 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLINKX: A Scalable Unified Framework For Homophilous and Heterophilous Graphs
Nov 19, 2022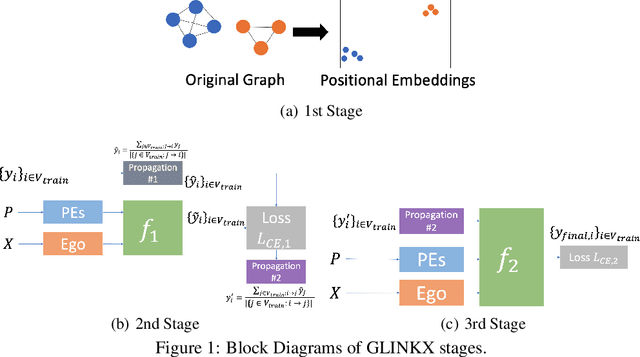



In graph learning, there have been two predominant inductive biases regarding graph-inspired architectures: On the one hand, higher-order interactions and message passing work well on homophilous graphs and are leveraged by GCNs and GATs. Such architectures, however, cannot easily scale to large real-world graphs. On the other hand, shallow (or node-level) models using ego features and adjacency embeddings work well in heterophilous graphs. In this work, we propose a novel scalable shallow method -- GLINKX -- that can work both on homophilous and heterophilous graphs. GLINKX leverages (i) novel monophilous label propagations, (ii) ego/node features, (iii) knowledge graph embeddings as positional embeddings, (iv) node-level training, and (v) low-dimensional message passing. Formally, we prove novel error bounds and justify the components of GLINKX. Experimentally, we show its effectiveness on several homophilous and heterophilous datasets.
MiCRO: Multi-interest Candidate Retrieval Online
Oct 28, 2022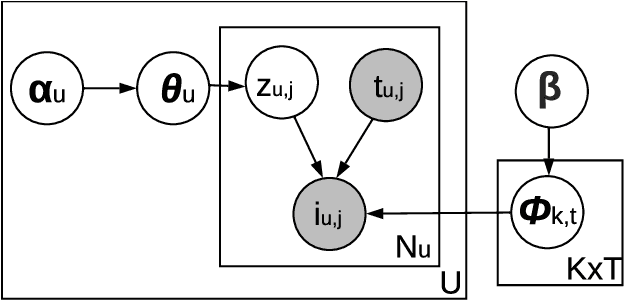
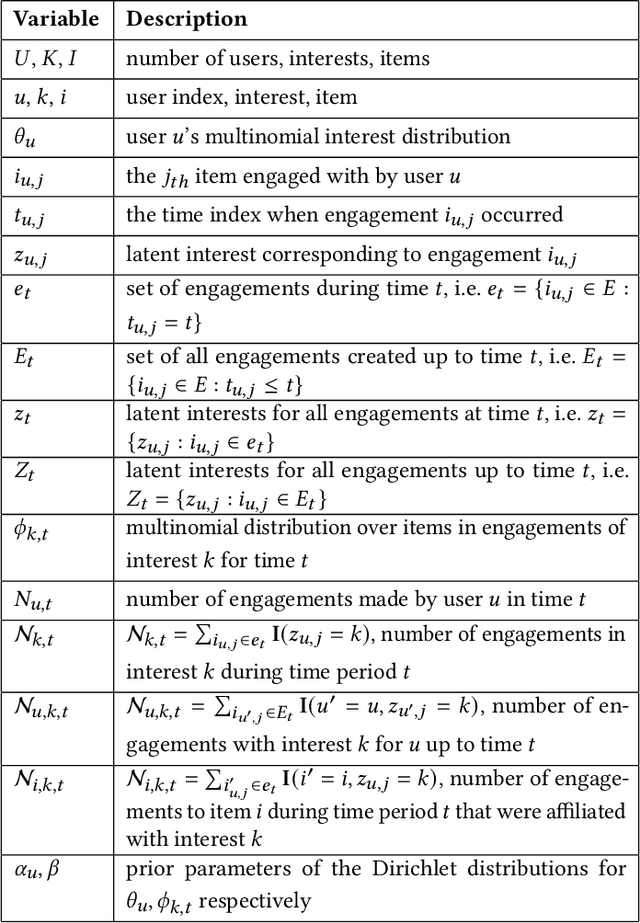
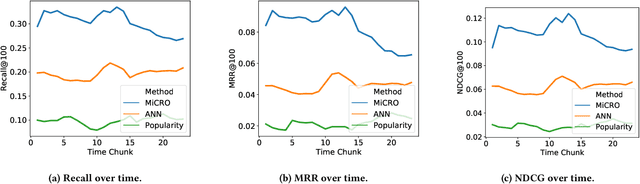
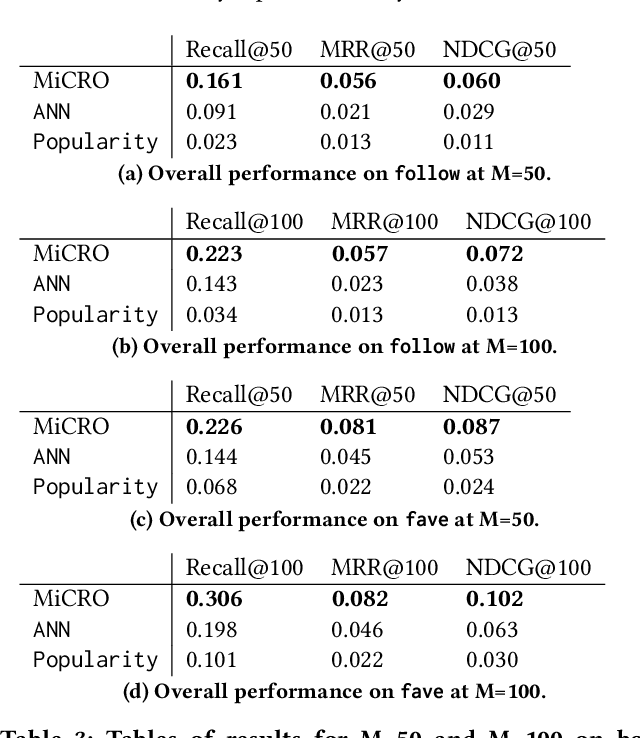
Providing personalized recommendations in an environment where items exhibit ephemerality and temporal relevancy (e.g. in social media) presents a few unique challenges: (1) inductively understanding ephemeral appeal for items in a setting where new items are created frequently, (2) adapting to trends within engagement patterns where items may undergo temporal shifts in relevance, (3) accurately modeling user preferences over this item space where users may express multiple interests. In this work we introduce MiCRO, a generative statistical framework that models multi-interest user preferences and temporal multi-interest item representations. Our framework is specifically formulated to adapt to both new items and temporal patterns of engagement. MiCRO demonstrates strong empirical performance on candidate retrieval experiments performed on two large scale user-item datasets: (1) an open-source temporal dataset of (User, User) follow interactions and (2) a temporal dataset of (User, Tweet) favorite interactions which we will open-source as an additional contribution to the community.
kNN-Embed: Locally Smoothed Embedding Mixtures For Multi-interest Candidate Retrieval
May 13, 2022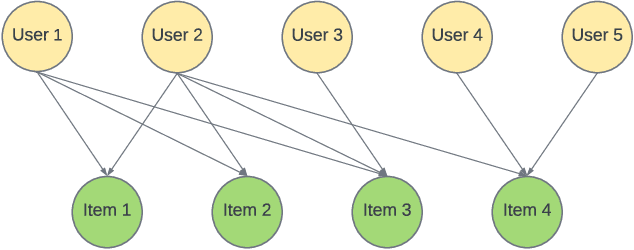

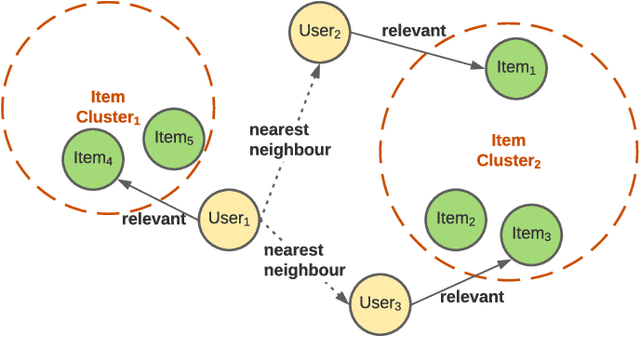
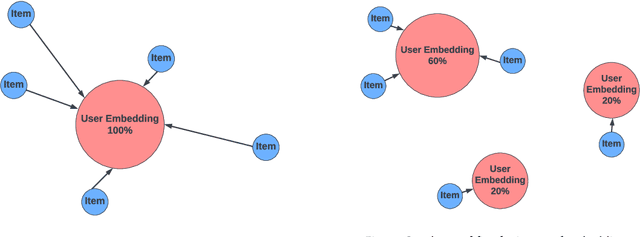
Candidate generation is the first stage in recommendation systems, where a light-weight system is used to retrieve potentially relevant items for an input user. These candidate items are then ranked and pruned in later stages of recommender systems using a more complex ranking model. Since candidate generation is the top of the recommendation funnel, it is important to retrieve a high-recall candidate set to feed into downstream ranking models. A common approach for candidate generation is to leverage approximate nearest neighbor (ANN) search from a single dense query embedding; however, this approach this can yield a low-diversity result set with many near duplicates. As users often have multiple interests, candidate retrieval should ideally return a diverse set of candidates reflective of the user's multiple interests. To this end, we introduce kNN-Embed, a general approach to improving diversity in dense ANN-based retrieval. kNN-Embed represents each user as a smoothed mixture over learned item clusters that represent distinct `interests' of the user. By querying each of a user's mixture component in proportion to their mixture weights, we retrieve a high-diversity set of candidates reflecting elements from each of a user's interests. We experimentally compare kNN-Embed to standard ANN candidate retrieval, and show significant improvements in overall recall and improved diversity across three datasets. Accompanying this work, we open source a large Twitter follow-graph dataset, to spur further research in graph-mining and representation learning for recommender systems.
Privacy-Preserving Recommender Systems Challenge on Twitter's Home Timeline
Apr 28, 2020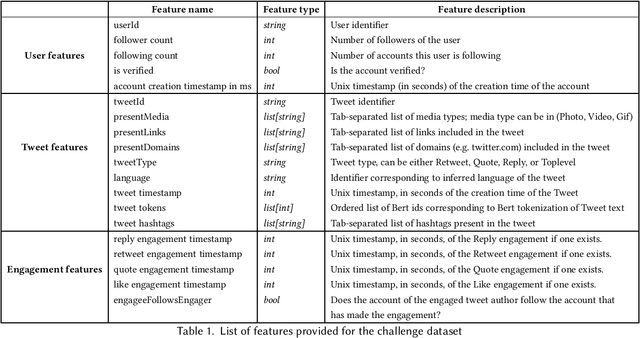
Recommender systems constitute the core engine of most social network platforms nowadays, aiming to maximize user satisfaction along with other key business objectives. Twitter is no exception. Despite the fact that Twitter data has been extensively used to understand socioeconomic and political phenomena and user behaviour, the implicit feedback provided by users on Tweets through their engagements on the Home Timeline has only been explored to a limited extent. At the same time, there is a lack of large-scale public social network datasets that would enable the scientific community to both benchmark and build more powerful and comprehensive models that tailor content to user interests. By releasing an original dataset of 160 million Tweets along with engagement information, Twitter aims to address exactly that. During this release, special attention is drawn on maintaining compliance with existing privacy laws. Apart from user privacy, this paper touches on the key challenges faced by researchers and professionals striving to predict user engagements. It further describes the key aspects of the RecSys 2020 Challenge that was organized by ACM RecSys in partnership with Twitter using this dataset.