 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHARD: Hard Augmentations for Robust Distillation
Paper and Code
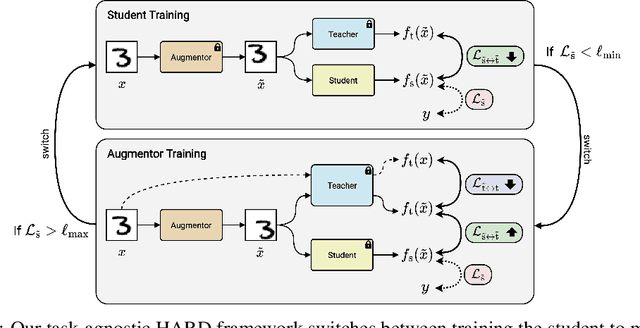
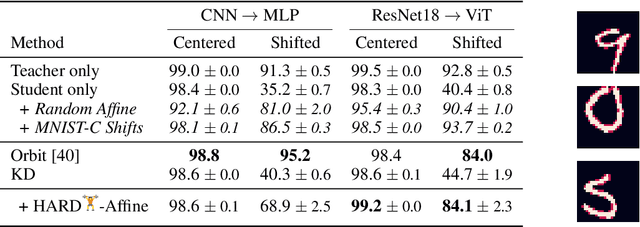
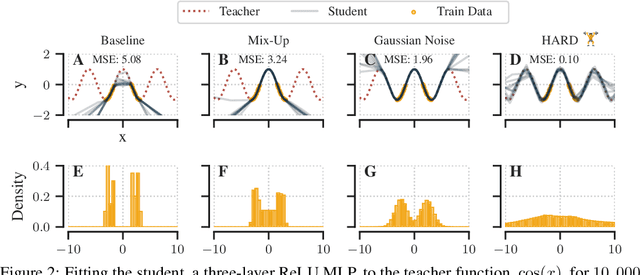
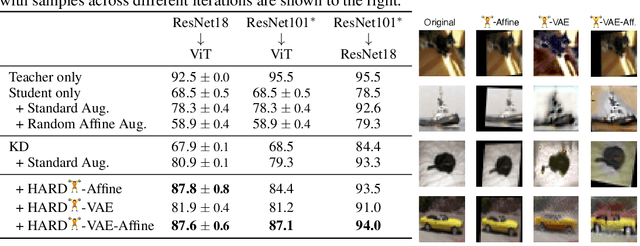
Knowledge distillation (KD) is a simple and successful method to transfer knowledge from a teacher to a student model solely based on functional activity. However, current KD has a few shortcomings: it has recently been shown that this method is unsuitable to transfer simple inductive biases like shift equivariance, struggles to transfer out of domain generalization, and optimization time is magnitudes longer compared to default non-KD model training. To improve these aspects of KD, we propose Hard Augmentations for Robust Distillation (HARD), a generally applicable data augmentation framework, that generates synthetic data points for which the teacher and the student disagree. We show in a simple toy example that our augmentation framework solves the problem of transferring simple equivariances with KD. We then apply our framework in real-world tasks for a variety of augmentation models, ranging from simple spatial transformations to unconstrained image manipulations with a pretrained variational autoencoder. We find that our learned augmentations significantly improve KD performance on in-domain and out-of-domain evaluation. Moreover, our method outperforms even state-of-the-art data augmentations and since the augmented training inputs can be visualized, they offer a qualitative insight into the properties that are transferred from the teacher to the student. Thus HARD represents a generally applicable, dynamically optimized data augmentation technique tailored to improve the generalization and convergence speed of models trained with KD.