 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlaKat: A Machine Learning-Based Categorization Framework for Flaky Tests
Paper and Code
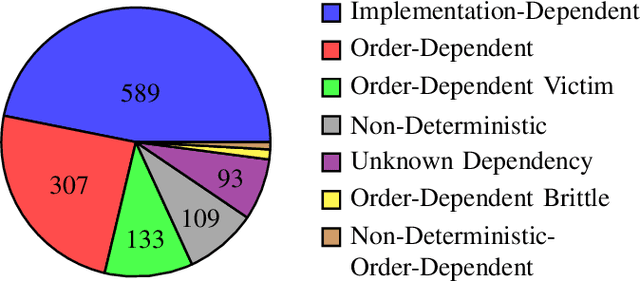
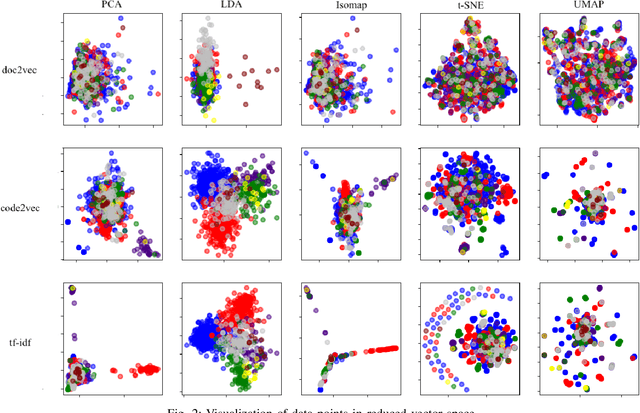
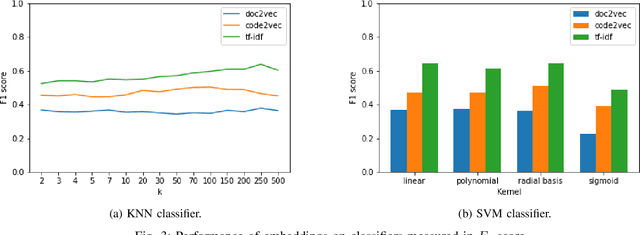
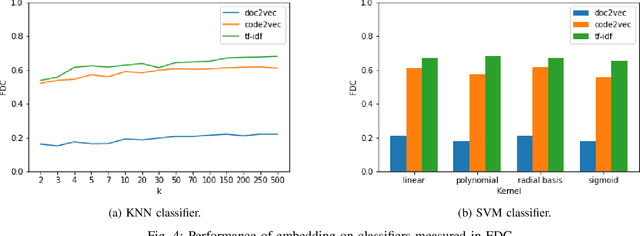
Flaky tests can pass or fail non-deterministically, without alterations to a software system. Such tests are frequently encountered by developers and hinder the credibility of test suites. State-of-the-art research incorporates machine learning solutions into flaky test detection and achieves reasonably good accuracy. Moreover, the majority of automated flaky test repair solutions are designed for specific types of flaky tests. This research work proposes a novel categorization framework, called FlaKat, which uses machine-learning classifiers for fast and accurate prediction of the category of a given flaky test that reflects its root cause. Sampling techniques are applied to address the imbalance between flaky test categories in the International Dataset of Flaky Test (IDoFT). A new evaluation metric, called Flakiness Detection Capacity (FDC), is proposed for measuring the accuracy of classifiers from the perspective of information theory and provides proof for its effectiveness. The final FDC results are also in agreement with F1 score regarding which classifier yields the best flakiness classification.