 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTaleX: A Spatiotemporal-Aware Adaptive Auto-scaling Framework for Microservices
Jan 30, 2025



While cloud environments and auto-scaling solutions have been widely applied to traditional monolithic applications, they face significant limitations when it comes to microservices-based architectures. Microservices introduce additional challenges due to their dynamic and spatiotemporal characteristics, which require more efficient and specialized auto-scaling strategies. Centralized auto-scaling for the entire microservice application is insufficient, as each service within a chain has distinct specifications and performance requirements. Therefore, each service requires its own dedicated auto-scaler to address its unique scaling needs effectively, while also considering the dependencies with other services in the chain and the overall application. This paper presents a combination of control theory, machine learning, and heuristics to address these challenges. We propose an adaptive auto-scaling framework, STaleX, for microservices that integrates spatiotemporal features, enabling real-time resource adjustments to minimize SLO violations. STaleX employs a set of weighted Proportional-Integral-Derivative (PID) controllers for each service, where weights are dynamically adjusted based on a supervisory unit that integrates spatiotemporal features. This supervisory unit continuously monitors and adjusts both the weights and the resources allocated to each service. Our framework accounts for spatial features, including service specifications and dependencies among services, as well as temporal variations in workload, ensuring that resource allocation is continuously optimized. Through experiments on a microservice-based demo application deployed on a Kubernetes cluster, we demonstrate the effectiveness of our framework in improving performance and reducing costs compared to traditional scaling methods like Kubernetes Horizontal Pod Autoscaler (HPA) with a 26.9% reduction in resource usage.
FlaKat: A Machine Learning-Based Categorization Framework for Flaky Tests
Mar 01, 2024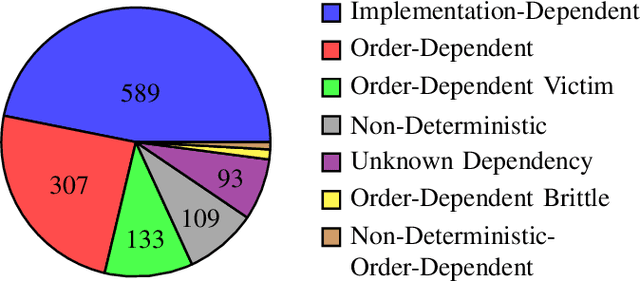
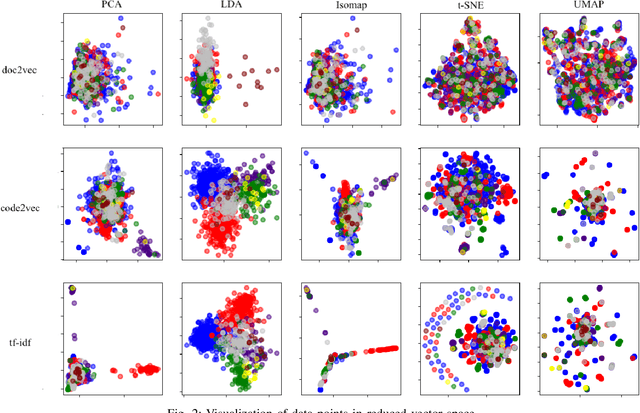
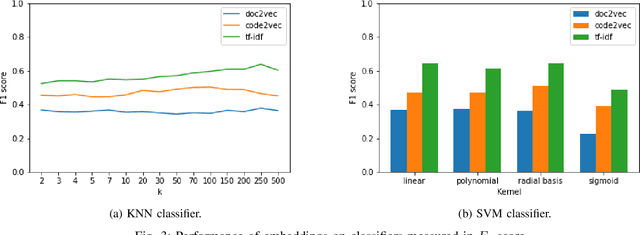
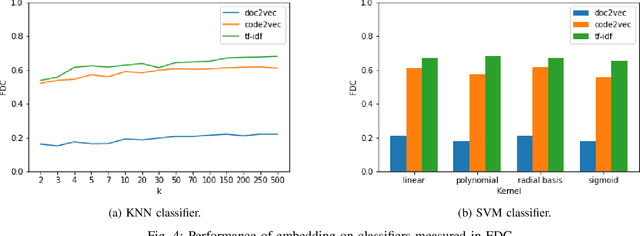
Flaky tests can pass or fail non-deterministically, without alterations to a software system. Such tests are frequently encountered by developers and hinder the credibility of test suites. State-of-the-art research incorporates machine learning solutions into flaky test detection and achieves reasonably good accuracy. Moreover, the majority of automated flaky test repair solutions are designed for specific types of flaky tests. This research work proposes a novel categorization framework, called FlaKat, which uses machine-learning classifiers for fast and accurate prediction of the category of a given flaky test that reflects its root cause. Sampling techniques are applied to address the imbalance between flaky test categories in the International Dataset of Flaky Test (IDoFT). A new evaluation metric, called Flakiness Detection Capacity (FDC), is proposed for measuring the accuracy of classifiers from the perspective of information theory and provides proof for its effectiveness. The final FDC results are also in agreement with F1 score regarding which classifier yields the best flakiness classification.
Deep Spherical Quantization for Image Search
Jun 07, 2019
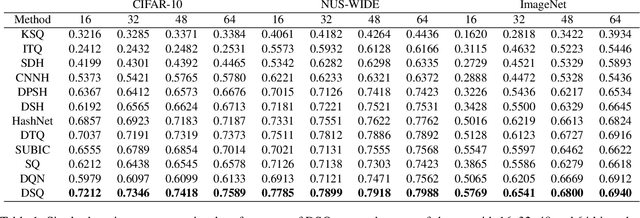
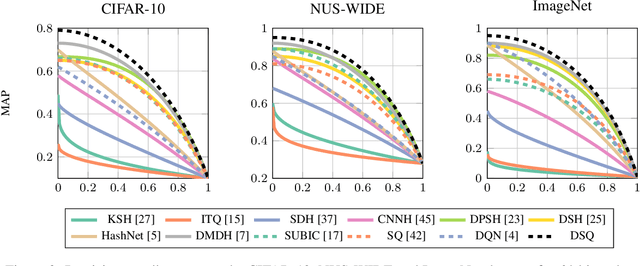
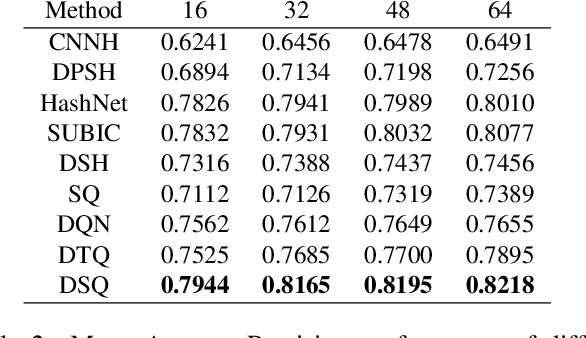
Hashing methods, which encode high-dimensional images with compact discrete codes, have been widely applied to enhance large-scale image retrieval. In this paper, we put forward Deep Spherical Quantization (DSQ), a novel method to make deep convolutional neural networks generate supervised and compact binary codes for efficient image search. Our approach simultaneously learns a mapping that transforms the input images into a low-dimensional discriminative space, and quantizes the transformed data points using multi-codebook quantization. To eliminate the negative effect of norm variance on codebook learning, we force the network to L_2 normalize the extracted features and then quantize the resulting vectors using a new supervised quantization technique specifically designed for points lying on a unit hypersphere. Furthermore, we introduce an easy-to-implement extension of our quantization technique that enforces sparsity on the codebooks. Extensive experiments demonstrate that DSQ and its sparse variant can generate semantically separable compact binary codes outperforming many state-of-the-art image retrieval methods on three benchmarks.
Fast Cosine Similarity Search in Binary Space with Angular Multi-index Hashing
Apr 18, 2018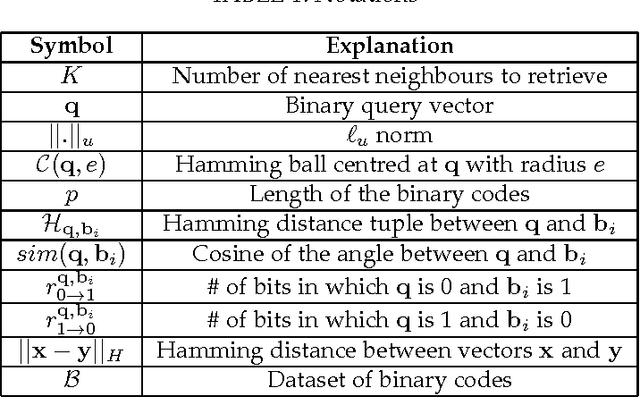
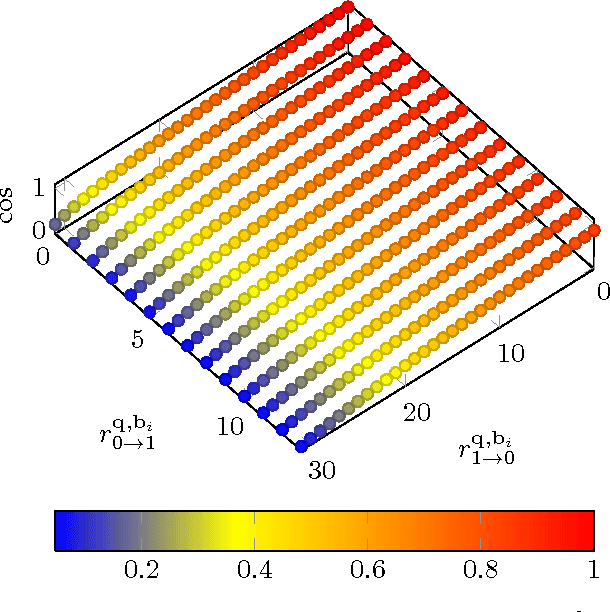
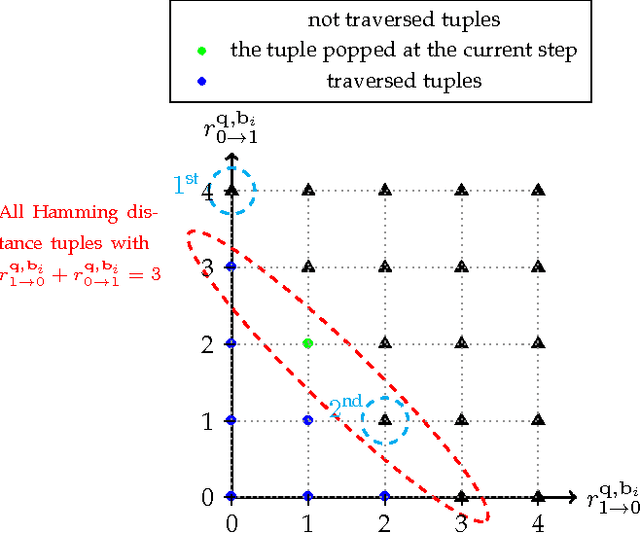
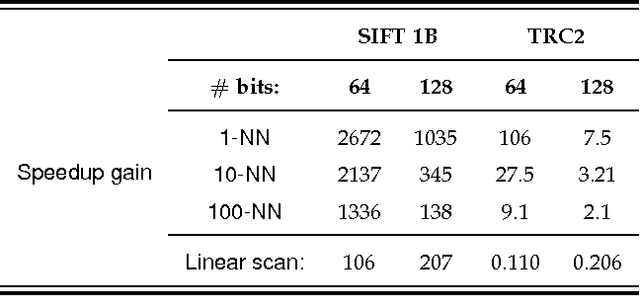
Given a large dataset of binary codes and a binary query point, we address how to efficiently find $K$ codes in the dataset that yield the largest cosine similarities to the query. The straightforward answer to this problem is to compare the query with all items in the dataset, but this is practical only for small datasets. One potential solution to enhance the search time and achieve sublinear cost is to use a hash table populated with binary codes of the dataset and then look up the nearby buckets to the query to retrieve the nearest neighbors. However, if codes are compared in terms of cosine similarity rather than the Hamming distance, then the main issue is that the order of buckets to probe is not evident. To examine this issue, we first elaborate on the connection between the Hamming distance and the cosine similarity. Doing this allows us to systematically find the probing sequence in the hash table. However, solving the nearest neighbor search with a single table is only practical for short binary codes. To address this issue, we propose the angular multi-index hashing search algorithm which relies on building multiple hash tables on binary code substrings. The proposed search algorithm solves the exact angular $K$ nearest neighbor problem in a time that is often orders of magnitude faster than the linear scan baseline and even approximation methods.