 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLINKX: A Scalable Unified Framework For Homophilous and Heterophilous Graphs
Nov 19, 2022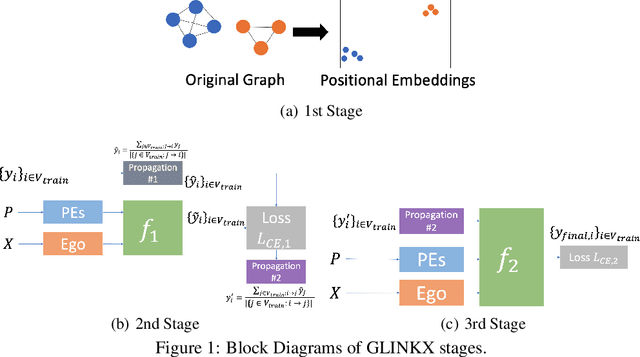



In graph learning, there have been two predominant inductive biases regarding graph-inspired architectures: On the one hand, higher-order interactions and message passing work well on homophilous graphs and are leveraged by GCNs and GATs. Such architectures, however, cannot easily scale to large real-world graphs. On the other hand, shallow (or node-level) models using ego features and adjacency embeddings work well in heterophilous graphs. In this work, we propose a novel scalable shallow method -- GLINKX -- that can work both on homophilous and heterophilous graphs. GLINKX leverages (i) novel monophilous label propagations, (ii) ego/node features, (iii) knowledge graph embeddings as positional embeddings, (iv) node-level training, and (v) low-dimensional message passing. Formally, we prove novel error bounds and justify the components of GLINKX. Experimentally, we show its effectiveness on several homophilous and heterophilous datasets.
Towards Trustworthy Automatic Diagnosis Systems by Emulating Doctors' Reasoning with Deep Reinforcement Learning
Oct 13, 2022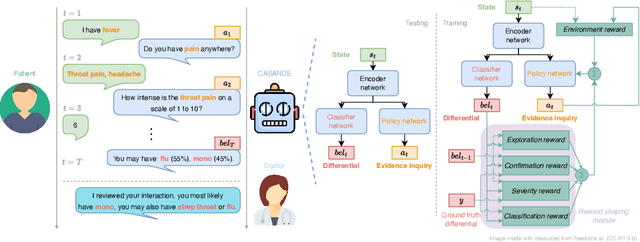
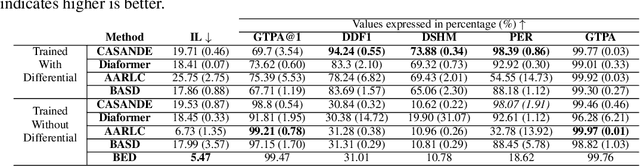
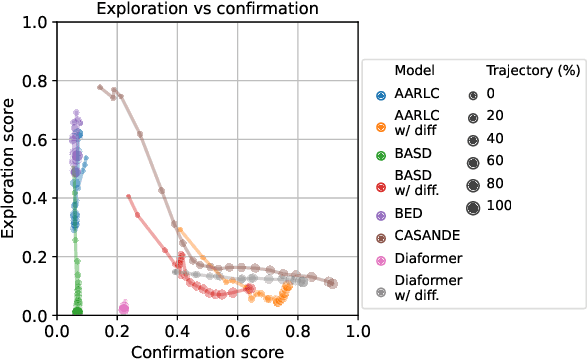

The automation of the medical evidence acquisition and diagnosis process has recently attracted increasing attention in order to reduce the workload of doctors and democratize access to medical care. However, most works proposed in the machine learning literature focus solely on improving the prediction accuracy of a patient's pathology. We argue that this objective is insufficient to ensure doctors' acceptability of such systems. In their initial interaction with patients, doctors do not only focus on identifying the pathology a patient is suffering from; they instead generate a differential diagnosis (in the form of a short list of plausible diseases) because the medical evidence collected from patients is often insufficient to establish a final diagnosis. Moreover, doctors explicitly explore severe pathologies before potentially ruling them out from the differential, especially in acute care settings. Finally, for doctors to trust a system's recommendations, they need to understand how the gathered evidences led to the predicted diseases. In particular, interactions between a system and a patient need to emulate the reasoning of doctors. We therefore propose to model the evidence acquisition and automatic diagnosis tasks using a deep reinforcement learning framework that considers three essential aspects of a doctor's reasoning, namely generating a differential diagnosis using an exploration-confirmation approach while prioritizing severe pathologies. We propose metrics for evaluating interaction quality based on these three aspects. We show that our approach performs better than existing models while maintaining competitive pathology prediction accuracy.
DDXPlus: A new Dataset for Medical Automatic Diagnosis
May 18, 2022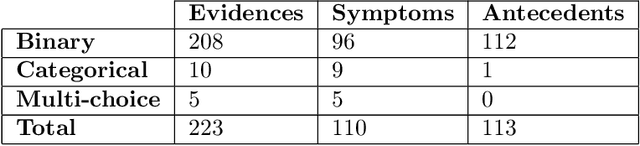
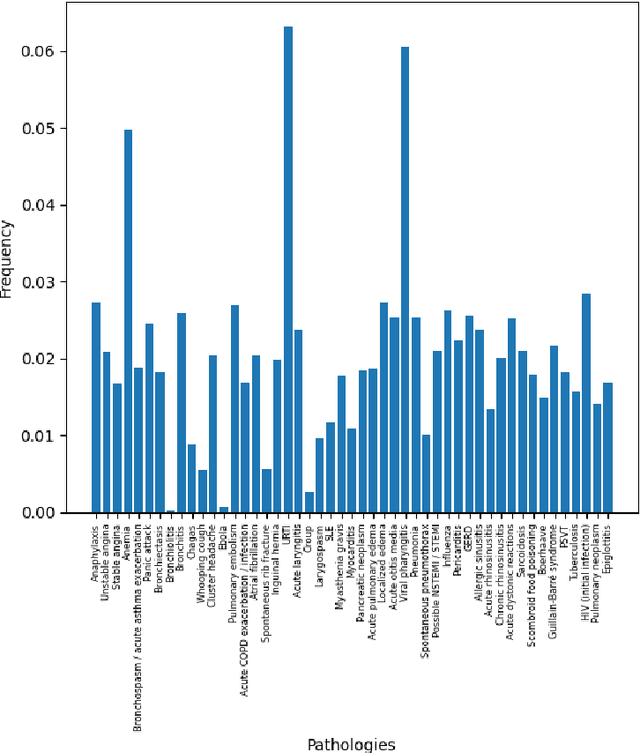
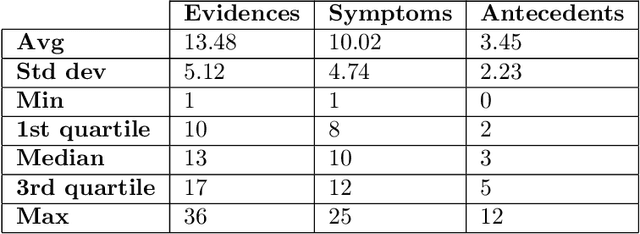
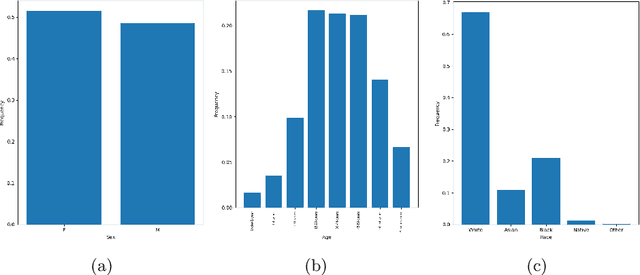
There has been rapidly growing interests in Automatic Diagnosis (AD) and Automatic Symptom Detection (ASD) systems in the machine learning research literature, aiming to assist doctors in telemedicine services. These systems are designed to interact with patients, collect evidence relevant to their concerns, and make predictions about the underlying diseases. Doctors would review the interaction, including the evidence and the predictions, before making their final decisions. Despite the recent progress, an important piece of doctors' interactions with patients is missing in the design of AD and ASD systems, namely the differential diagnosis. Its absence is largely due to the lack of datasets that include such information for models to train on. In this work, we present a large-scale synthetic dataset that includes a differential diagnosis, along with the ground truth pathology, for each patient. In addition, this dataset includes more pathologies, as well as types of symtoms and antecedents. As a proof-of-concept, we extend several existing AD and ASD systems to incorporate differential diagnosis, and provide empirical evidence that using differentials in training signals is essential for such systems to learn to predict differentials. Dataset available at https://github.com/bruzwen/ddxplus
Static Prediction of Runtime Errors by Learning to Execute Programs with External Resource Descriptions
Mar 07, 2022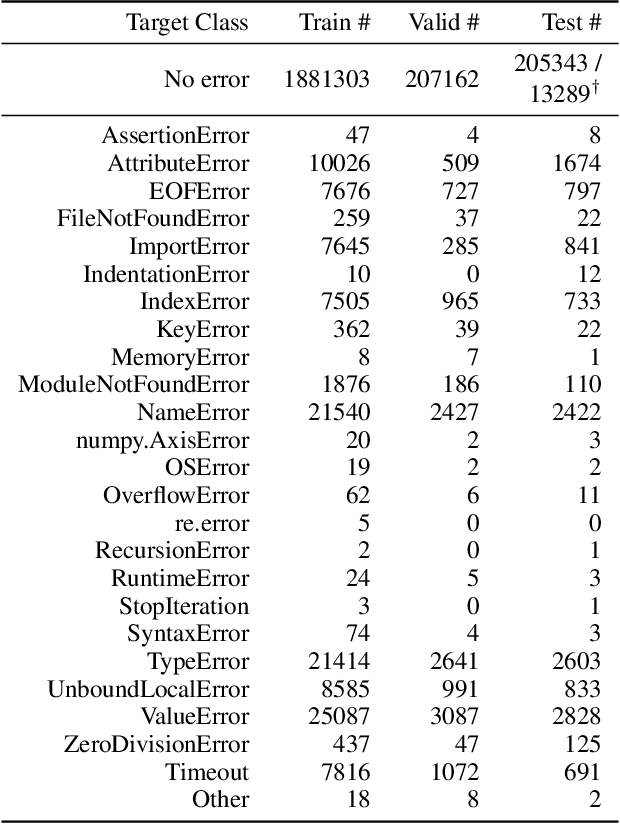

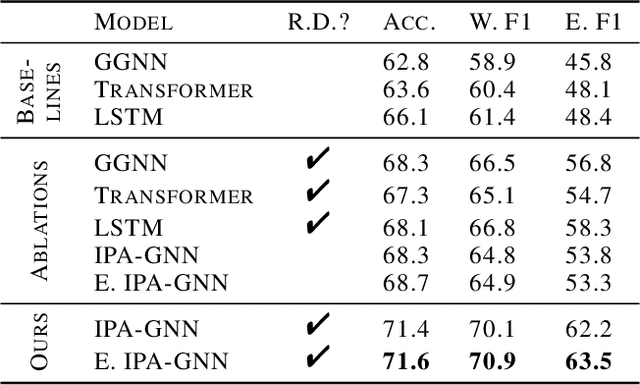
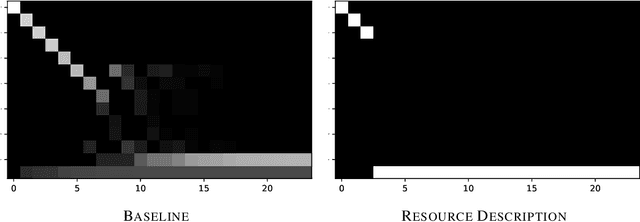
The execution behavior of a program often depends on external resources, such as program inputs or file contents, and so cannot be run in isolation. Nevertheless, software developers benefit from fast iteration loops where automated tools identify errors as early as possible, even before programs can be compiled and run. This presents an interesting machine learning challenge: can we predict runtime errors in a "static" setting, where program execution is not possible? Here, we introduce a real-world dataset and task for predicting runtime errors, which we show is difficult for generic models like Transformers. We approach this task by developing an interpreter-inspired architecture with an inductive bias towards mimicking program executions, which models exception handling and "learns to execute" descriptions of the contents of external resources. Surprisingly, we show that the model can also predict the location of the error, despite being trained only on labels indicating the presence/absence and kind of error. In total, we present a practical and difficult-yet-approachable challenge problem related to learning program execution and we demonstrate promising new capabilities of interpreter-inspired machine learning models for code.
Data-Efficient Reinforcement Learning with Momentum Predictive Representations
Jul 12, 2020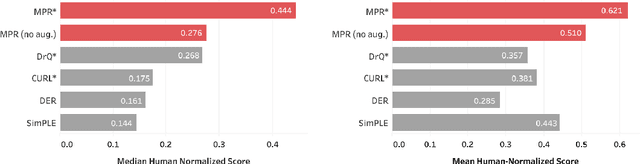
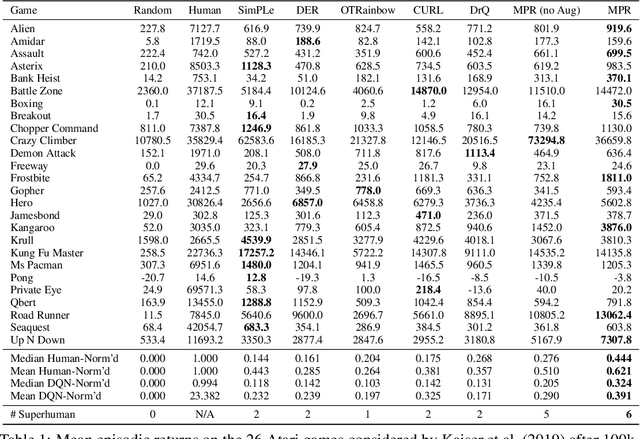
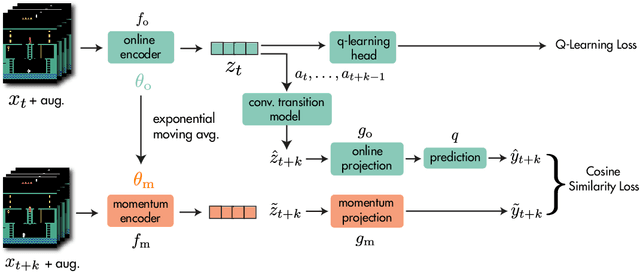

While deep reinforcement learning excels at solving tasks where large amounts of data can be collected through virtually unlimited interaction with the environment, learning from limited interaction remains a key challenge. We posit that an agent can learn more efficiently if we augment reward maximization with self-supervised objectives based on structure in its visual input and sequential interaction with the environment. Our method, Momentum Predictive Representations (MPR), trains an agent to predict its own latent state representations multiple steps into the future. We compute target representations for future states using an encoder which is an exponential moving average of the agent's parameters, and we make predictions using a learned transition model. On its own, this future prediction objective outperforms prior methods for sample-efficient deep RL from pixels. We further improve performance by adding data augmentation to the future prediction loss, which forces the agent's representations to be consistent across multiple views of an observation. Our full self-supervised objective, which combines future prediction and data augmentation, achieves a median human-normalized score of 0.444 on Atari in a setting limited to 100K steps of environment interaction, which is a 66% relative improvement over the previous state-of-the-art. Moreover, even in this limited data regime, MPR exceeds expert human scores on 6 out of 26 games.
Out-of-Sample Representation Learning for Multi-Relational Graphs
Apr 28, 2020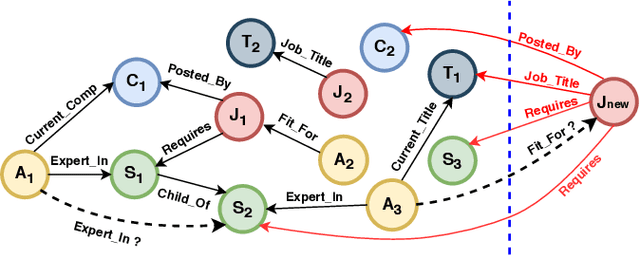
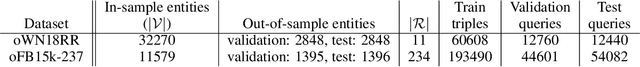

Many important problems can be formulated as reasoning in multi-relational graphs. Representation learning has proved extremely effective for transductive reasoning, in which one needs to make new predictions for already observed entities. This is true for both attributed graphs (where each entity has an initial feature vector) and non-attributed graphs(where the only initial information derives from known relations with other entities). For out-of-sample reasoning, where one needs to make predictions for entities that were unseen at training time, much prior work considers attributed graph. However, this problem has been surprisingly left unexplored for non-attributed graphs. In this paper, we introduce the out-of-sample representation learning problem for non-attributed multi-relational graphs, create benchmark datasets for this task, develop several models and baselines, and provide empirical analyses and comparisons of the proposed models and baselines.
Time2Vec: Learning a Vector Representation of Time
Jul 11, 2019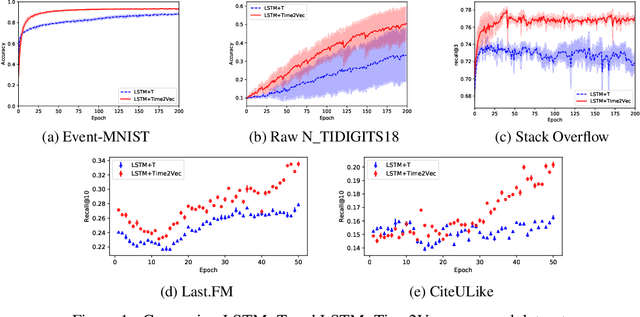
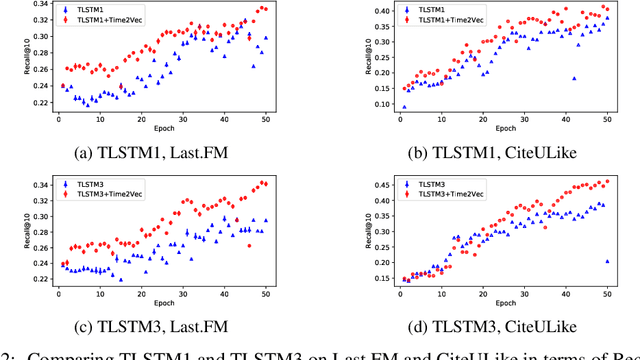
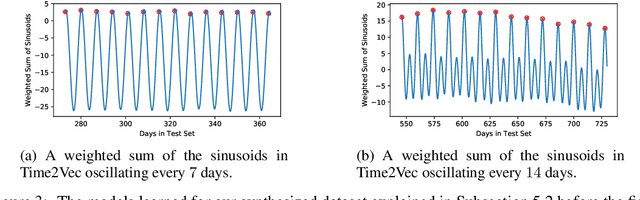
Time is an important feature in many applications involving events that occur synchronously and/or asynchronously. To effectively consume time information, recent studies have focused on designing new architectures. In this paper, we take an orthogonal but complementary approach by providing a model-agnostic vector representation for time, called Time2Vec, that can be easily imported into many existing and future architectures and improve their performances. We show on a range of models and problems that replacing the notion of time with its Time2Vec representation improves the performance of the final model.
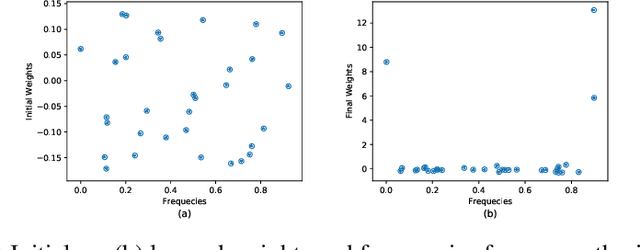
Diachronic Embedding for Temporal Knowledge Graph Completion
Jul 06, 2019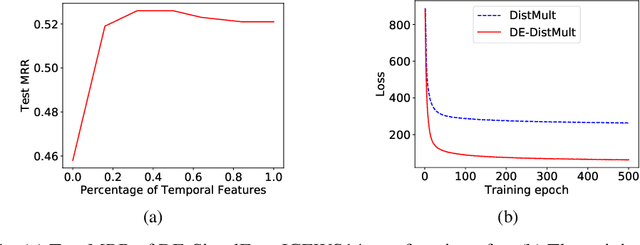
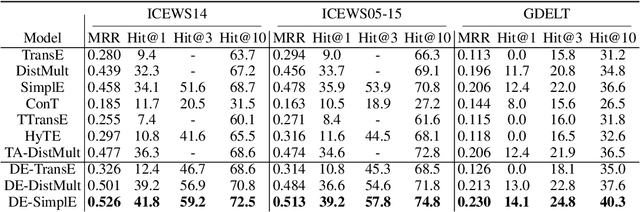
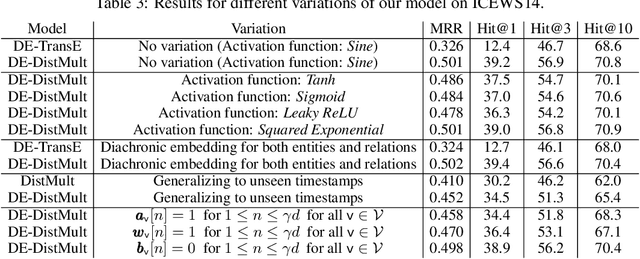
Knowledge graphs (KGs) typically contain temporal facts indicating relationships among entities at different times. Due to their incompleteness, several approaches have been proposed to infer new facts for a KG based on the existing ones-a problem known as KG completion. KG embedding approaches have proved effective for KG completion, however, they have been developed mostly for static KGs. Developing temporal KG embedding models is an increasingly important problem. In this paper, we build novel models for temporal KG completion through equipping static models with a diachronic entity embedding function which provides the characteristics of entities at any point in time. This is in contrast to the existing temporal KG embedding approaches where only static entity features are provided. The proposed embedding function is model-agnostic and can be potentially combined with any static model. We prove that combining it with SimplE, a recent model for static KG embedding, results in a fully expressive model for temporal KG completion. Our experiments indicate the superiority of our proposal compared to existing baselines.
Relational Representation Learning for Dynamic (Knowledge) Graphs: A Survey
May 27, 2019
Graphs arise naturally in many real-world applications including social networks, recommender systems, ontologies, biology, and computational finance. Traditionally, machine learning models for graphs have been mostly designed for static graphs. However, many applications involve evolving graphs. This introduces important challenges for learning and inference since nodes, attributes, and edges change over time. In this survey, we review the recent advances in representation learning for dynamic graphs, including dynamic knowledge graphs. We describe existing models from an encoder-decoder perspective, categorize these encoders and decoders based on the techniques they employ, and analyze the approaches in each category. We also review several prominent applications and widely used datasets, and highlight directions for future research.
Fast Retinomorphic Event Stream for Video Recognition and Reinforcement Learning
May 19, 2018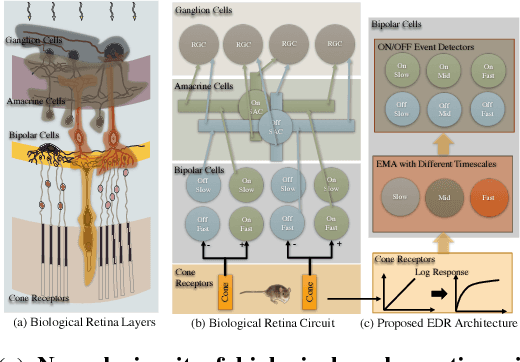
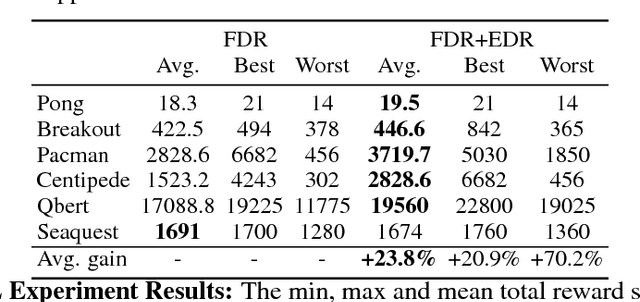
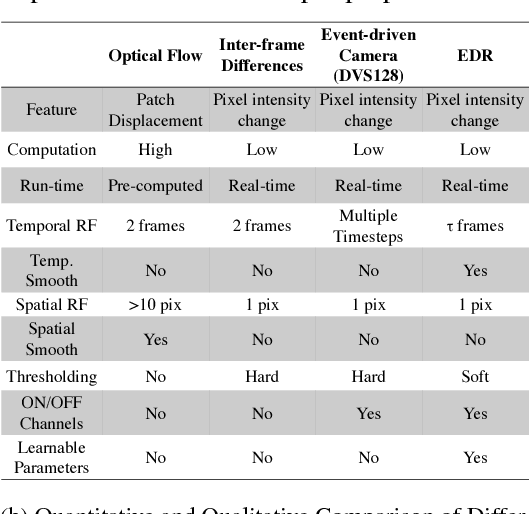
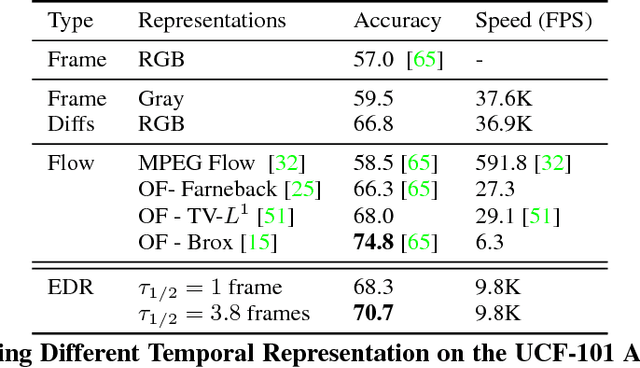
Good temporal representations are crucial for video understanding, and the state-of-the-art video recognition framework is based on two-stream networks. In such framework, besides the regular ConvNets responsible for RGB frame inputs, a second network is introduced to handle the temporal representation, usually the optical flow (OF). However, OF or other task-oriented flow is computationally costly, and is thus typically pre-computed. Critically, this prevents the two-stream approach from being applied to reinforcement learning (RL) applications such as video game playing, where the next state depends on current state and action choices. Inspired by the early vision systems of mammals and insects, we propose a fast event-driven representation (EDR) that models several major properties of early retinal circuits: (1) logarithmic input response, (2) multi-timescale temporal smoothing to filter noise, and (3) bipolar (ON/OFF) pathways for primitive event detection[12]. Trading off the directional information for fast speed (> 9000 fps), EDR en-ables fast real-time inference/learning in video applications that require interaction between an agent and the world such as game-playing, virtual robotics, and domain adaptation. In this vein, we use EDR to demonstrate performance improvements over state-of-the-art reinforcement learning algorithms for Atari games, something that has not been possible with pre-computed OF. Moreover, with UCF-101 video action recognition experiments, we show that EDR performs near state-of-the-art in accuracy while achieving a 1,500x speedup in input representation processing, as compared to optical flow.