 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgekNN-Embed: Locally Smoothed Embedding Mixtures For Multi-interest Candidate Retrieval
May 13, 2022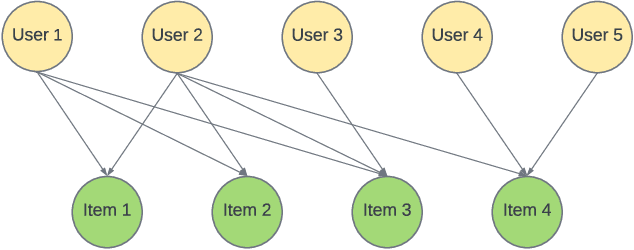

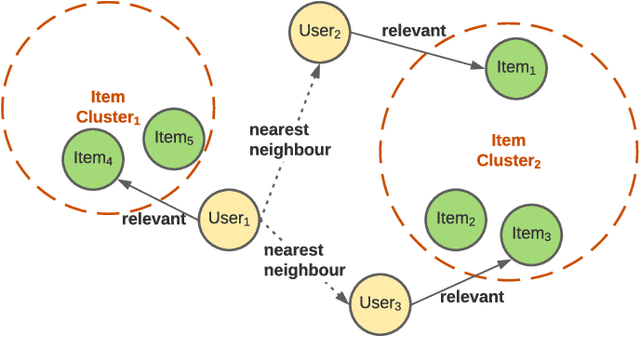
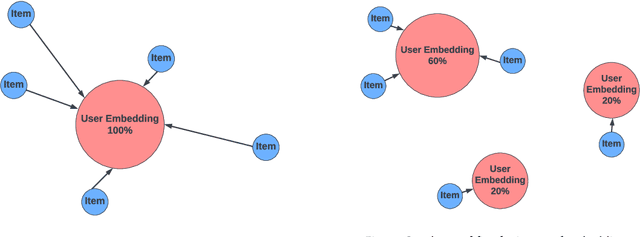
Candidate generation is the first stage in recommendation systems, where a light-weight system is used to retrieve potentially relevant items for an input user. These candidate items are then ranked and pruned in later stages of recommender systems using a more complex ranking model. Since candidate generation is the top of the recommendation funnel, it is important to retrieve a high-recall candidate set to feed into downstream ranking models. A common approach for candidate generation is to leverage approximate nearest neighbor (ANN) search from a single dense query embedding; however, this approach this can yield a low-diversity result set with many near duplicates. As users often have multiple interests, candidate retrieval should ideally return a diverse set of candidates reflective of the user's multiple interests. To this end, we introduce kNN-Embed, a general approach to improving diversity in dense ANN-based retrieval. kNN-Embed represents each user as a smoothed mixture over learned item clusters that represent distinct `interests' of the user. By querying each of a user's mixture component in proportion to their mixture weights, we retrieve a high-diversity set of candidates reflecting elements from each of a user's interests. We experimentally compare kNN-Embed to standard ANN candidate retrieval, and show significant improvements in overall recall and improved diversity across three datasets. Accompanying this work, we open source a large Twitter follow-graph dataset, to spur further research in graph-mining and representation learning for recommender systems.
CTM -- A Model for Large-Scale Multi-View Tweet Topic Classification
May 03, 2022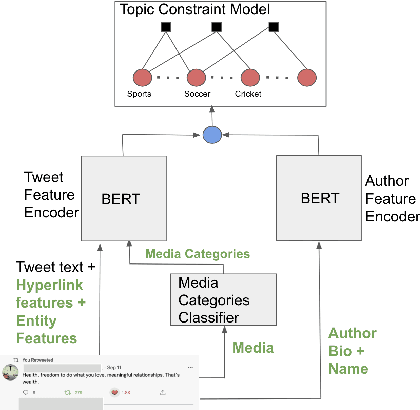

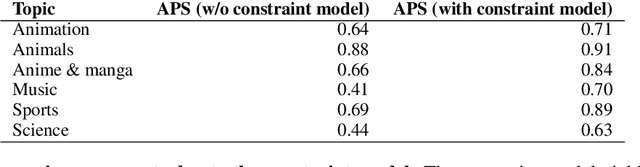

Automatically associating social media posts with topics is an important prerequisite for effective search and recommendation on many social media platforms. However, topic classification of such posts is quite challenging because of (a) a large topic space (b) short text with weak topical cues, and (c) multiple topic associations per post. In contrast to most prior work which only focuses on post classification into a small number of topics ($10$-$20$), we consider the task of large-scale topic classification in the context of Twitter where the topic space is $10$ times larger with potentially multiple topic associations per Tweet. We address the challenges above by proposing a novel neural model, CTM that (a) supports a large topic space of $300$ topics and (b) takes a holistic approach to tweet content modeling -- leveraging multi-modal content, author context, and deeper semantic cues in the Tweet. Our method offers an effective way to classify Tweets into topics at scale by yielding superior performance to other approaches (a relative lift of $\mathbf{20}\%$ in median average precision score) and has been successfully deployed in production at Twitter.