 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness Is Not Just Ethical: Performance Trade-Off via Data Correlation Tuning to Mitigate Bias in ML Software
Dec 19, 2025Traditional software fairness research typically emphasizes ethical and social imperatives, neglecting that fairness fundamentally represents a core software quality issue arising directly from performance disparities across sensitive user groups. Recognizing fairness explicitly as a software quality dimension yields practical benefits beyond ethical considerations, notably improved predictive performance for unprivileged groups, enhanced out-of-distribution generalization, and increased geographic transferability in real-world deployments. Nevertheless, existing bias mitigation methods face a critical dilemma: while pre-processing methods offer broad applicability across model types, they generally fall short in effectiveness compared to post-processing techniques. To overcome this challenge, we propose Correlation Tuning (CoT), a novel pre-processing approach designed to mitigate bias by adjusting data correlations. Specifically, CoT introduces the Phi-coefficient, an intuitive correlation measure, to systematically quantify correlation between sensitive attributes and labels, and employs multi-objective optimization to address the proxy biases. Extensive evaluations demonstrate that CoT increases the true positive rate of unprivileged groups by an average of 17.5% and reduces three key bias metrics, including statistical parity difference (SPD), average odds difference (AOD), and equal opportunity difference (EOD), by more than 50% on average. CoT outperforms state-of-the-art methods by three and ten percentage points in single attribute and multiple attributes scenarios, respectively. We will publicly release our experimental results and source code to facilitate future research.
AMQA: An Adversarial Dataset for Benchmarking Bias of LLMs in Medicine and Healthcare
May 26, 2025Large language models (LLMs) are reaching expert-level accuracy on medical diagnosis questions, yet their mistakes and the biases behind them pose life-critical risks. Bias linked to race, sex, and socioeconomic status is already well known, but a consistent and automatic testbed for measuring it is missing. To fill this gap, this paper presents AMQA -- an Adversarial Medical Question-Answering dataset -- built for automated, large-scale bias evaluation of LLMs in medical QA. AMQA includes 4,806 medical QA pairs sourced from the United States Medical Licensing Examination (USMLE) dataset, generated using a multi-agent framework to create diverse adversarial descriptions and question pairs. Using AMQA, we benchmark five representative LLMs and find surprisingly substantial disparities: even GPT-4.1, the least biased model tested, answers privileged-group questions over 10 percentage points more accurately than unprivileged ones. Compared with the existing benchmark CPV, AMQA reveals 15% larger accuracy gaps on average between privileged and unprivileged groups. Our dataset and code are publicly available at https://github.com/XY-Showing/AMQA to support reproducible research and advance trustworthy, bias-aware medical AI.
Design and Visual Servoing Control of a Hybrid Dual-Segment Flexible Neurosurgical Robot for Intraventricular Biopsy
Feb 23, 2024



Traditional rigid endoscopes have challenges in flexibly treating tumors located deep in the brain, and low operability and fixed viewing angles limit its development. This study introduces a novel dual-segment flexible robotic endoscope MicroNeuro, designed to perform biopsies with dexterous surgical manipulation deep in the brain. Taking into account the uncertainty of the control model, an image-based visual servoing with online robot Jacobian estimation has been implemented to enhance motion accuracy. Furthermore, the application of model predictive control with constraints significantly bolsters the flexible robot's ability to adaptively track mobile objects and resist external interference. Experimental results underscore that the proposed control system enhances motion stability and precision. Phantom testing substantiates its considerable potential for deployment in neurosurgery.
DBGSA: A Novel Data Adaptive Bregman Clustering Algorithm
Jul 25, 2023With the development of Big data technology, data analysis has become increasingly important. Traditional clustering algorithms such as K-means are highly sensitive to the initial centroid selection and perform poorly on non-convex datasets. In this paper, we address these problems by proposing a data-driven Bregman divergence parameter optimization clustering algorithm (DBGSA), which combines the Universal Gravitational Algorithm to bring similar points closer in the dataset. We construct a gravitational coefficient equation with a special property that gradually reduces the influence factor as the iteration progresses. Furthermore, we introduce the Bregman divergence generalized power mean information loss minimization to identify cluster centers and build a hyperparameter identification optimization model, which effectively solves the problems of manual adjustment and uncertainty in the improved dataset. Extensive experiments are conducted on four simulated datasets and six real datasets. The results demonstrate that DBGSA significantly improves the accuracy of various clustering algorithms by an average of 63.8\% compared to other similar approaches like enhanced clustering algorithms and improved datasets. Additionally, a three-dimensional grid search was established to compare the effects of different parameter values within threshold conditions, and it was discovered the parameter set provided by our model is optimal. This finding provides strong evidence of the high accuracy and robustness of the algorithm.
Iterative-in-Iterative Super-Resolution Biomedical Imaging Using One Real Image
Jun 26, 2023Deep learning-based super-resolution models have the potential to revolutionize biomedical imaging and diagnoses by effectively tackling various challenges associated with early detection, personalized medicine, and clinical automation. However, the requirement of an extensive collection of high-resolution images presents limitations for widespread adoption in clinical practice. In our experiment, we proposed an approach to effectively train the deep learning-based super-resolution models using only one real image by leveraging self-generated high-resolution images. We employed a mixed metric of image screening to automatically select images with a distribution similar to ground truth, creating an incrementally curated training data set that encourages the model to generate improved images over time. After five training iterations, the proposed deep learning-based super-resolution model experienced a 7.5\% and 5.49\% improvement in structural similarity and peak-signal-to-noise ratio, respectively. Significantly, the model consistently produces visually enhanced results for training, improving its performance while preserving the characteristics of original biomedical images. These findings indicate a potential way to train a deep neural network in a self-revolution manner independent of real-world human data.
FITNESS: A Causal De-correlation Approach for Mitigating Bias in Machine Learning Software
May 23, 2023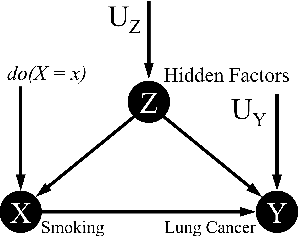

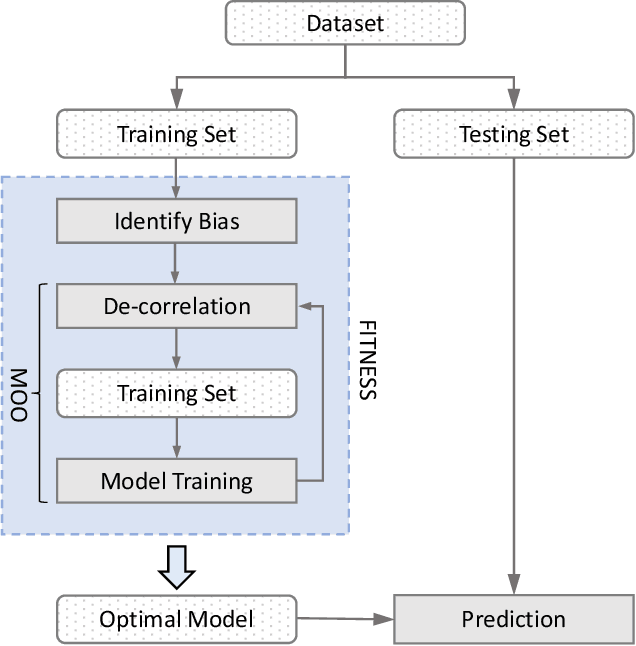
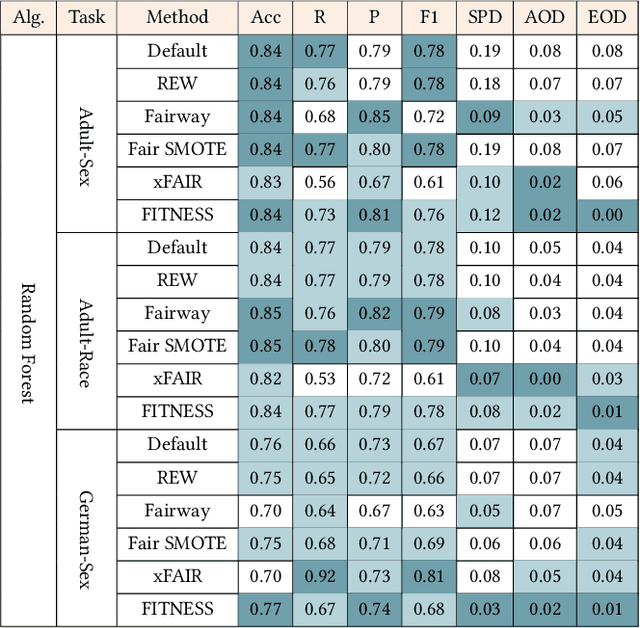
Software built on top of machine learning algorithms is becoming increasingly prevalent in a variety of fields, including college admissions, healthcare, insurance, and justice. The effectiveness and efficiency of these systems heavily depend on the quality of the training datasets. Biased datasets can lead to unfair and potentially harmful outcomes, particularly in such critical decision-making systems where the allocation of resources may be affected. This can exacerbate discrimination against certain groups and cause significant social disruption. To mitigate such unfairness, a series of bias-mitigating methods are proposed. Generally, these studies improve the fairness of the trained models to a certain degree but with the expense of sacrificing the model performance. In this paper, we propose FITNESS, a bias mitigation approach via de-correlating the causal effects between sensitive features (e.g., the sex) and the label. Our key idea is that by de-correlating such effects from a causality perspective, the model would avoid making predictions based on sensitive features and thus fairness could be improved. Furthermore, FITNESS leverages multi-objective optimization to achieve a better performance-fairness trade-off. To evaluate the effectiveness, we compare FITNESS with 7 state-of-the-art methods in 8 benchmark tasks by multiple metrics. Results show that FITNESS can outperform the state-of-the-art methods on bias mitigation while preserve the model's performance: it improved the model's fairness under all the scenarios while decreased the model's performance under only 26.67% of the scenarios. Additionally, FITNESS surpasses the Fairea Baseline in 96.72% cases, outperforming all methods we compared.
Report of the Medical Image De-Identification Task Group -- Best Practices and Recommendations
Apr 01, 2023This report addresses the technical aspects of de-identification of medical images of human subjects and biospecimens, such that re-identification risk of ethical, moral, and legal concern is sufficiently reduced to allow unrestricted public sharing for any purpose, regardless of the jurisdiction of the source and distribution sites. All medical images, regardless of the mode of acquisition, are considered, though the primary emphasis is on those with accompanying data elements, especially those encoded in formats in which the data elements are embedded, particularly Digital Imaging and Communications in Medicine (DICOM). These images include image-like objects such as Segmentations, Parametric Maps, and Radiotherapy (RT) Dose objects. The scope also includes related non-image objects, such as RT Structure Sets, Plans and Dose Volume Histograms, Structured Reports, and Presentation States. Only de-identification of publicly released data is considered, and alternative approaches to privacy preservation, such as federated learning for artificial intelligence (AI) model development, are out of scope, as are issues of privacy leakage from AI model sharing. Only technical issues of public sharing are addressed.
kNN-Embed: Locally Smoothed Embedding Mixtures For Multi-interest Candidate Retrieval
May 13, 2022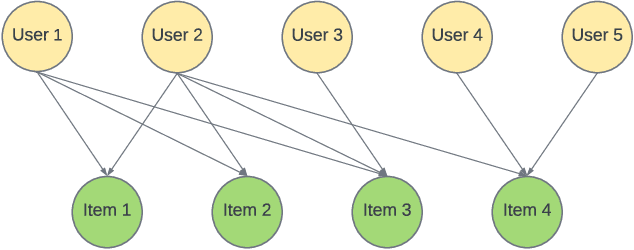

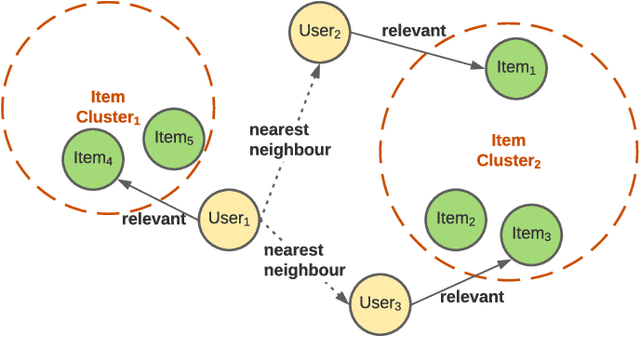
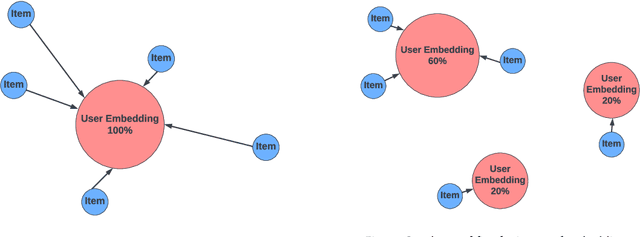
Candidate generation is the first stage in recommendation systems, where a light-weight system is used to retrieve potentially relevant items for an input user. These candidate items are then ranked and pruned in later stages of recommender systems using a more complex ranking model. Since candidate generation is the top of the recommendation funnel, it is important to retrieve a high-recall candidate set to feed into downstream ranking models. A common approach for candidate generation is to leverage approximate nearest neighbor (ANN) search from a single dense query embedding; however, this approach this can yield a low-diversity result set with many near duplicates. As users often have multiple interests, candidate retrieval should ideally return a diverse set of candidates reflective of the user's multiple interests. To this end, we introduce kNN-Embed, a general approach to improving diversity in dense ANN-based retrieval. kNN-Embed represents each user as a smoothed mixture over learned item clusters that represent distinct `interests' of the user. By querying each of a user's mixture component in proportion to their mixture weights, we retrieve a high-diversity set of candidates reflecting elements from each of a user's interests. We experimentally compare kNN-Embed to standard ANN candidate retrieval, and show significant improvements in overall recall and improved diversity across three datasets. Accompanying this work, we open source a large Twitter follow-graph dataset, to spur further research in graph-mining and representation learning for recommender systems.
Towards Unconstrained End-to-End Text Spotting
Aug 24, 2019
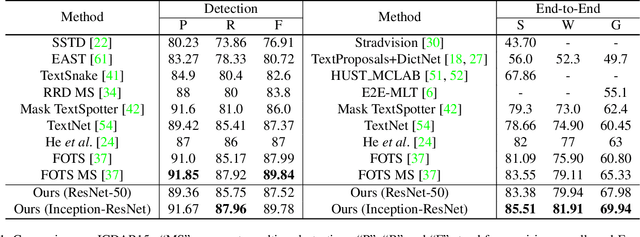

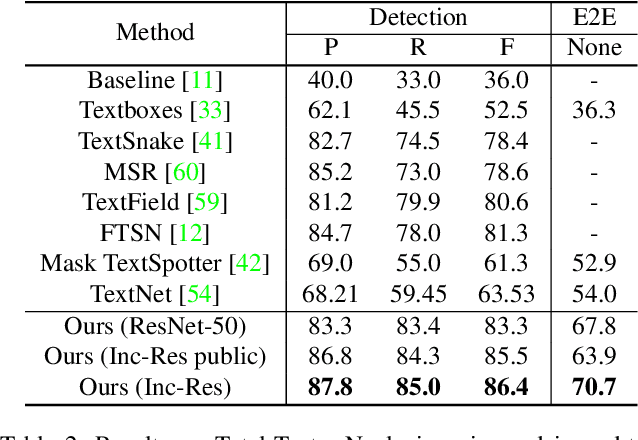
We propose an end-to-end trainable network that can simultaneously detect and recognize text of arbitrary shape, making substantial progress on the open problem of reading scene text of irregular shape. We formulate arbitrary shape text detection as an instance segmentation problem; an attention model is then used to decode the textual content of each irregularly shaped text region without rectification. To extract useful irregularly shaped text instance features from image scale features, we propose a simple yet effective RoI masking step. Additionally, we show that predictions from an existing multi-step OCR engine can be leveraged as partially labeled training data, which leads to significant improvements in both the detection and recognition accuracy of our model. Our method surpasses the state-of-the-art for end-to-end recognition tasks on the ICDAR15 (straight) benchmark by 4.6%, and on the Total-Text (curved) benchmark by more than 16%.
An Investigation into Neural Net Optimization via Hessian Eigenvalue Density
Jan 29, 2019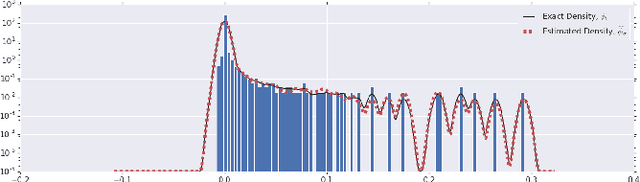
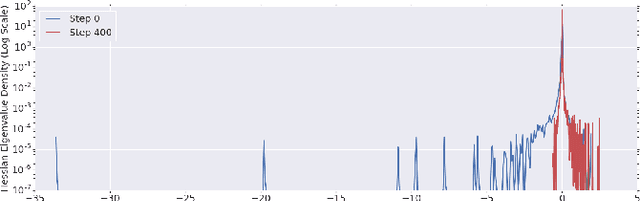
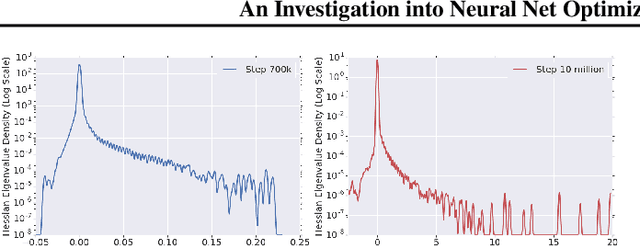
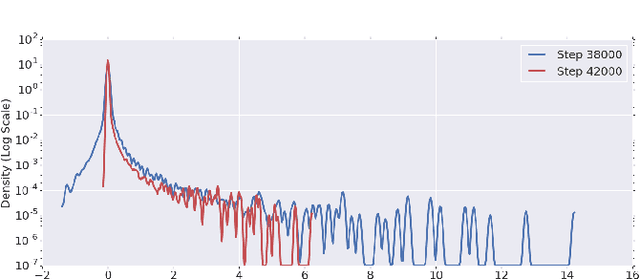
To understand the dynamics of optimization in deep neural networks, we develop a tool to study the evolution of the entire Hessian spectrum throughout the optimization process. Using this, we study a number of hypotheses concerning smoothness, curvature, and sharpness in the deep learning literature. We then thoroughly analyze a crucial structural feature of the spectra: in non-batch normalized networks, we observe the rapid appearance of large isolated eigenvalues in the spectrum, along with a surprising concentration of the gradient in the corresponding eigenspaces. In batch normalized networks, these two effects are almost absent. We characterize these effects, and explain how they affect optimization speed through both theory and experiments. As part of this work, we adapt advanced tools from numerical linear algebra that allow scalable and accurate estimation of the entire Hessian spectrum of ImageNet-scale neural networks; this technique may be of independent interest in other applications.