 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeURL-BERT: Training Webpage Representations via Social Media Engagements
Oct 25, 2023



Understanding and representing webpages is crucial to online social networks where users may share and engage with URLs. Common language model (LM) encoders such as BERT can be used to understand and represent the textual content of webpages. However, these representations may not model thematic information of web domains and URLs or accurately capture their appeal to social media users. In this work, we introduce a new pre-training objective that can be used to adapt LMs to understand URLs and webpages. Our proposed framework consists of two steps: (1) scalable graph embeddings to learn shallow representations of URLs based on user engagement on social media and (2) a contrastive objective that aligns LM representations with the aforementioned graph-based representation. We apply our framework to the multilingual version of BERT to obtain the model URL-BERT. We experimentally demonstrate that our continued pre-training approach improves webpage understanding on a variety of tasks and Twitter internal and external benchmarks.
NTULM: Enriching Social Media Text Representations with Non-Textual Units
Oct 29, 2022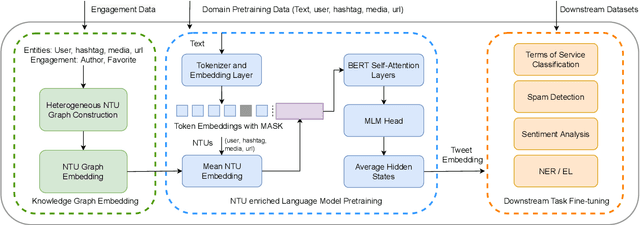

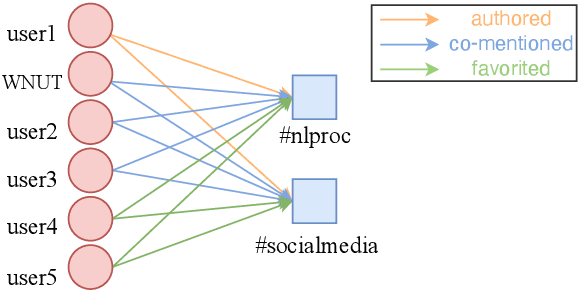
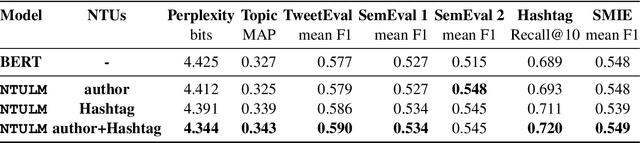
On social media, additional context is often present in the form of annotations and meta-data such as the post's author, mentions, Hashtags, and hyperlinks. We refer to these annotations as Non-Textual Units (NTUs). We posit that NTUs provide social context beyond their textual semantics and leveraging these units can enrich social media text representations. In this work we construct an NTU-centric social heterogeneous network to co-embed NTUs. We then principally integrate these NTU embeddings into a large pretrained language model by fine-tuning with these additional units. This adds context to noisy short-text social media. Experiments show that utilizing NTU-augmented text representations significantly outperforms existing text-only baselines by 2-5\% relative points on many downstream tasks highlighting the importance of context to social media NLP. We also highlight that including NTU context into the initial layers of language model alongside text is better than using it after the text embedding is generated. Our work leads to the generation of holistic general purpose social media content embedding.
TweetNERD -- End to End Entity Linking Benchmark for Tweets
Oct 14, 2022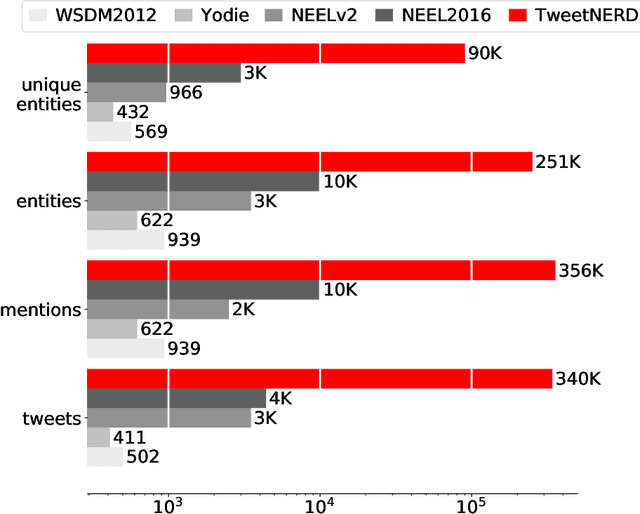


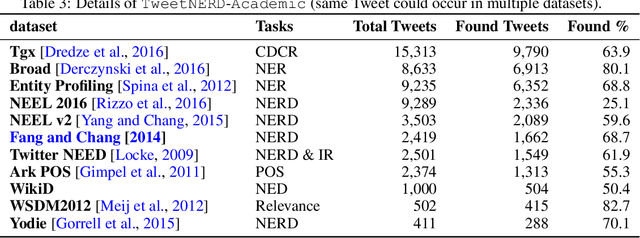
Named Entity Recognition and Disambiguation (NERD) systems are foundational for information retrieval, question answering, event detection, and other natural language processing (NLP) applications. We introduce TweetNERD, a dataset of 340K+ Tweets across 2010-2021, for benchmarking NERD systems on Tweets. This is the largest and most temporally diverse open sourced dataset benchmark for NERD on Tweets and can be used to facilitate research in this area. We describe evaluation setup with TweetNERD for three NERD tasks: Named Entity Recognition (NER), Entity Linking with True Spans (EL), and End to End Entity Linking (End2End); and provide performance of existing publicly available methods on specific TweetNERD splits. TweetNERD is available at: https://doi.org/10.5281/zenodo.6617192 under Creative Commons Attribution 4.0 International (CC BY 4.0) license. Check out more details at https://github.com/twitter-research/TweetNERD.
Improving Zero-Shot Event Extraction via Sentence Simplification
Apr 06, 2022
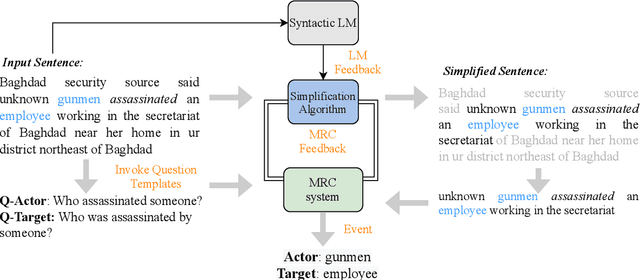
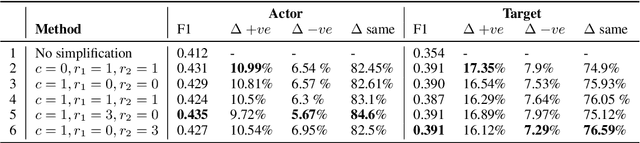

The success of sites such as ACLED and Our World in Data have demonstrated the massive utility of extracting events in structured formats from large volumes of textual data in the form of news, social media, blogs and discussion forums. Event extraction can provide a window into ongoing geopolitical crises and yield actionable intelligence. With the proliferation of large pretrained language models, Machine Reading Comprehension (MRC) has emerged as a new paradigm for event extraction in recent times. In this approach, event argument extraction is framed as an extractive question-answering task. One of the key advantages of the MRC-based approach is its ability to perform zero-shot extraction. However, the problem of long-range dependencies, i.e., large lexical distance between trigger and argument words and the difficulty of processing syntactically complex sentences plague MRC-based approaches. In this paper, we present a general approach to improve the performance of MRC-based event extraction by performing unsupervised sentence simplification guided by the MRC model itself. We evaluate our approach on the ICEWS geopolitical event extraction dataset, with specific attention to `Actor' and `Target' argument roles. We show how such context simplification can improve the performance of MRC-based event extraction by more than 5% for actor extraction and more than 10% for target extraction.
Simplify-then-Translate: Automatic Preprocessing for Black-Box Machine Translation
May 27, 2020
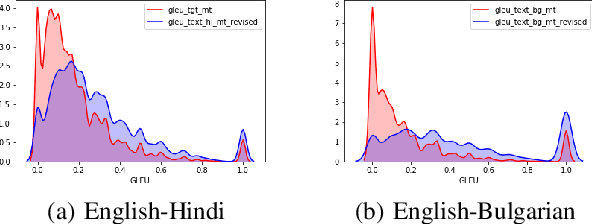

Black-box machine translation systems have proven incredibly useful for a variety of applications yet by design are hard to adapt, tune to a specific domain, or build on top of. In this work, we introduce a method to improve such systems via automatic pre-processing (APP) using sentence simplification. We first propose a method to automatically generate a large in-domain paraphrase corpus through back-translation with a black-box MT system, which is used to train a paraphrase model that "simplifies" the original sentence to be more conducive for translation. The model is used to preprocess source sentences of multiple low-resource language pairs. We show that this preprocessing leads to better translation performance as compared to non-preprocessed source sentences. We further perform side-by-side human evaluation to verify that translations of the simplified sentences are better than the original ones. Finally, we provide some guidance on recommended language pairs for generating the simplification model corpora by investigating the relationship between ease of translation of a language pair (as measured by BLEU) and quality of the resulting simplification model from back-translations of this language pair (as measured by SARI), and tie this into the downstream task of low-resource translation.
Low Rank Factorization for Compact Multi-Head Self-Attention
Nov 26, 2019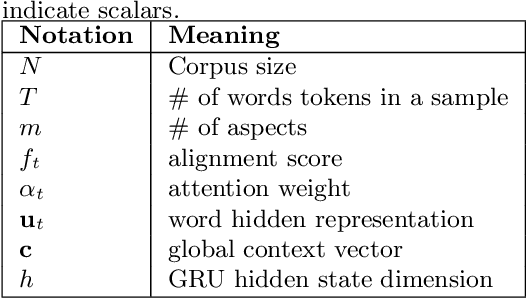
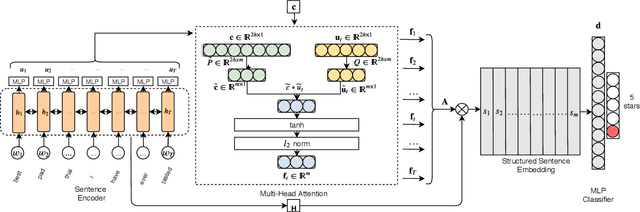
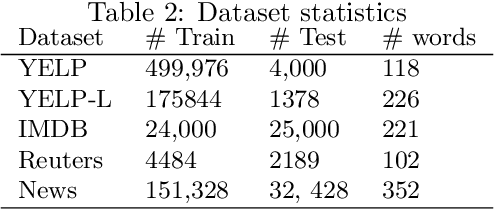
Effective representation learning from text has been an active area of research in the fields of NLP and text mining. Attention mechanisms have been at the forefront in order to learn contextual sentence representations. Current state-of-art approaches in representation learning use single-head and multi-head attention mechanisms to learn context-aware representations. However, these approaches can be largely parameter intensive resulting in low-resource bottlenecks. In this work we present a novel multi-head attention mechanism that uses low-rank bilinear pooling to efficiently construct a structured sentence representation that attends to multiple aspects of a sentence. We show that the proposed model is more effeffective than single-head attention mechanisms and is also more parameter efficient and faster to compute than existing multi-head approaches. We evaluate the performance of the proposed model on multiple datasets on two text classification benchmarks including: (i) Sentiment Analysis and (ii) News classification.