 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime2Vec: Learning a Vector Representation of Time
Jul 11, 2019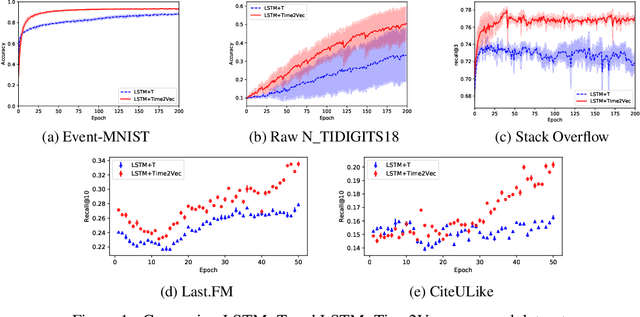
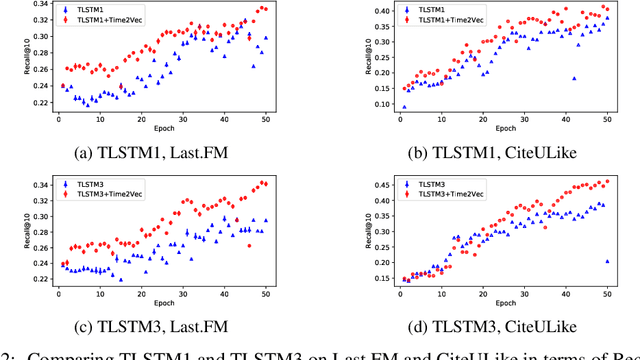
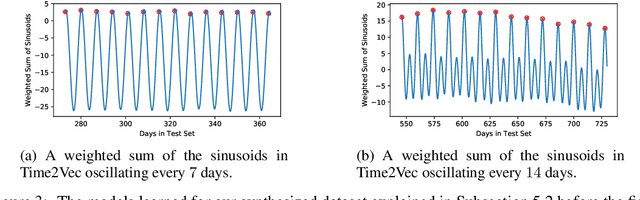
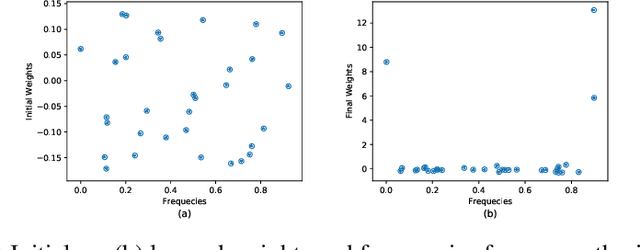
Time is an important feature in many applications involving events that occur synchronously and/or asynchronously. To effectively consume time information, recent studies have focused on designing new architectures. In this paper, we take an orthogonal but complementary approach by providing a model-agnostic vector representation for time, called Time2Vec, that can be easily imported into many existing and future architectures and improve their performances. We show on a range of models and problems that replacing the notion of time with its Time2Vec representation improves the performance of the final model.
Deep Spherical Quantization for Image Search
Jun 07, 2019
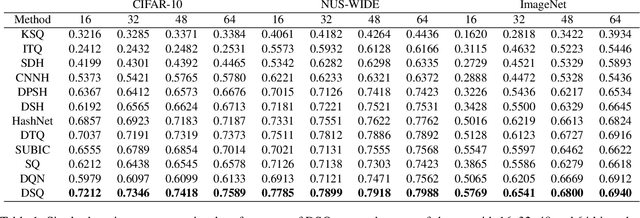
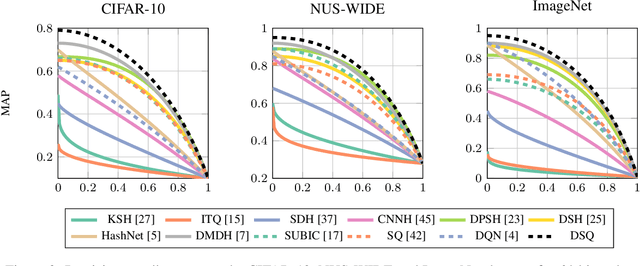
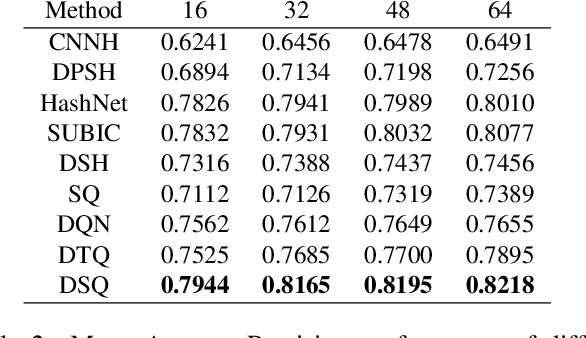
Hashing methods, which encode high-dimensional images with compact discrete codes, have been widely applied to enhance large-scale image retrieval. In this paper, we put forward Deep Spherical Quantization (DSQ), a novel method to make deep convolutional neural networks generate supervised and compact binary codes for efficient image search. Our approach simultaneously learns a mapping that transforms the input images into a low-dimensional discriminative space, and quantizes the transformed data points using multi-codebook quantization. To eliminate the negative effect of norm variance on codebook learning, we force the network to L_2 normalize the extracted features and then quantize the resulting vectors using a new supervised quantization technique specifically designed for points lying on a unit hypersphere. Furthermore, we introduce an easy-to-implement extension of our quantization technique that enforces sparsity on the codebooks. Extensive experiments demonstrate that DSQ and its sparse variant can generate semantically separable compact binary codes outperforming many state-of-the-art image retrieval methods on three benchmarks.
Fast Cosine Similarity Search in Binary Space with Angular Multi-index Hashing
Apr 18, 2018
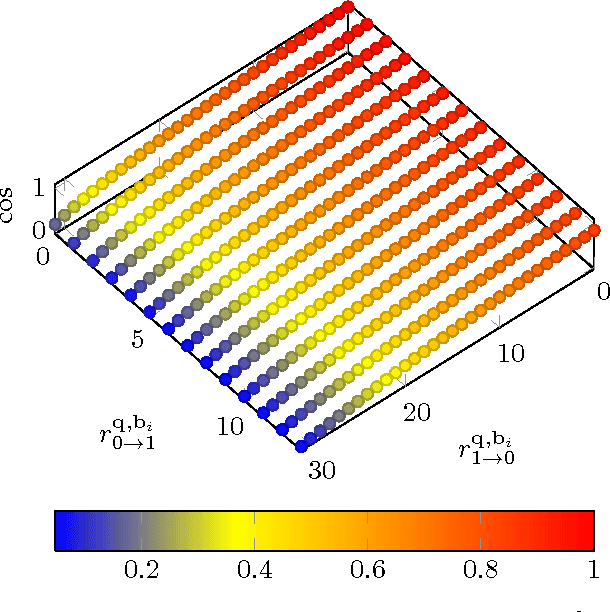
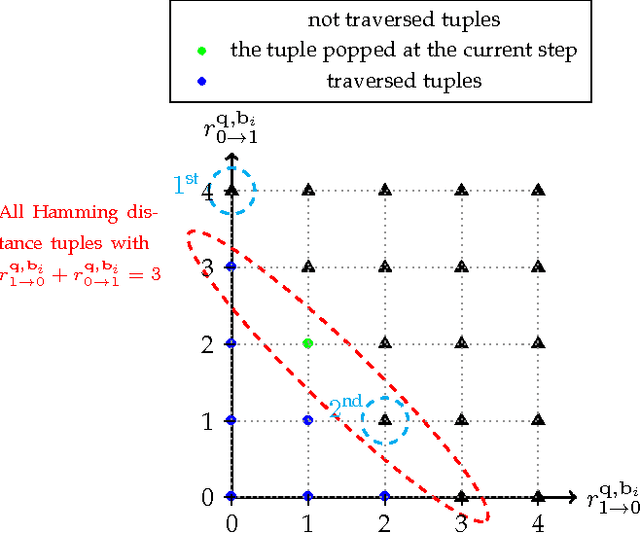
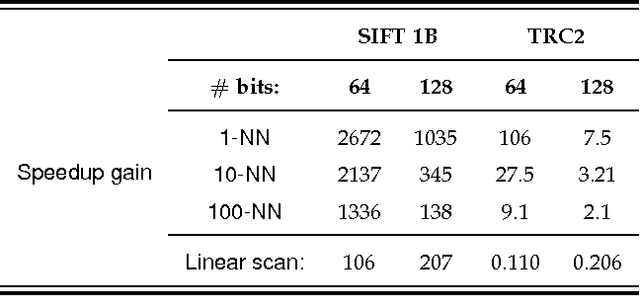
Given a large dataset of binary codes and a binary query point, we address how to efficiently find $K$ codes in the dataset that yield the largest cosine similarities to the query. The straightforward answer to this problem is to compare the query with all items in the dataset, but this is practical only for small datasets. One potential solution to enhance the search time and achieve sublinear cost is to use a hash table populated with binary codes of the dataset and then look up the nearby buckets to the query to retrieve the nearest neighbors. However, if codes are compared in terms of cosine similarity rather than the Hamming distance, then the main issue is that the order of buckets to probe is not evident. To examine this issue, we first elaborate on the connection between the Hamming distance and the cosine similarity. Doing this allows us to systematically find the probing sequence in the hash table. However, solving the nearest neighbor search with a single table is only practical for short binary codes. To address this issue, we propose the angular multi-index hashing search algorithm which relies on building multiple hash tables on binary code substrings. The proposed search algorithm solves the exact angular $K$ nearest neighbor problem in a time that is often orders of magnitude faster than the linear scan baseline and even approximation methods.
An Approximation Approach for Solving the Subpath Planning Problem
Mar 20, 2016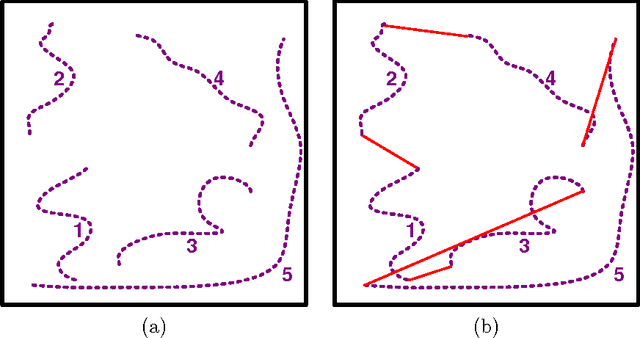
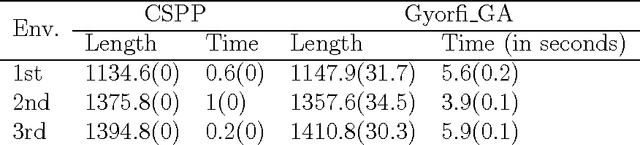
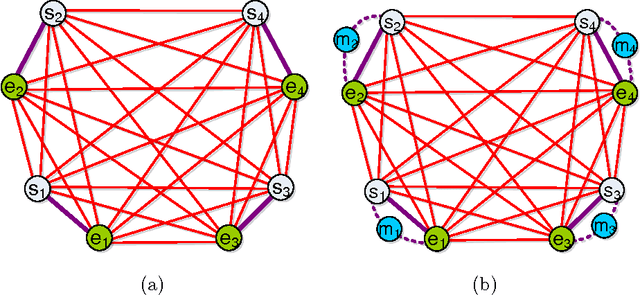
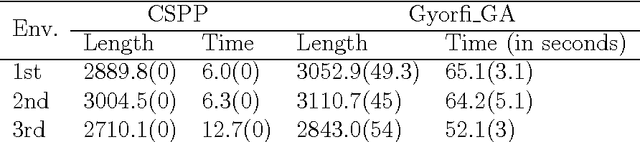
The subpath planning problem is a branch of the path planning problem, which has widespread applications in automated manufacturing process as well as vehicle and robot navigation. This problem is to find the shortest path or tour subject for travelling a set of given subpaths. The current approaches for dealing with the subpath planning problem are all based on meta-heuristic approaches. It is well-known that meta-heuristic based approaches have several deficiencies. To address them, we propose a novel approximation algorithm in the O(n^3) time complexity class, which guarantees to solve any subpath planning problem instance with the fixed ratio bound of 2. Also, the formal proofs of the claims, our empirical evaluation shows that our approximation method acts much better than a state-of-the-art method, both in result and execution time.