 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMBC Special Issue: Calibrated Uncertainty for Trustworthy Clinical Gait Analysis Using Probabilistic Multiview Markerless Motion Capture
Jan 29, 2026Video-based human movement analysis holds potential for movement assessment in clinical practice and research. However, the clinical implementation and trust of multi-view markerless motion capture (MMMC) require that, in addition to being accurate, these systems produce reliable confidence intervals to indicate how accurate they are for any individual. Building on our prior work utilizing variational inference to estimate joint angle posterior distributions, this study evaluates the calibration and reliability of a probabilistic MMMC method. We analyzed data from 68 participants across two institutions, validating the model against an instrumented walkway and standard marker-based motion capture. We measured the calibration of the confidence intervals using the Expected Calibration Error (ECE). The model demonstrated reliable calibration, yielding ECE values generally < 0.1 for both step and stride length and bias-corrected gait kinematics. We observed a median step and stride length error of ~16 mm and ~12 mm respectively, with median bias-corrected kinematic errors ranging from 1.5 to 3.8 degrees across lower extremity joints. Consistent with the calibrated ECE, the magnitude of the model's predicted uncertainty correlated strongly with observed error measures. These findings indicate that, as designed, the probabilistic model reconstruction quantifies epistemic uncertainty, allowing it to identify unreliable outputs without the need for concurrent ground-truth instrumentation.
Similarity as Reward Alignment: Robust and Versatile Preference-based Reinforcement Learning
Jun 14, 2025Preference-based Reinforcement Learning (PbRL) entails a variety of approaches for aligning models with human intent to alleviate the burden of reward engineering. However, most previous PbRL work has not investigated the robustness to labeler errors, inevitable with labelers who are non-experts or operate under time constraints. Additionally, PbRL algorithms often target very specific settings (e.g. pairwise ranked preferences or purely offline learning). We introduce Similarity as Reward Alignment (SARA), a simple contrastive framework that is both resilient to noisy labels and adaptable to diverse feedback formats and training paradigms. SARA learns a latent representation of preferred samples and computes rewards as similarities to the learned latent. We demonstrate strong performance compared to baselines on continuous control offline RL benchmarks. We further demonstrate SARA's versatility in applications such as trajectory filtering for downstream tasks, cross-task preference transfer, and reward shaping in online learning.
BiomechGPT: Towards a Biomechanically Fluent Multimodal Foundation Model for Clinically Relevant Motion Tasks
May 24, 2025Advances in markerless motion capture are expanding access to biomechanical movement analysis, making it feasible to obtain high-quality movement data from outpatient clinics, inpatient hospitals, therapy, and even home. Expanding access to movement data in these diverse contexts makes the challenge of performing downstream analytics all the more acute. Creating separate bespoke analysis code for all the tasks end users might want is both intractable and does not take advantage of the common features of human movement underlying them all. Recent studies have shown that fine-tuning language models to accept tokenized movement as an additional modality enables successful descriptive captioning of movement. Here, we explore whether such a multimodal motion-language model can answer detailed, clinically meaningful questions about movement. We collected over 30 hours of biomechanics from nearly 500 participants, many with movement impairments from a variety of etiologies, performing a range of movements used in clinical outcomes assessments. After tokenizing these movement trajectories, we created a multimodal dataset of motion-related questions and answers spanning a range of tasks. We developed BiomechGPT, a multimodal biomechanics-language model, on this dataset. Our results show that BiomechGPT demonstrates high performance across a range of tasks such as activity recognition, identifying movement impairments, diagnosis, scoring clinical outcomes, and measuring walking. BiomechGPT provides an important step towards a foundation model for rehabilitation movement data.
KinTwin: Imitation Learning with Torque and Muscle Driven Biomechanical Models Enables Precise Replication of Able-Bodied and Impaired Movement from Markerless Motion Capture
May 19, 2025Broader access to high-quality movement analysis could greatly benefit movement science and rehabilitation, such as allowing more detailed characterization of movement impairments and responses to interventions, or even enabling early detection of new neurological conditions or fall risk. While emerging technologies are making it easier to capture kinematics with biomechanical models, or how joint angles change over time, inferring the underlying physics that give rise to these movements, including ground reaction forces, joint torques, or even muscle activations, is still challenging. Here we explore whether imitation learning applied to a biomechanical model from a large dataset of movements from able-bodied and impaired individuals can learn to compute these inverse dynamics. Although imitation learning in human pose estimation has seen great interest in recent years, our work differences in several ways: we focus on using an accurate biomechanical model instead of models adopted for computer vision, we test it on a dataset that contains participants with impaired movements, we reported detailed tracking metrics relevant for the clinical measurement of movement including joint angles and ground contact events, and finally we apply imitation learning to a muscle-driven neuromusculoskeletal model. We show that our imitation learning policy, KinTwin, can accurately replicate the kinematics of a wide range of movements, including those with assistive devices or therapist assistance, and that it can infer clinically meaningful differences in joint torques and muscle activations. Our work demonstrates the potential for using imitation learning to enable high-quality movement analysis in clinical practice.
Biomechanical Reconstruction with Confidence Intervals from Multiview Markerless Motion Capture
Feb 10, 2025



Advances in multiview markerless motion capture (MMMC) promise high-quality movement analysis for clinical practice and research. While prior validation studies show MMMC performs well on average, they do not provide what is needed in clinical practice or for large-scale utilization of MMMC -- confidence intervals over specific kinematic estimates from a specific individual analyzed using a possibly unique camera configuration. We extend our previous work using an implicit representation of trajectories optimized end-to-end through a differentiable biomechanical model to learn the posterior probability distribution over pose given all the detected keypoints. This posterior probability is learned through a variational approximation and estimates confidence intervals for individual joints at each moment in a trial, showing confidence intervals generally within 10-15 mm of spatial error for virtual marker locations, consistent with our prior validation studies. Confidence intervals over joint angles are typically only a few degrees and widen for more distal joints. The posterior also models the correlation structure over joint angles, such as correlations between hip and pelvis angles. The confidence intervals estimated through this method allow us to identify times and trials where kinematic uncertainty is high.
Differentiable Biomechanics for Markerless Motion Capture in Upper Limb Stroke Rehabilitation: A Comparison with Optical Motion Capture
Nov 22, 2024



Marker-based Optical Motion Capture (OMC) paired with biomechanical modeling is currently considered the most precise and accurate method for measuring human movement kinematics. However, combining differentiable biomechanical modeling with Markerless Motion Capture (MMC) offers a promising approach to motion capture in clinical settings, requiring only minimal equipment, such as synchronized webcams, and minimal effort for data collection. This study compares key kinematic outcomes from biomechanically modeled MMC and OMC data in 15 stroke patients performing the drinking task, a functional task recommended for assessing upper limb movement quality. We observed a high level of agreement in kinematic trajectories between MMC and OMC, as indicated by high correlations (median r above 0.95 for the majority of kinematic trajectories) and median RMSE values ranging from 2-5 degrees for joint angles, 0.04 m/s for end-effector velocity, and 6 mm for trunk displacement. Trial-to-trial biases between OMC and MMC were consistent within participant sessions, with interquartile ranges of bias around 1-3 degrees for joint angles, 0.01 m/s in end-effector velocity, and approximately 3mm for trunk displacement. Our findings indicate that our MMC for arm tracking is approaching the accuracy of marker-based methods, supporting its potential for use in clinical settings. MMC could provide valuable insights into movement rehabilitation in stroke patients, potentially enhancing the effectiveness of rehabilitation strategies.
A Causal Framework for Precision Rehabilitation
Nov 06, 2024



Precision rehabilitation offers the promise of an evidence-based approach for optimizing individual rehabilitation to improve long-term functional outcomes. Emerging techniques, including those driven by artificial intelligence, are rapidly expanding our ability to quantify the different domains of function during rehabilitation, other encounters with healthcare, and in the community. While this seems poised to usher rehabilitation into the era of big data and should be a powerful driver of precision rehabilitation, our field lacks a coherent framework to utilize these data and deliver on this promise. We propose a framework that builds upon multiple existing pillars to fill this gap. Our framework aims to identify the Optimal Dynamic Treatment Regimens (ODTR), or the decision-making strategy that takes in the range of available measurements and biomarkers to identify interventions likely to maximize long-term function. This is achieved by designing and fitting causal models, which extend the Computational Neurorehabilitation framework using tools from causal inference. These causal models can learn from heterogeneous data from different silos, which must include detailed documentation of interventions, such as using the Rehabilitation Treatment Specification System. The models then serve as digital twins of patient recovery trajectories, which can be used to learn the ODTR. Our causal modeling framework also emphasizes quantitatively linking changes across levels of the functioning to ensure that interventions can be precisely selected based on careful measurement of impairments while also being selected to maximize outcomes that are meaningful to patients and stakeholders. We believe this approach can provide a unifying framework to leverage growing big rehabilitation data and AI-powered measurements to produce precision rehabilitation treatments that can improve clinical outcomes.
Fusing uncalibrated IMUs and handheld smartphone video to reconstruct knee kinematics
May 27, 2024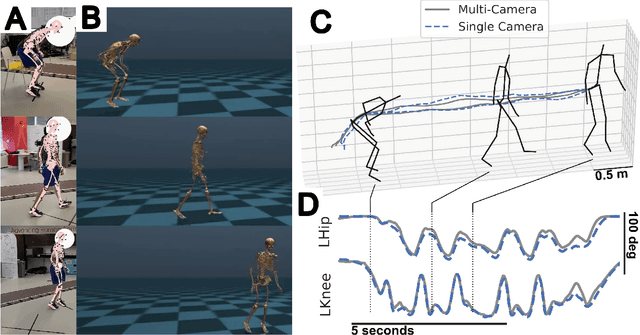
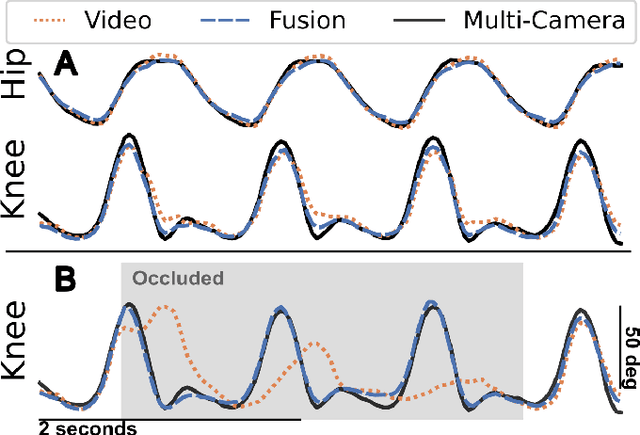
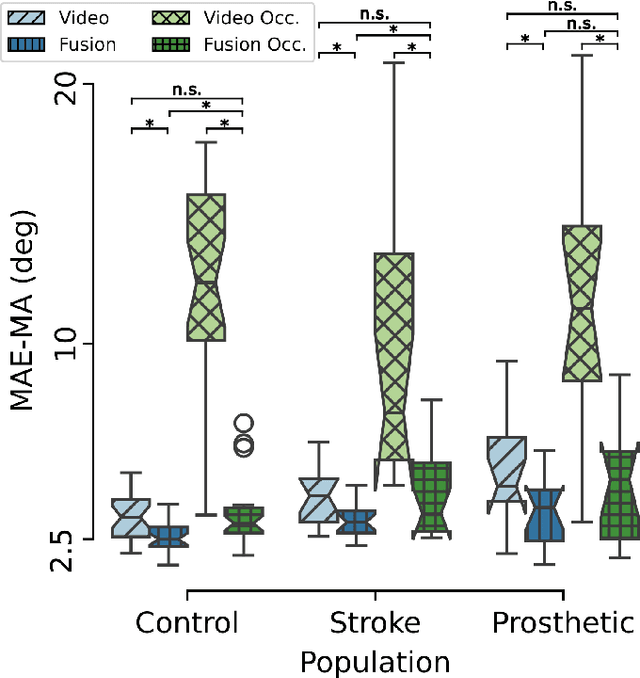
Video and wearable sensor data provide complementary information about human movement. Video provides a holistic understanding of the entire body in the world while wearable sensors provide high-resolution measurements of specific body segments. A robust method to fuse these modalities and obtain biomechanically accurate kinematics would have substantial utility for clinical assessment and monitoring. While multiple video-sensor fusion methods exist, most assume that a time-intensive, and often brittle, sensor-body calibration process has already been performed. In this work, we present a method to combine handheld smartphone video and uncalibrated wearable sensor data at their full temporal resolution. Our monocular, video-only, biomechanical reconstruction already performs well, with only several degrees of error at the knee during walking compared to markerless motion capture. Reconstructing from a fusion of video and wearable sensor data further reduces this error. We validate this in a mixture of people with no gait impairments, lower limb prosthesis users, and individuals with a history of stroke. We also show that sensor data allows tracking through periods of visual occlusion.
Platypose: Calibrated Zero-Shot Multi-Hypothesis 3D Human Motion Estimation
Mar 10, 2024



Single camera 3D pose estimation is an ill-defined problem due to inherent ambiguities from depth, occlusion or keypoint noise. Multi-hypothesis pose estimation accounts for this uncertainty by providing multiple 3D poses consistent with the 2D measurements. Current research has predominantly concentrated on generating multiple hypotheses for single frame static pose estimation. In this study we focus on the new task of multi-hypothesis motion estimation. Motion estimation is not simply pose estimation applied to multiple frames, which would ignore temporal correlation across frames. Instead, it requires distributions which are capable of generating temporally consistent samples, which is significantly more challenging. To this end, we introduce Platypose, a framework that uses a diffusion model pretrained on 3D human motion sequences for zero-shot 3D pose sequence estimation. Platypose outperforms baseline methods on multiple hypotheses for motion estimation. Additionally, Platypose also achieves state-of-the-art calibration and competitive joint error when tested on static poses from Human3.6M, MPI-INF-3DHP and 3DPW. Finally, because it is zero-shot, our method generalizes flexibly to different settings such as multi-camera inference.
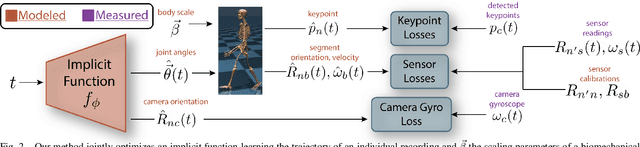
Differentiable Biomechanics Unlocks Opportunities for Markerless Motion Capture
Feb 27, 2024

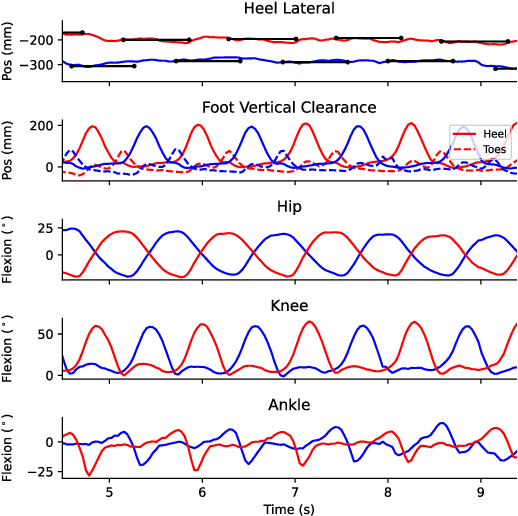
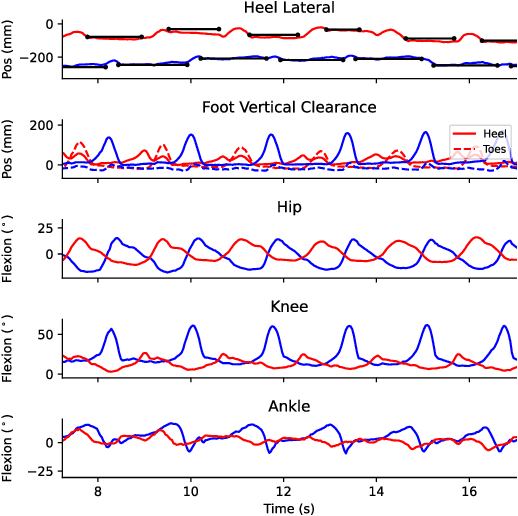
Recent developments have created differentiable physics simulators designed for machine learning pipelines that can be accelerated on a GPU. While these can simulate biomechanical models, these opportunities have not been exploited for biomechanics research or markerless motion capture. We show that these simulators can be used to fit inverse kinematics to markerless motion capture data, including scaling the model to fit the anthropomorphic measurements of an individual. This is performed end-to-end with an implicit representation of the movement trajectory, which is propagated through the forward kinematic model to minimize the error from the 3D markers reprojected into the images. The differential optimizer yields other opportunities, such as adding bundle adjustment during trajectory optimization to refine the extrinsic camera parameters or meta-optimization to improve the base model jointly over trajectories from multiple participants. This approach improves the reprojection error from markerless motion capture over prior methods and produces accurate spatial step parameters compared to an instrumented walkway for control and clinical populations.