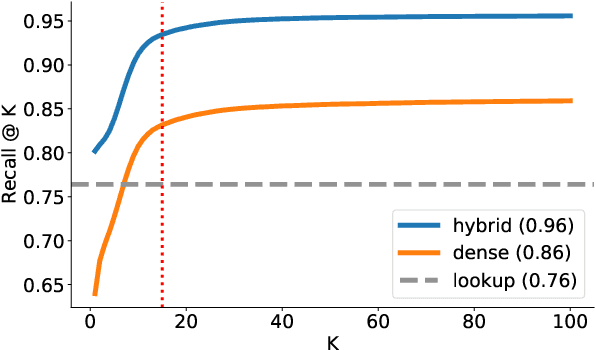
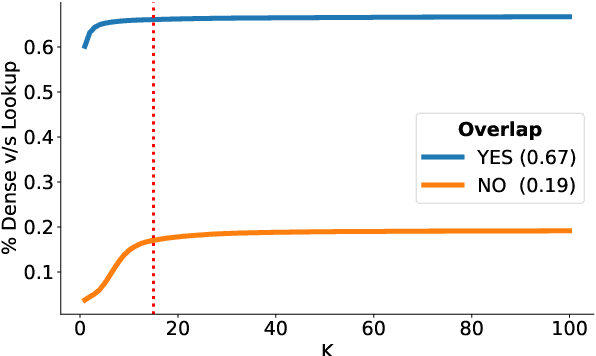
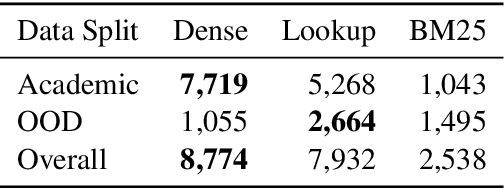
Entity Linking (EL) is the gateway into Knowledge Bases. Recent advances in EL utilize dense retrieval approaches for Candidate Generation, which addresses some of the shortcomings of the Lookup based approach of matching NER mentions against pre-computed dictionaries. In this work, we show that in the domain of Tweets, such methods suffer as users often include informal spelling, limited context, and lack of specificity, among other issues. We investigate these challenges on a large and recent Tweets benchmark for EL, empirically evaluate lookup and dense retrieval approaches, and demonstrate a hybrid solution using long contextual representation from Wikipedia is necessary to achieve considerable gains over previous work, achieving 0.93 recall.
BigBIO: A Framework for Data-Centric Biomedical Natural Language Processing
Jun 30, 2022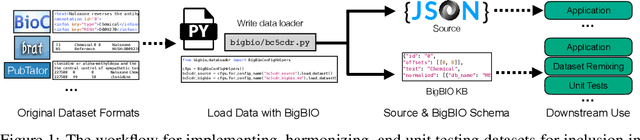
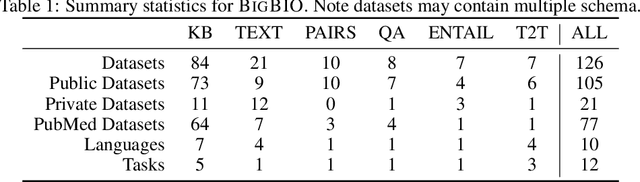

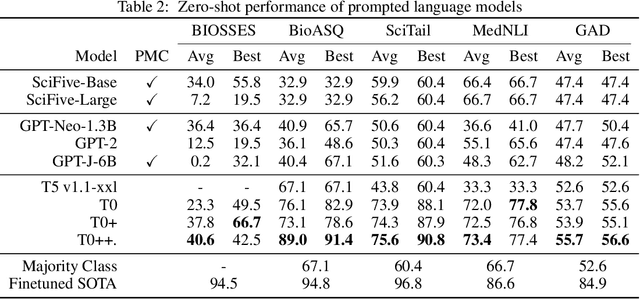
Training and evaluating language models increasingly requires the construction of meta-datasets --diverse collections of curated data with clear provenance. Natural language prompting has recently lead to improved zero-shot generalization by transforming existing, supervised datasets into a diversity of novel pretraining tasks, highlighting the benefits of meta-dataset curation. While successful in general-domain text, translating these data-centric approaches to biomedical language modeling remains challenging, as labeled biomedical datasets are significantly underrepresented in popular data hubs. To address this challenge, we introduce BigBIO a community library of 126+ biomedical NLP datasets, currently covering 12 task categories and 10+ languages. BigBIO facilitates reproducible meta-dataset curation via programmatic access to datasets and their metadata, and is compatible with current platforms for prompt engineering and end-to-end few/zero shot language model evaluation. We discuss our process for task schema harmonization, data auditing, contribution guidelines, and outline two illustrative use cases: zero-shot evaluation of biomedical prompts and large-scale, multi-task learning. BigBIO is an ongoing community effort and is available at https://github.com/bigscience-workshop/biomedical
LMSOC: An Approach for Socially Sensitive Pretraining
Oct 20, 2021

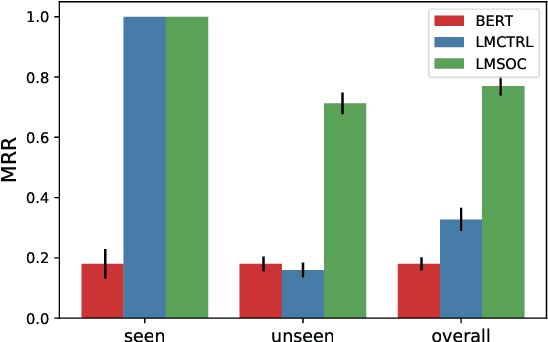

While large-scale pretrained language models have been shown to learn effective linguistic representations for many NLP tasks, there remain many real-world contextual aspects of language that current approaches do not capture. For instance, consider a cloze-test "I enjoyed the ____ game this weekend": the correct answer depends heavily on where the speaker is from, when the utterance occurred, and the speaker's broader social milieu and preferences. Although language depends heavily on the geographical, temporal, and other social contexts of the speaker, these elements have not been incorporated into modern transformer-based language models. We propose a simple but effective approach to incorporate speaker social context into the learned representations of large-scale language models. Our method first learns dense representations of social contexts using graph representation learning algorithms and then primes language model pretraining with these social context representations. We evaluate our approach on geographically-sensitive language-modeling tasks and show a substantial improvement (more than 100% relative lift on MRR) compared to baselines.
Improved Multilingual Language Model Pretraining for Social Media Text via Translation Pair Prediction
Oct 20, 2021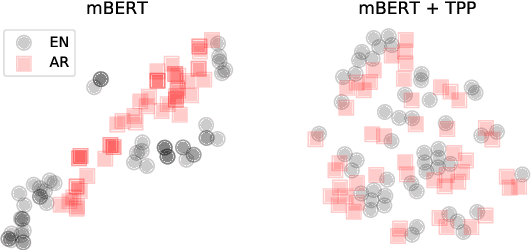
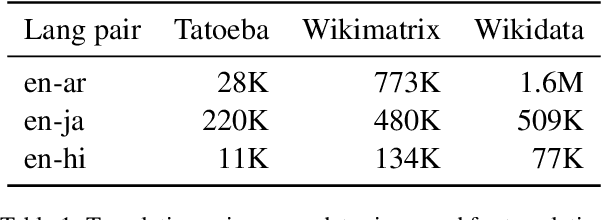
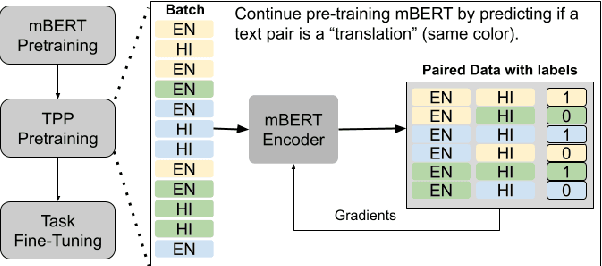
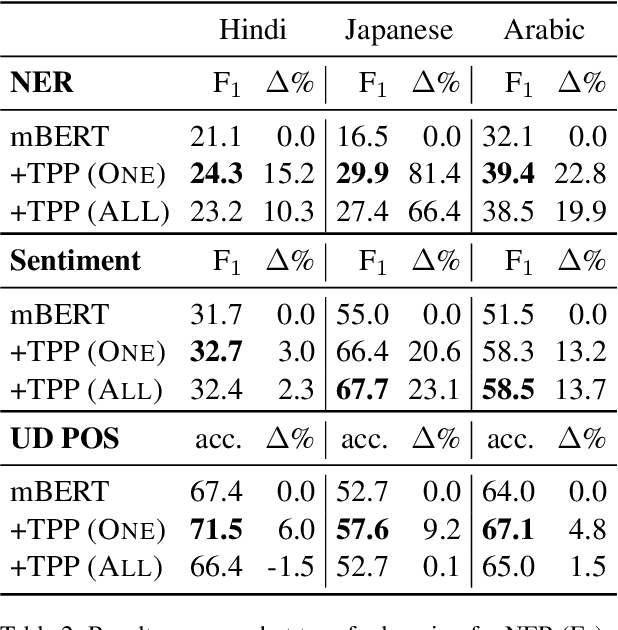
We evaluate a simple approach to improving zero-shot multilingual transfer of mBERT on social media corpus by adding a pretraining task called translation pair prediction (TPP), which predicts whether a pair of cross-lingual texts are a valid translation. Our approach assumes access to translations (exact or approximate) between source-target language pairs, where we fine-tune a model on source language task data and evaluate the model in the target language. In particular, we focus on language pairs where transfer learning is difficult for mBERT: those where source and target languages are different in script, vocabulary, and linguistic typology. We show improvements from TPP pretraining over mBERT alone in zero-shot transfer from English to Hindi, Arabic, and Japanese on two social media tasks: NER (a 37% average relative improvement in F1 across target languages) and sentiment classification (12% relative improvement in F1) on social media text, while also benchmarking on a non-social media task of Universal Dependency POS tagging (6.7% relative improvement in accuracy). Our results are promising given the lack of social media bitext corpus. Our code can be found at: https://github.com/twitter-research/multilingual-alignment-tpp.