 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniMouse: Scaling properties of multi-modal, multi-task Brain Models on 150B Neural Tokens
Apr 20, 2026Scaling data and artificial neural networks has transformed AI, driving breakthroughs in language and vision. Whether similar principles apply to modeling brain activity remains unclear. Here we leveraged a dataset of 3.1 million neurons from the visual cortex of 73 mice across 323 sessions, totaling more than 150 billion neural tokens recorded during natural movies, images and parametric stimuli, and behavior. We train multi-modal, multi-task models that support three regimes flexibly at test time: neural prediction, behavioral decoding, neural forecasting, or any combination of the three. OmniMouse achieves state-of-the-art performance, outperforming specialized baselines across nearly all evaluation regimes. We find that performance scales reliably with more data, but gains from increasing model size saturate. This inverts the standard AI scaling story: in language and computer vision, massive datasets make parameter scaling the primary driver of progress, whereas in brain modeling -- even in the mouse visual cortex, a relatively simple system -- models remain data-limited despite vast recordings. The observation of systematic scaling raises the possibility of phase transitions in neural modeling, where larger and richer datasets might unlock qualitatively new capabilities, paralleling the emergent properties seen in large language models. Code available at https://github.com/enigma-brain/omnimouse.
Similarity as Reward Alignment: Robust and Versatile Preference-based Reinforcement Learning
Jun 14, 2025Preference-based Reinforcement Learning (PbRL) entails a variety of approaches for aligning models with human intent to alleviate the burden of reward engineering. However, most previous PbRL work has not investigated the robustness to labeler errors, inevitable with labelers who are non-experts or operate under time constraints. Additionally, PbRL algorithms often target very specific settings (e.g. pairwise ranked preferences or purely offline learning). We introduce Similarity as Reward Alignment (SARA), a simple contrastive framework that is both resilient to noisy labels and adaptable to diverse feedback formats and training paradigms. SARA learns a latent representation of preferred samples and computes rewards as similarities to the learned latent. We demonstrate strong performance compared to baselines on continuous control offline RL benchmarks. We further demonstrate SARA's versatility in applications such as trajectory filtering for downstream tasks, cross-task preference transfer, and reward shaping in online learning.
Modeling dynamic neural activity by combining naturalistic video stimuli and stimulus-independent latent factors
Oct 21, 2024Understanding how the brain processes dynamic natural stimuli remains a fundamental challenge in neuroscience. Current dynamic neural encoding models either take stimuli as input but ignore shared variability in neural responses, or they model this variability by deriving latent embeddings from neural responses or behavior while ignoring the visual input. To address this gap, we propose a probabilistic model that incorporates video inputs along with stimulus-independent latent factors to capture variability in neuronal responses, predicting a joint distribution for the entire population. After training and testing our model on mouse V1 neuronal responses, we found that it outperforms video-only models in terms of log-likelihood and achieves further improvements when conditioned on responses from other neurons. Furthermore, we find that the learned latent factors strongly correlate with mouse behavior, although the model was trained without behavior data.
Platypose: Calibrated Zero-Shot Multi-Hypothesis 3D Human Motion Estimation
Mar 10, 2024



Single camera 3D pose estimation is an ill-defined problem due to inherent ambiguities from depth, occlusion or keypoint noise. Multi-hypothesis pose estimation accounts for this uncertainty by providing multiple 3D poses consistent with the 2D measurements. Current research has predominantly concentrated on generating multiple hypotheses for single frame static pose estimation. In this study we focus on the new task of multi-hypothesis motion estimation. Motion estimation is not simply pose estimation applied to multiple frames, which would ignore temporal correlation across frames. Instead, it requires distributions which are capable of generating temporally consistent samples, which is significantly more challenging. To this end, we introduce Platypose, a framework that uses a diffusion model pretrained on 3D human motion sequences for zero-shot 3D pose sequence estimation. Platypose outperforms baseline methods on multiple hypotheses for motion estimation. Additionally, Platypose also achieves state-of-the-art calibration and competitive joint error when tested on static poses from Human3.6M, MPI-INF-3DHP and 3DPW. Finally, because it is zero-shot, our method generalizes flexibly to different settings such as multi-camera inference.
HARD: Hard Augmentations for Robust Distillation
May 25, 2023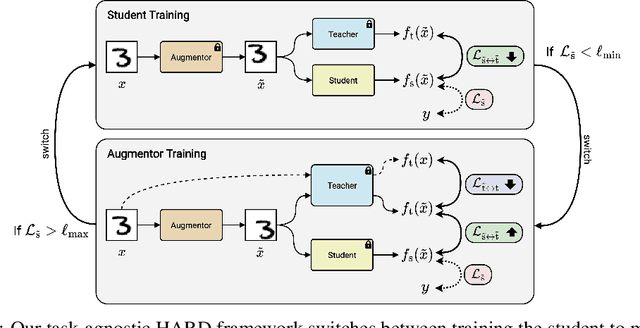
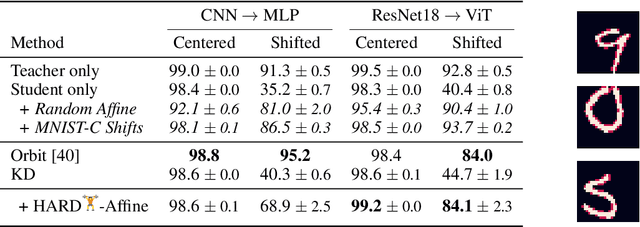
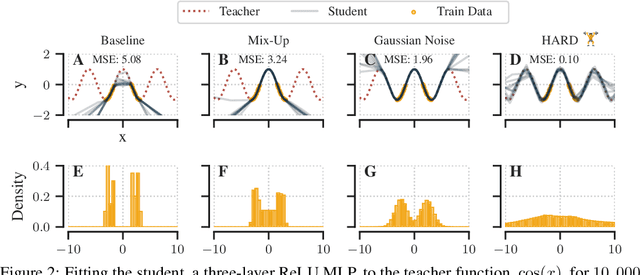
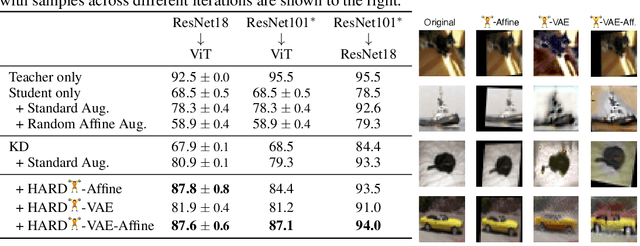
Knowledge distillation (KD) is a simple and successful method to transfer knowledge from a teacher to a student model solely based on functional activity. However, current KD has a few shortcomings: it has recently been shown that this method is unsuitable to transfer simple inductive biases like shift equivariance, struggles to transfer out of domain generalization, and optimization time is magnitudes longer compared to default non-KD model training. To improve these aspects of KD, we propose Hard Augmentations for Robust Distillation (HARD), a generally applicable data augmentation framework, that generates synthetic data points for which the teacher and the student disagree. We show in a simple toy example that our augmentation framework solves the problem of transferring simple equivariances with KD. We then apply our framework in real-world tasks for a variety of augmentation models, ranging from simple spatial transformations to unconstrained image manipulations with a pretrained variational autoencoder. We find that our learned augmentations significantly improve KD performance on in-domain and out-of-domain evaluation. Moreover, our method outperforms even state-of-the-art data augmentations and since the augmented training inputs can be visualized, they offer a qualitative insight into the properties that are transferred from the teacher to the student. Thus HARD represents a generally applicable, dynamically optimized data augmentation technique tailored to improve the generalization and convergence speed of models trained with KD.
Multi-hypothesis 3D human pose estimation metrics favor miscalibrated distributions
Oct 20, 2022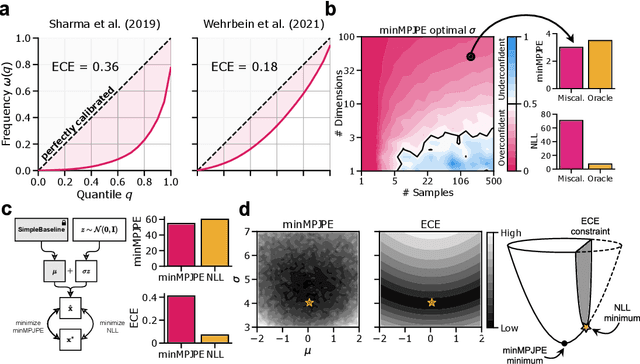
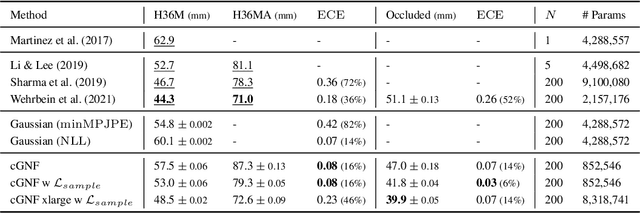
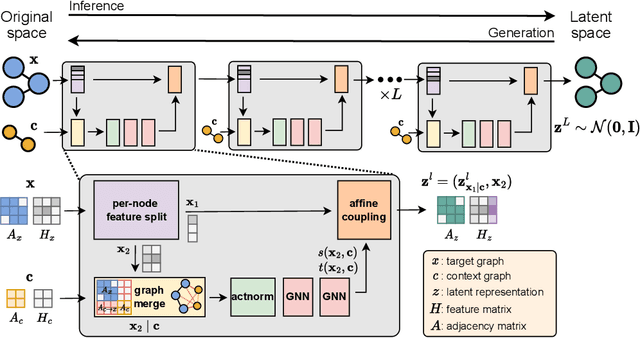
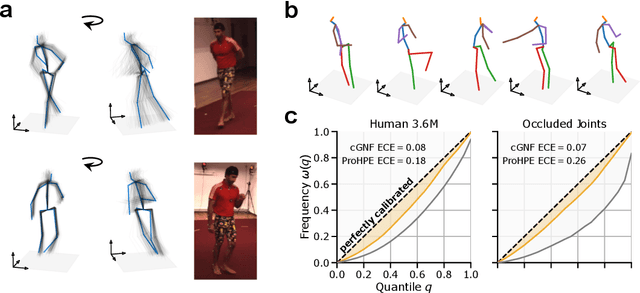
Due to depth ambiguities and occlusions, lifting 2D poses to 3D is a highly ill-posed problem. Well-calibrated distributions of possible poses can make these ambiguities explicit and preserve the resulting uncertainty for downstream tasks. This study shows that previous attempts, which account for these ambiguities via multiple hypotheses generation, produce miscalibrated distributions. We identify that miscalibration can be attributed to the use of sample-based metrics such as minMPJPE. In a series of simulations, we show that minimizing minMPJPE, as commonly done, should converge to the correct mean prediction. However, it fails to correctly capture the uncertainty, thus resulting in a miscalibrated distribution. To mitigate this problem, we propose an accurate and well-calibrated model called Conditional Graph Normalizing Flow (cGNFs). Our model is structured such that a single cGNF can estimate both conditional and marginal densities within the same model - effectively solving a zero-shot density estimation problem. We evaluate cGNF on the Human~3.6M dataset and show that cGNF provides a well-calibrated distribution estimate while being close to state-of-the-art in terms of overall minMPJPE. Furthermore, cGNF outperforms previous methods on occluded joints while it remains well-calibrated.
The Sensorium competition on predicting large-scale mouse primary visual cortex activity
Jun 17, 2022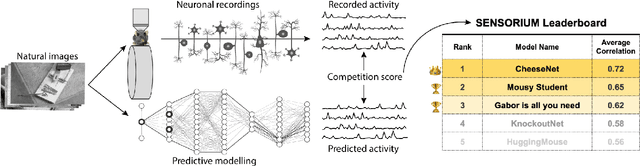
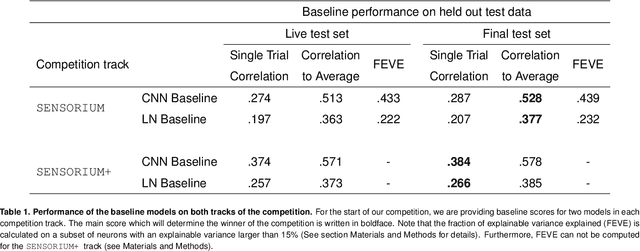
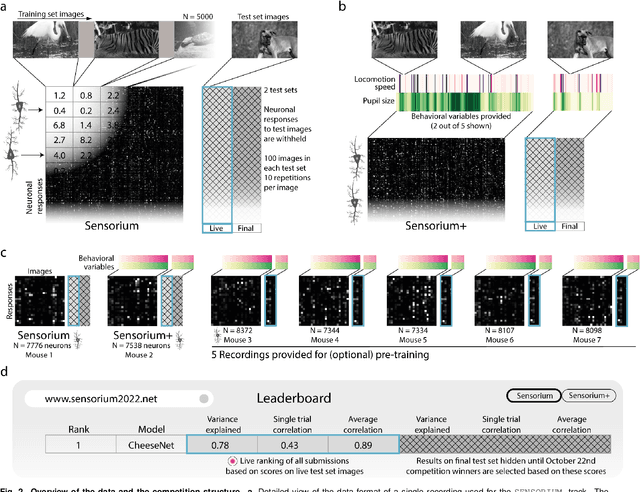
The neural underpinning of the biological visual system is challenging to study experimentally, in particular as the neuronal activity becomes increasingly nonlinear with respect to visual input. Artificial neural networks (ANNs) can serve a variety of goals for improving our understanding of this complex system, not only serving as predictive digital twins of sensory cortex for novel hypothesis generation in silico, but also incorporating bio-inspired architectural motifs to progressively bridge the gap between biological and machine vision. The mouse has recently emerged as a popular model system to study visual information processing, but no standardized large-scale benchmark to identify state-of-the-art models of the mouse visual system has been established. To fill this gap, we propose the Sensorium benchmark competition. We collected a large-scale dataset from mouse primary visual cortex containing the responses of more than 28,000 neurons across seven mice stimulated with thousands of natural images, together with simultaneous behavioral measurements that include running speed, pupil dilation, and eye movements. The benchmark challenge will rank models based on predictive performance for neuronal responses on a held-out test set, and includes two tracks for model input limited to either stimulus only (Sensorium) or stimulus plus behavior (Sensorium+). We provide a starting kit to lower the barrier for entry, including tutorials, pre-trained baseline models, and APIs with one line commands for data loading and submission. We would like to see this as a starting point for regular challenges and data releases, and as a standard tool for measuring progress in large-scale neural system identification models of the mouse visual system and beyond.
Towards robust vision by multi-task learning on monkey visual cortex
Jul 29, 2021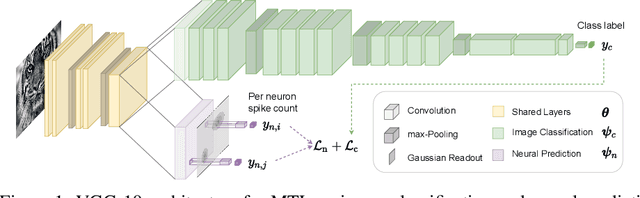
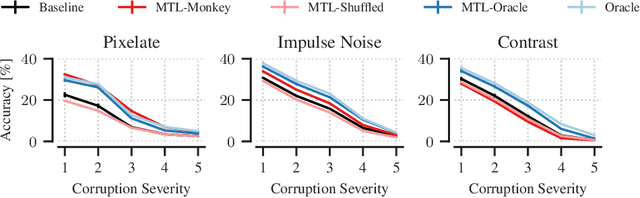
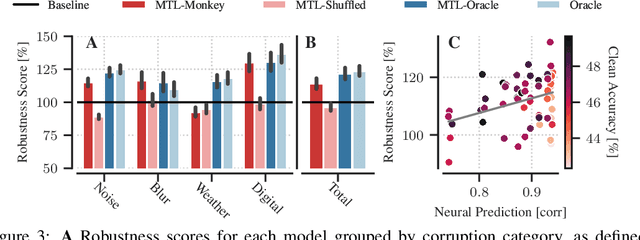
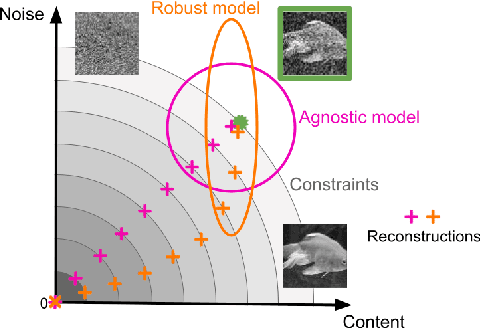
Deep neural networks set the state-of-the-art across many tasks in computer vision, but their generalization ability to image distortions is surprisingly fragile. In contrast, the mammalian visual system is robust to a wide range of perturbations. Recent work suggests that this generalization ability can be explained by useful inductive biases encoded in the representations of visual stimuli throughout the visual cortex. Here, we successfully leveraged these inductive biases with a multi-task learning approach: we jointly trained a deep network to perform image classification and to predict neural activity in macaque primary visual cortex (V1). We measured the out-of-distribution generalization abilities of our network by testing its robustness to image distortions. We found that co-training on monkey V1 data leads to increased robustness despite the absence of those distortions during training. Additionally, we showed that our network's robustness is very close to that of an Oracle network where parts of the architecture are directly trained on noisy images. Our results also demonstrated that the network's representations become more brain-like as their robustness improves. Using a novel constrained reconstruction analysis, we investigated what makes our brain-regularized network more robust. We found that our co-trained network is more sensitive to content than noise when compared to a Baseline network that we trained for image classification alone. Using DeepGaze-predicted saliency maps for ImageNet images, we found that our monkey co-trained network tends to be more sensitive to salient regions in a scene, reminiscent of existing theories on the role of V1 in the detection of object borders and bottom-up saliency. Overall, our work expands the promising research avenue of transferring inductive biases from the brain, and provides a novel analysis of the effects of our transfer.
Factorized Neural Processes for Neural Processes: $K$-Shot Prediction of Neural Responses
Oct 22, 2020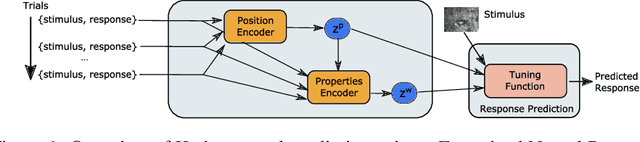

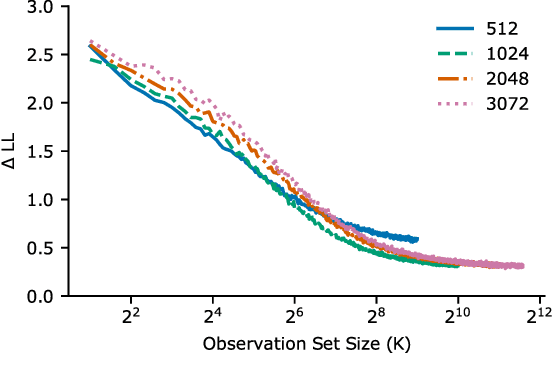
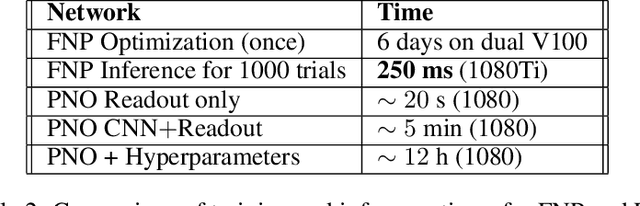
In recent years, artificial neural networks have achieved state-of-the-art performance for predicting the responses of neurons in the visual cortex to natural stimuli. However, they require a time consuming parameter optimization process for accurately modeling the tuning function of newly observed neurons, which prohibits many applications including real-time, closed-loop experiments. We overcome this limitation by formulating the problem as $K$-shot prediction to directly infer a neuron's tuning function from a small set of stimulus-response pairs using a Neural Process. This required us to developed a Factorized Neural Process, which embeds the observed set into a latent space partitioned into the receptive field location and the tuning function properties. We show on simulated responses that the predictions and reconstructed receptive fields from the Factorized Neural Process approach ground truth with increasing number of trials. Critically, the latent representation that summarizes the tuning function of a neuron is inferred in a quick, single forward pass through the network. Finally, we validate this approach on real neural data from visual cortex and find that the predictive accuracy is comparable to -- and for small $K$ even greater than -- optimization based approaches, while being substantially faster. We believe this novel deep learning systems identification framework will facilitate better real-time integration of artificial neural network modeling into neuroscience experiments.
Learning From Brains How to Regularize Machines
Nov 11, 2019
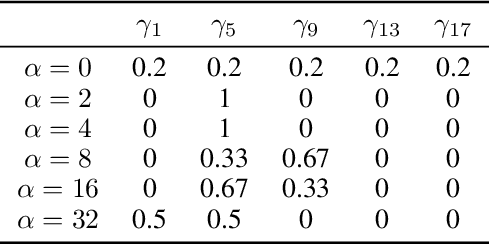

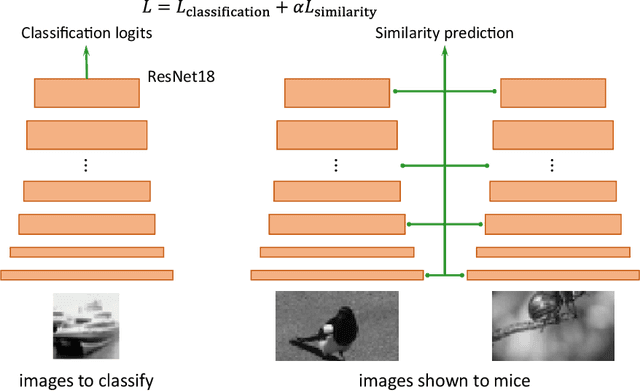
Despite impressive performance on numerous visual tasks, Convolutional Neural Networks (CNNs) --- unlike brains --- are often highly sensitive to small perturbations of their input, e.g. adversarial noise leading to erroneous decisions. We propose to regularize CNNs using large-scale neuroscience data to learn more robust neural features in terms of representational similarity. We presented natural images to mice and measured the responses of thousands of neurons from cortical visual areas. Next, we denoised the notoriously variable neural activity using strong predictive models trained on this large corpus of responses from the mouse visual system, and calculated the representational similarity for millions of pairs of images from the model's predictions. We then used the neural representation similarity to regularize CNNs trained on image classification by penalizing intermediate representations that deviated from neural ones. This preserved performance of baseline models when classifying images under standard benchmarks, while maintaining substantially higher performance compared to baseline or control models when classifying noisy images. Moreover, the models regularized with cortical representations also improved model robustness in terms of adversarial attacks. This demonstrates that regularizing with neural data can be an effective tool to create an inductive bias towards more robust inference.