 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Spectral Bias of Shallow Neural Network Learning is Shaped by the Choice of Non-linearity
Mar 13, 2025



Despite classical statistical theory predicting severe overfitting, modern massively overparameterized neural networks still generalize well. This unexpected property is attributed to the network's so-called implicit bias, which describes its propensity to converge to solutions that generalize effectively, among the many possible that correctly label the training data. The aim of our research is to explore this bias from a new perspective, focusing on how non-linear activation functions contribute to shaping it. First, we introduce a reparameterization which removes a continuous weight rescaling symmetry. Second, in the kernel regime, we leverage this reparameterization to generalize recent findings that relate shallow Neural Networks to the Radon transform, deriving an explicit formula for the implicit bias induced by a broad class of activation functions. Specifically, by utilizing the connection between the Radon transform and the Fourier transform, we interpret the kernel regime's inductive bias as minimizing a spectral seminorm that penalizes high-frequency components, in a manner dependent on the activation function. Finally, in the adaptive regime, we demonstrate the existence of local dynamical attractors that facilitate the formation of clusters of hyperplanes where the input to a neuron's activation function is zero, yielding alignment between many neurons' response functions. We confirm these theoretical results with simulations. All together, our work provides a deeper understanding of the mechanisms underlying the generalization capabilities of overparameterized neural networks and its relation with the implicit bias, offering potential pathways for designing more efficient and robust models.
Navigating protein landscapes with a machine-learned transferable coarse-grained model
Oct 27, 2023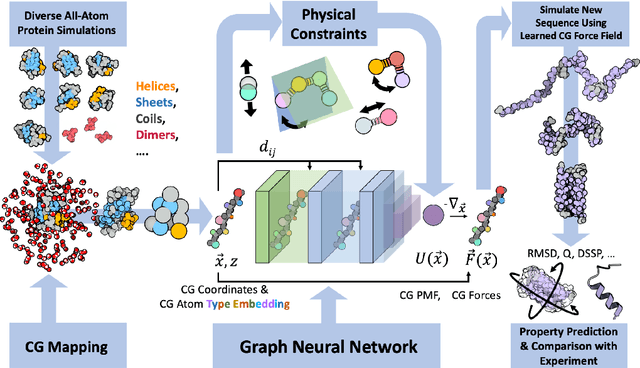
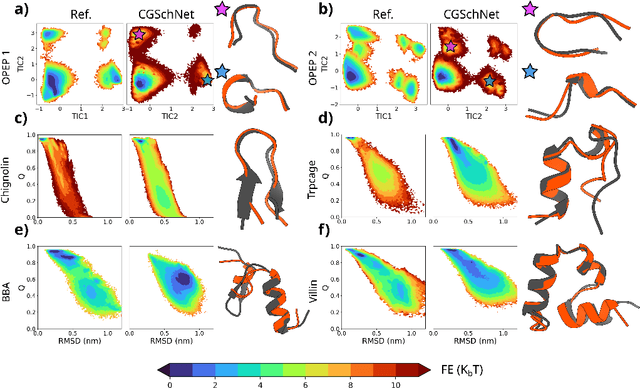

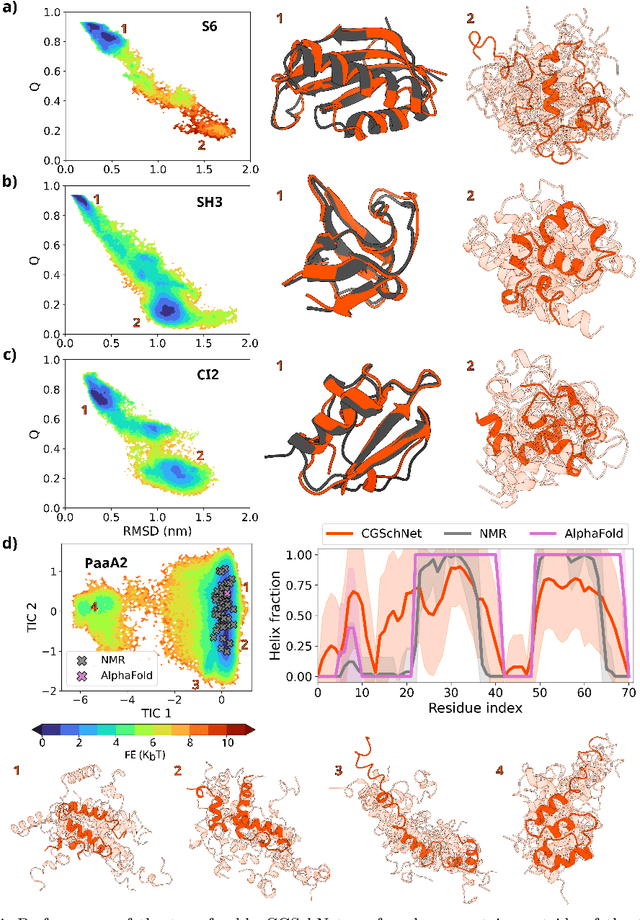
The most popular and universally predictive protein simulation models employ all-atom molecular dynamics (MD), but they come at extreme computational cost. The development of a universal, computationally efficient coarse-grained (CG) model with similar prediction performance has been a long-standing challenge. By combining recent deep learning methods with a large and diverse training set of all-atom protein simulations, we here develop a bottom-up CG force field with chemical transferability, which can be used for extrapolative molecular dynamics on new sequences not used during model parametrization. We demonstrate that the model successfully predicts folded structures, intermediates, metastable folded and unfolded basins, and the fluctuations of intrinsically disordered proteins while it is several orders of magnitude faster than an all-atom model. This showcases the feasibility of a universal and computationally efficient machine-learned CG model for proteins.
Transforming Gait: Video-Based Spatiotemporal Gait Analysis
Mar 17, 2022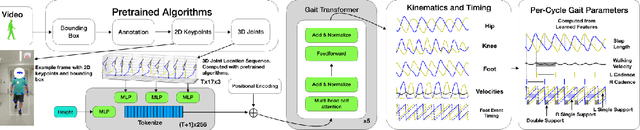


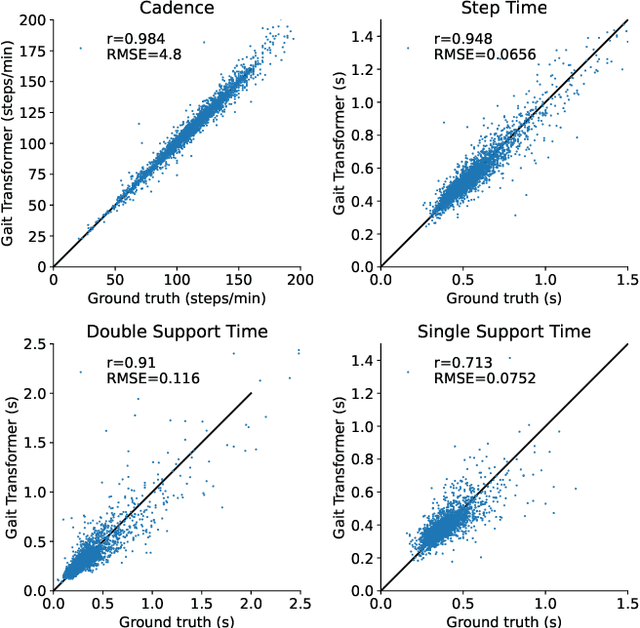
Human pose estimation from monocular video is a rapidly advancing field that offers great promise to human movement science and rehabilitation. This potential is tempered by the smaller body of work ensuring the outputs are clinically meaningful and properly calibrated. Gait analysis, typically performed in a dedicated lab, produces precise measurements including kinematics and step timing. Using over 7000 monocular video from an instrumented gait analysis lab, we trained a neural network to map 3D joint trajectories and the height of individuals onto interpretable biomechanical outputs including gait cycle timing and sagittal plane joint kinematics and spatiotemporal trajectories. This task specific layer produces accurate estimates of the timing of foot contact and foot off events. After parsing the kinematic outputs into individual gait cycles, it also enables accurate cycle-by-cycle estimates of cadence, step time, double and single support time, walking speed and step length.
Shallow Univariate ReLu Networks as Splines: Initialization, Loss Surface, Hessian, & Gradient Flow Dynamics
Aug 04, 2020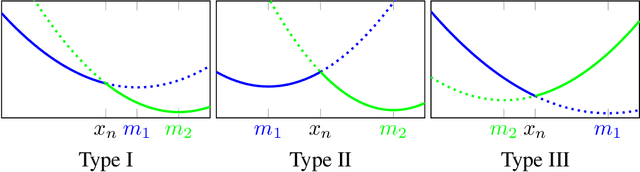
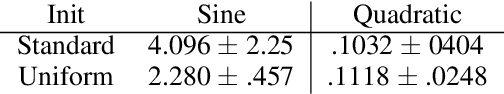
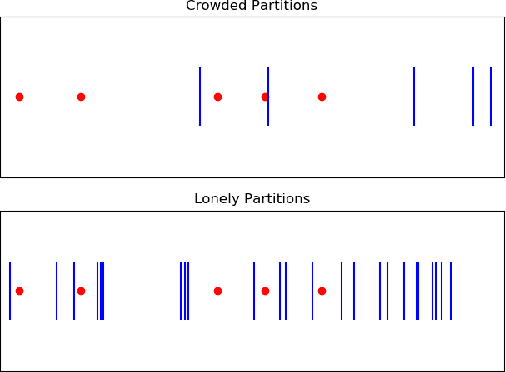
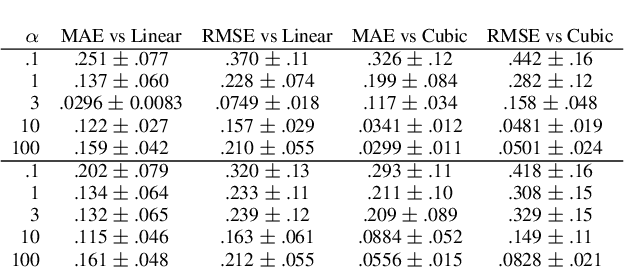
Understanding the learning dynamics and inductive bias of neural networks (NNs) is hindered by the opacity of the relationship between NN parameters and the function represented. We propose reparametrizing ReLU NNs as continuous piecewise linear splines. Using this spline lens, we study learning dynamics in shallow univariate ReLU NNs, finding unexpected insights and explanations for several perplexing phenomena. We develop a surprisingly simple and transparent view of the structure of the loss surface, including its critical and fixed points, Hessian, and Hessian spectrum. We also show that standard weight initializations yield very flat functions, and that this flatness, together with overparametrization and the initial weight scale, is responsible for the strength and type of implicit regularization, consistent with recent work arXiv:1906.05827. Our implicit regularization results are complementary to recent work arXiv:1906.07842, done independently, which showed that initialization scale critically controls implicit regularization via a kernel-based argument. Our spline-based approach reproduces their key implicit regularization results but in a far more intuitive and transparent manner. Going forward, our spline-based approach is likely to extend naturally to the multivariate and deep settings, and will play a foundational role in efforts to understand neural networks. Videos of learning dynamics using a spline-based visualization are available at http://shorturl.at/tFWZ2.
Using Learning Dynamics to Explore the Role of Implicit Regularization in Adversarial Examples
Jun 19, 2020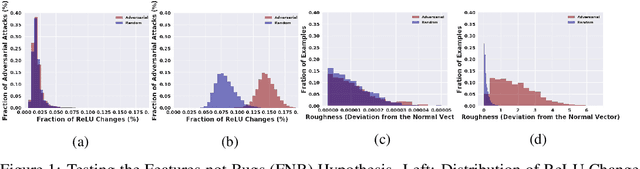
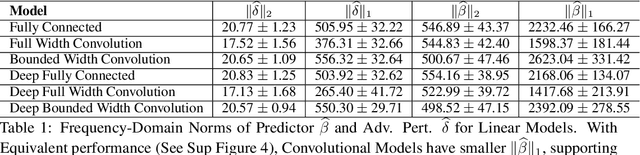
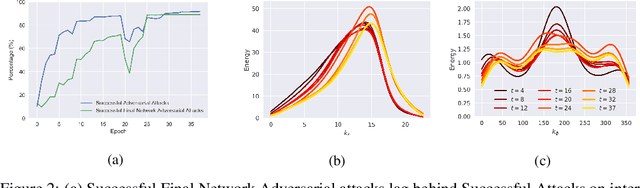
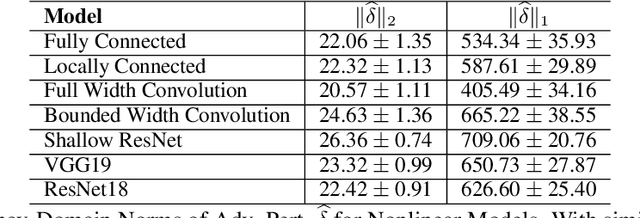
Recent work (Ilyas et al, 2019) suggests that adversarial examples are features not bugs. If adversarial perturbations are indeed useful but non-robust features, then what is their origin? In order to answer these questions, we systematically examine the learning dynamics of adversarial perturbations both in the pixel and frequency domains. We find that: (1) adversarial examples are not present at initialization but instead emerge very early in training, typically within the first epochs, as verified by a novel breakpoint-based analysis; (2) the low-amplitude high-frequency nature of common adversarial perturbations in natural images is critically dependent on an implicit bias towards sparsity in the frequency domain; and (3) the origin of this bias is the locality and translation invariance of convolutional filters, along with (4) the existence of useful frequency-domain features in natural images. We provide a simple theoretical explanation for these observations, providing a clear and minimalist target for theorists in future work. Looking forward, our findings suggest that analyzing the learning dynamics of perturbations can provide useful insights for understanding the origin of adversarial sensitivities and developing robust solutions.
JR-GAN: Jacobian Regularization for Generative Adversarial Networks
Jun 24, 2018
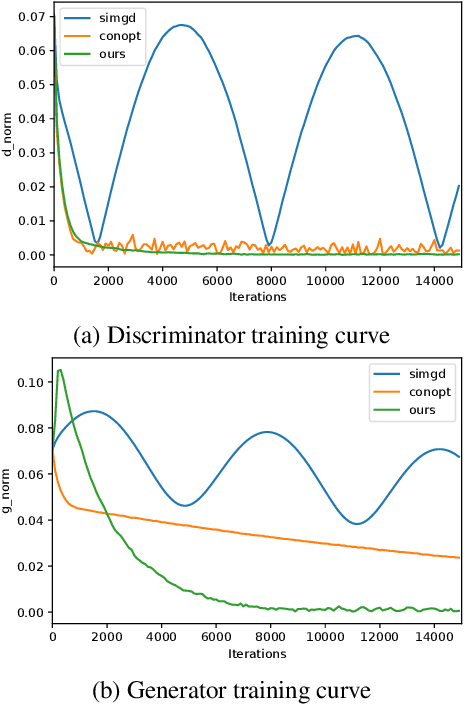
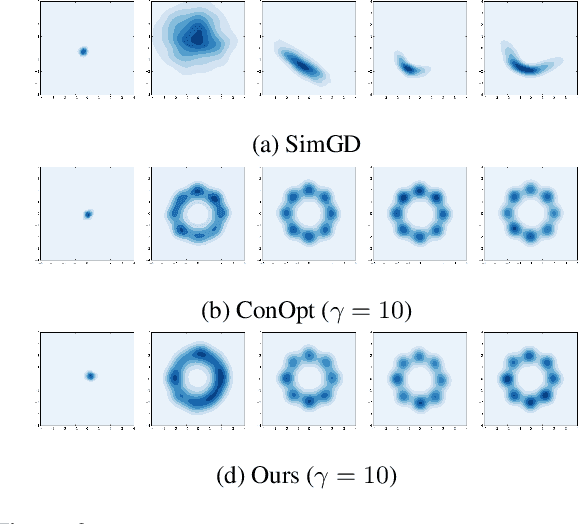
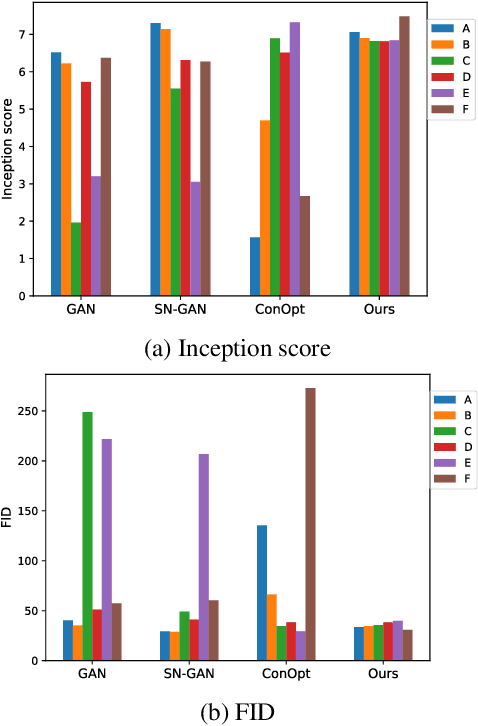
Generative adversarial networks (GANs) are notoriously difficult to train and the reasons for their (non-)convergence behaviors are still not completely understood. Using a simple GAN example, we mathematically analyze the local convergence behavior of its training dynamics in a non-asymptotic way. We find that in order to ensure a good convergence rate two factors of the Jacobian should be \textit{simultaneously} avoided, which are (1) Phase Factor: the Jacobian has complex eigenvalues with a large imaginary-to-real ratio, (2) Conditioning Factor: the Jacobian is ill-conditioned. Previous methods of regularizing the Jacobian can only alleviate one of these two factors, while making the other more severe. From our theoretical analysis, we propose the Jacobian Regularized GANs (JR-GANs), which insure the two factors are alleviated by construction. With extensive experiments on several popular datasets, we show that the JR-GAN training is highly stable and achieves near state-of-the-art results both qualitatively and quantitatively.
A Theoretical Explanation for Perplexing Behaviors of Backpropagation-based Visualizations
Jun 08, 2018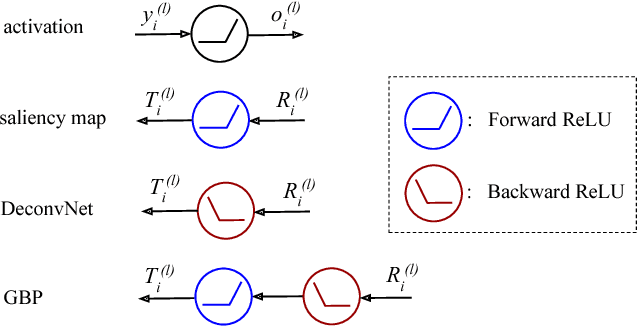


Backpropagation-based visualizations have been proposed to interpret convolutional neural networks (CNNs), however a theory is missing to justify their behaviors: Guided backpropagation (GBP) and deconvolutional network (DeconvNet) generate more human-interpretable but less class-sensitive visualizations than saliency map. Motivated by this, we develop a theoretical explanation revealing that GBP and DeconvNet are essentially doing (partial) image recovery which is unrelated to the network decisions. Specifically, our analysis shows that the backward ReLU introduced by GBP and DeconvNet, and the local connections in CNNs are the two main causes of compelling visualizations. Extensive experiments are provided that support the theoretical analysis.
Fast Retinomorphic Event Stream for Video Recognition and Reinforcement Learning
May 19, 2018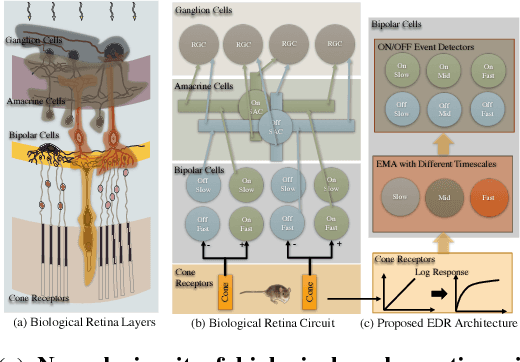
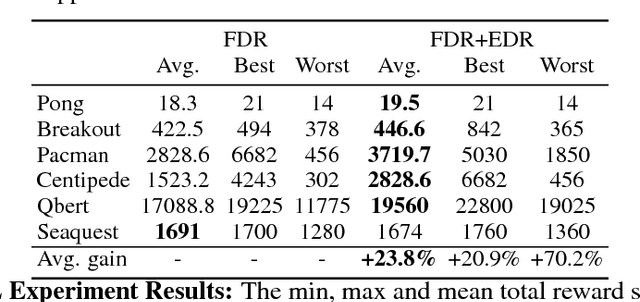
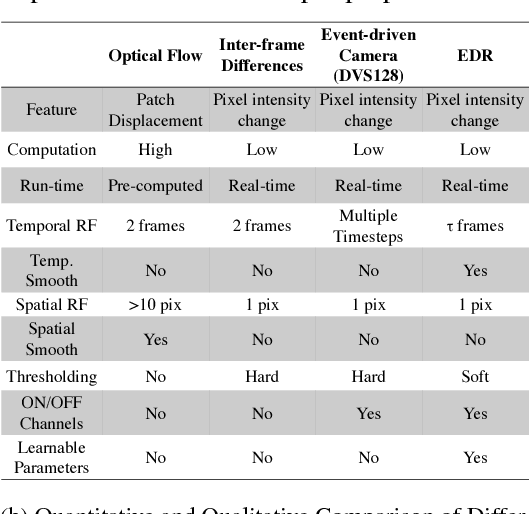
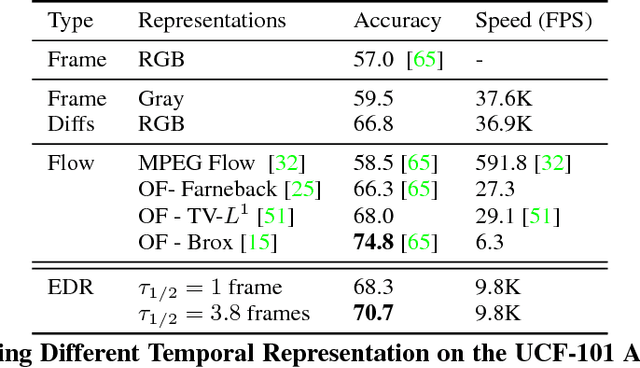
Good temporal representations are crucial for video understanding, and the state-of-the-art video recognition framework is based on two-stream networks. In such framework, besides the regular ConvNets responsible for RGB frame inputs, a second network is introduced to handle the temporal representation, usually the optical flow (OF). However, OF or other task-oriented flow is computationally costly, and is thus typically pre-computed. Critically, this prevents the two-stream approach from being applied to reinforcement learning (RL) applications such as video game playing, where the next state depends on current state and action choices. Inspired by the early vision systems of mammals and insects, we propose a fast event-driven representation (EDR) that models several major properties of early retinal circuits: (1) logarithmic input response, (2) multi-timescale temporal smoothing to filter noise, and (3) bipolar (ON/OFF) pathways for primitive event detection[12]. Trading off the directional information for fast speed (> 9000 fps), EDR en-ables fast real-time inference/learning in video applications that require interaction between an agent and the world such as game-playing, virtual robotics, and domain adaptation. In this vein, we use EDR to demonstrate performance improvements over state-of-the-art reinforcement learning algorithms for Atari games, something that has not been possible with pre-computed OF. Moreover, with UCF-101 video action recognition experiments, we show that EDR performs near state-of-the-art in accuracy while achieving a 1,500x speedup in input representation processing, as compared to optical flow.
Overcomplete Frame Thresholding for Acoustic Scene Analysis
Dec 25, 2017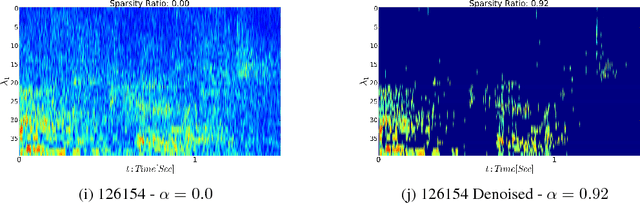
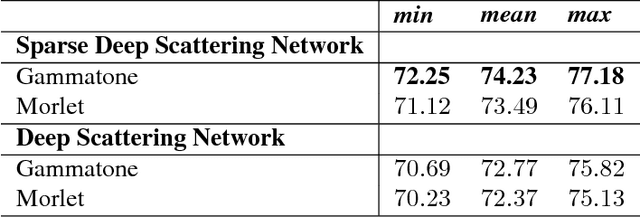
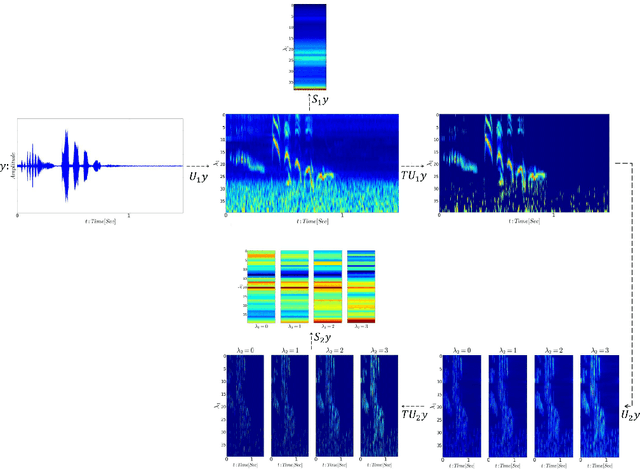

In this work, we derive a generic overcomplete frame thresholding scheme based on risk minimization. Overcomplete frames being favored for analysis tasks such as classification, regression or anomaly detection, we provide a way to leverage those optimal representations in real-world applications through the use of thresholding. We validate the method on a large scale bird activity detection task via the scattering network architecture performed by means of continuous wavelets, known for being an adequate dictionary in audio environments.
Training Neural Networks Without Gradients: A Scalable ADMM Approach
May 06, 2016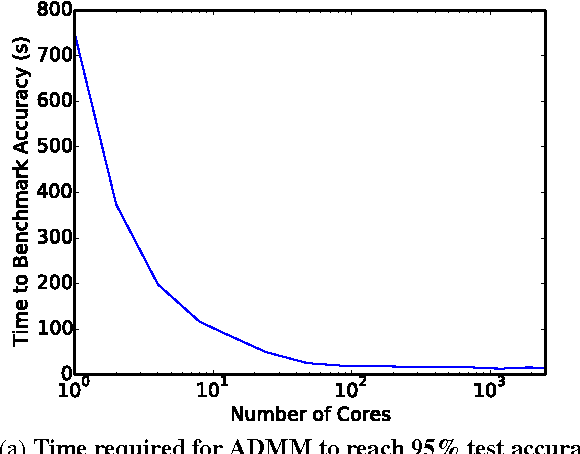
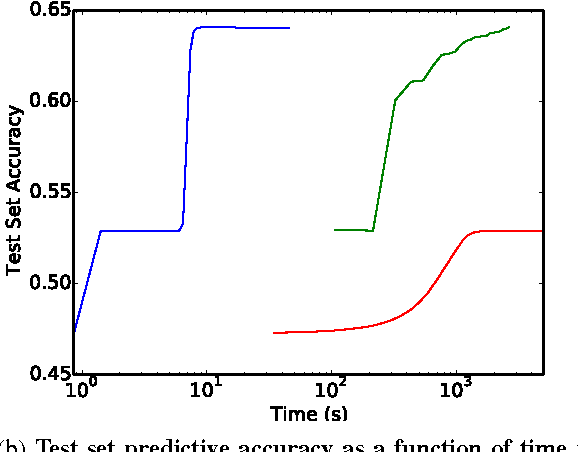
With the growing importance of large network models and enormous training datasets, GPUs have become increasingly necessary to train neural networks. This is largely because conventional optimization algorithms rely on stochastic gradient methods that don't scale well to large numbers of cores in a cluster setting. Furthermore, the convergence of all gradient methods, including batch methods, suffers from common problems like saturation effects, poor conditioning, and saddle points. This paper explores an unconventional training method that uses alternating direction methods and Bregman iteration to train networks without gradient descent steps. The proposed method reduces the network training problem to a sequence of minimization sub-steps that can each be solved globally in closed form. The proposed method is advantageous because it avoids many of the caveats that make gradient methods slow on highly non-convex problems. The method exhibits strong scaling in the distributed setting, yielding linear speedups even when split over thousands of cores.