 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
TweetNERD -- End to End Entity Linking Benchmark for Tweets
Oct 14, 2022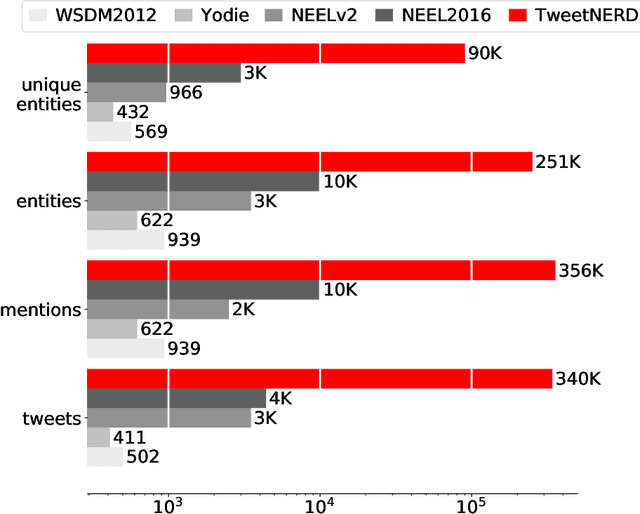


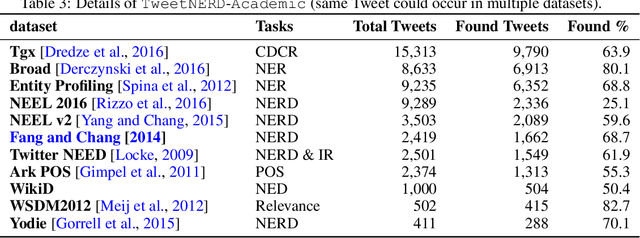
Named Entity Recognition and Disambiguation (NERD) systems are foundational for information retrieval, question answering, event detection, and other natural language processing (NLP) applications. We introduce TweetNERD, a dataset of 340K+ Tweets across 2010-2021, for benchmarking NERD systems on Tweets. This is the largest and most temporally diverse open sourced dataset benchmark for NERD on Tweets and can be used to facilitate research in this area. We describe evaluation setup with TweetNERD for three NERD tasks: Named Entity Recognition (NER), Entity Linking with True Spans (EL), and End to End Entity Linking (End2End); and provide performance of existing publicly available methods on specific TweetNERD splits. TweetNERD is available at: https://doi.org/10.5281/zenodo.6617192 under Creative Commons Attribution 4.0 International (CC BY 4.0) license. Check out more details at https://github.com/twitter-research/TweetNERD.
kNN-Embed: Locally Smoothed Embedding Mixtures For Multi-interest Candidate Retrieval
May 13, 2022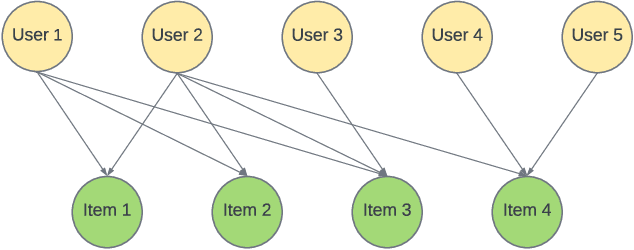

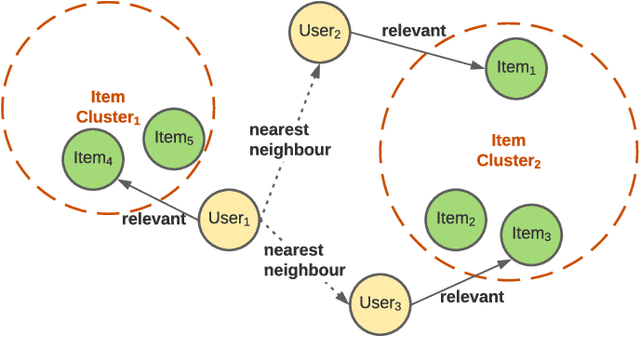
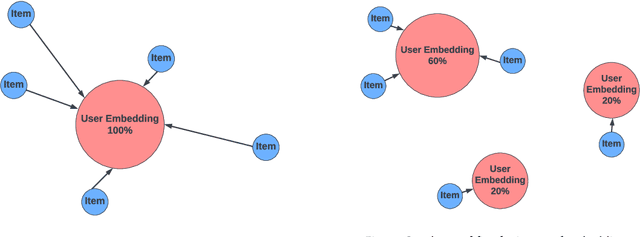
Candidate generation is the first stage in recommendation systems, where a light-weight system is used to retrieve potentially relevant items for an input user. These candidate items are then ranked and pruned in later stages of recommender systems using a more complex ranking model. Since candidate generation is the top of the recommendation funnel, it is important to retrieve a high-recall candidate set to feed into downstream ranking models. A common approach for candidate generation is to leverage approximate nearest neighbor (ANN) search from a single dense query embedding; however, this approach this can yield a low-diversity result set with many near duplicates. As users often have multiple interests, candidate retrieval should ideally return a diverse set of candidates reflective of the user's multiple interests. To this end, we introduce kNN-Embed, a general approach to improving diversity in dense ANN-based retrieval. kNN-Embed represents each user as a smoothed mixture over learned item clusters that represent distinct `interests' of the user. By querying each of a user's mixture component in proportion to their mixture weights, we retrieve a high-diversity set of candidates reflecting elements from each of a user's interests. We experimentally compare kNN-Embed to standard ANN candidate retrieval, and show significant improvements in overall recall and improved diversity across three datasets. Accompanying this work, we open source a large Twitter follow-graph dataset, to spur further research in graph-mining and representation learning for recommender systems.
CTM -- A Model for Large-Scale Multi-View Tweet Topic Classification
May 03, 2022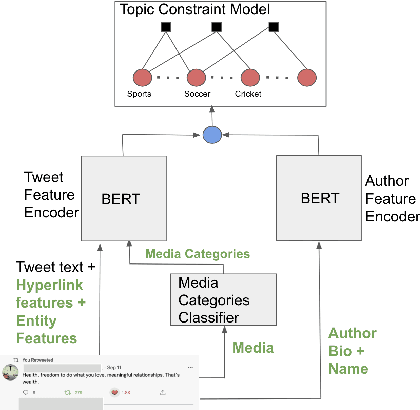

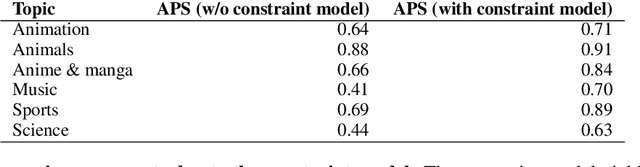

Automatically associating social media posts with topics is an important prerequisite for effective search and recommendation on many social media platforms. However, topic classification of such posts is quite challenging because of (a) a large topic space (b) short text with weak topical cues, and (c) multiple topic associations per post. In contrast to most prior work which only focuses on post classification into a small number of topics ($10$-$20$), we consider the task of large-scale topic classification in the context of Twitter where the topic space is $10$ times larger with potentially multiple topic associations per Tweet. We address the challenges above by proposing a novel neural model, CTM that (a) supports a large topic space of $300$ topics and (b) takes a holistic approach to tweet content modeling -- leveraging multi-modal content, author context, and deeper semantic cues in the Tweet. Our method offers an effective way to classify Tweets into topics at scale by yielding superior performance to other approaches (a relative lift of $\mathbf{20}\%$ in median average precision score) and has been successfully deployed in production at Twitter.
Learning Stance Embeddings from Signed Social Graphs
Jan 27, 2022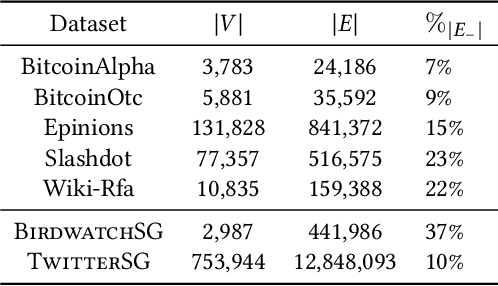
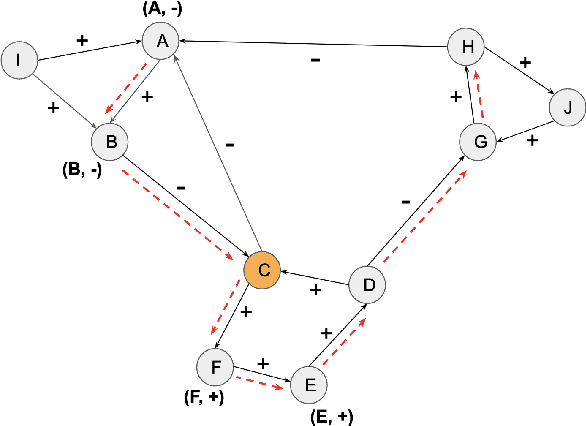
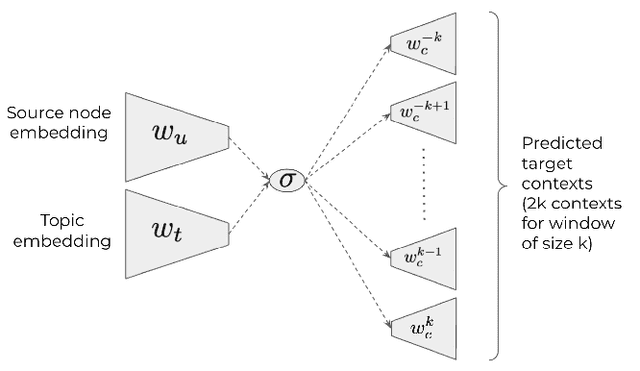
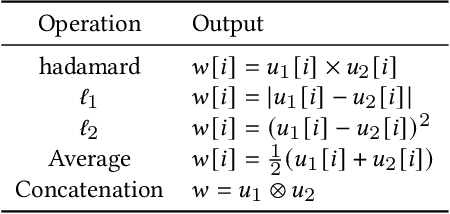
A key challenge in social network analysis is understanding the position, or stance, of people in the graph on a large set of topics. While past work has modeled (dis)agreement in social networks using signed graphs, these approaches have not modeled agreement patterns across a range of correlated topics. For instance, disagreement on one topic may make disagreement(or agreement) more likely for related topics. We propose the Stance Embeddings Model(SEM), which jointly learns embeddings for each user and topic in signed social graphs with distinct edge types for each topic. By jointly learning user and topic embeddings, SEM is able to perform cold-start topic stance detection, predicting the stance of a user on topics for which we have not observed their engagement. We demonstrate the effectiveness of SEM using two large-scale Twitter signed graph datasets we open-source. One dataset, TwitterSG, labels (dis)agreements using engagements between users via tweets to derive topic-informed, signed edges. The other, BirdwatchSG, leverages community reports on misinformation and misleading content. On TwitterSG and BirdwatchSG, SEM shows a 39% and 26% error reduction respectively against strong baselines.
LMSOC: An Approach for Socially Sensitive Pretraining
Oct 20, 2021

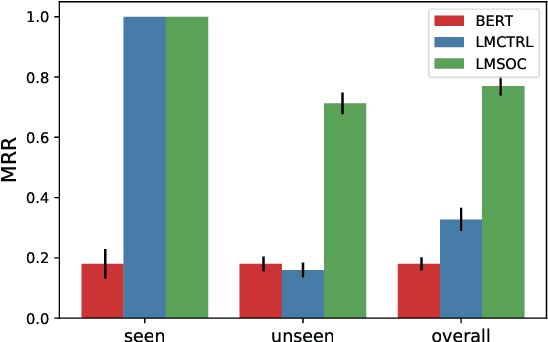

While large-scale pretrained language models have been shown to learn effective linguistic representations for many NLP tasks, there remain many real-world contextual aspects of language that current approaches do not capture. For instance, consider a cloze-test "I enjoyed the ____ game this weekend": the correct answer depends heavily on where the speaker is from, when the utterance occurred, and the speaker's broader social milieu and preferences. Although language depends heavily on the geographical, temporal, and other social contexts of the speaker, these elements have not been incorporated into modern transformer-based language models. We propose a simple but effective approach to incorporate speaker social context into the learned representations of large-scale language models. Our method first learns dense representations of social contexts using graph representation learning algorithms and then primes language model pretraining with these social context representations. We evaluate our approach on geographically-sensitive language-modeling tasks and show a substantial improvement (more than 100% relative lift on MRR) compared to baselines.
Improved Multilingual Language Model Pretraining for Social Media Text via Translation Pair Prediction
Oct 20, 2021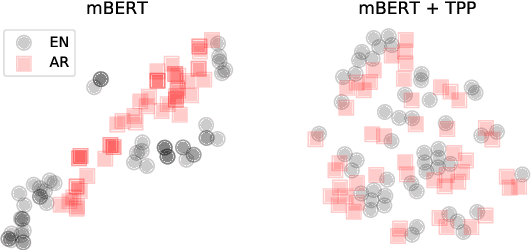
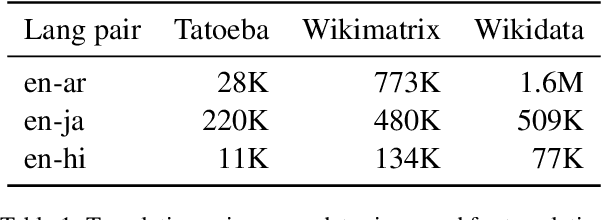
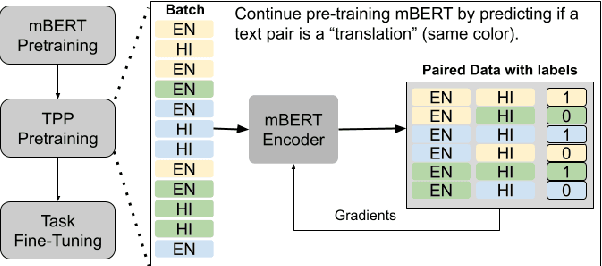
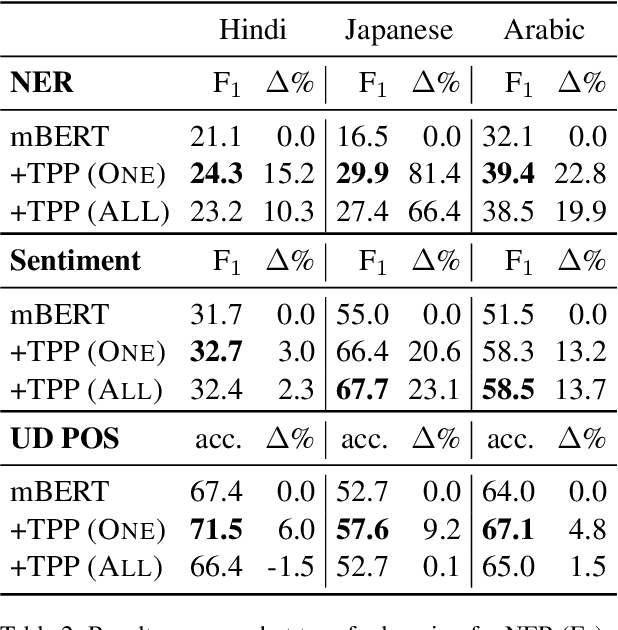
We evaluate a simple approach to improving zero-shot multilingual transfer of mBERT on social media corpus by adding a pretraining task called translation pair prediction (TPP), which predicts whether a pair of cross-lingual texts are a valid translation. Our approach assumes access to translations (exact or approximate) between source-target language pairs, where we fine-tune a model on source language task data and evaluate the model in the target language. In particular, we focus on language pairs where transfer learning is difficult for mBERT: those where source and target languages are different in script, vocabulary, and linguistic typology. We show improvements from TPP pretraining over mBERT alone in zero-shot transfer from English to Hindi, Arabic, and Japanese on two social media tasks: NER (a 37% average relative improvement in F1 across target languages) and sentiment classification (12% relative improvement in F1) on social media text, while also benchmarking on a non-social media task of Universal Dependency POS tagging (6.7% relative improvement in accuracy). Our results are promising given the lack of social media bitext corpus. Our code can be found at: https://github.com/twitter-research/multilingual-alignment-tpp.