 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning From Brains How to Regularize Machines
Nov 11, 2019
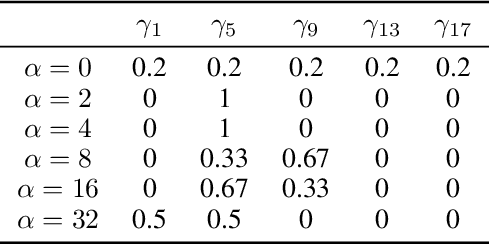

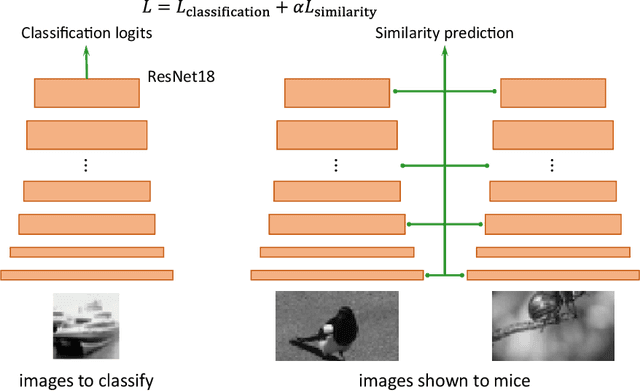
Despite impressive performance on numerous visual tasks, Convolutional Neural Networks (CNNs) --- unlike brains --- are often highly sensitive to small perturbations of their input, e.g. adversarial noise leading to erroneous decisions. We propose to regularize CNNs using large-scale neuroscience data to learn more robust neural features in terms of representational similarity. We presented natural images to mice and measured the responses of thousands of neurons from cortical visual areas. Next, we denoised the notoriously variable neural activity using strong predictive models trained on this large corpus of responses from the mouse visual system, and calculated the representational similarity for millions of pairs of images from the model's predictions. We then used the neural representation similarity to regularize CNNs trained on image classification by penalizing intermediate representations that deviated from neural ones. This preserved performance of baseline models when classifying images under standard benchmarks, while maintaining substantially higher performance compared to baseline or control models when classifying noisy images. Moreover, the models regularized with cortical representations also improved model robustness in terms of adversarial attacks. This demonstrates that regularizing with neural data can be an effective tool to create an inductive bias towards more robust inference.
A rotation-equivariant convolutional neural network model of primary visual cortex
Sep 27, 2018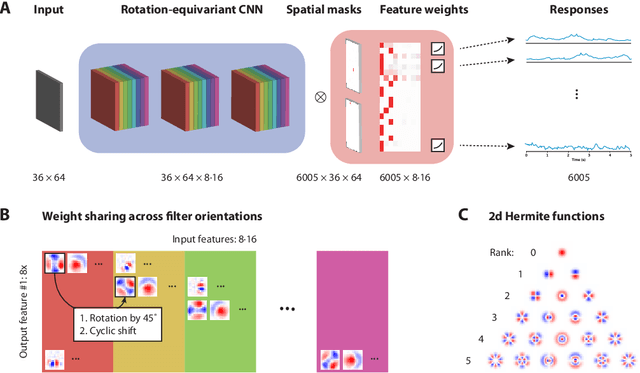
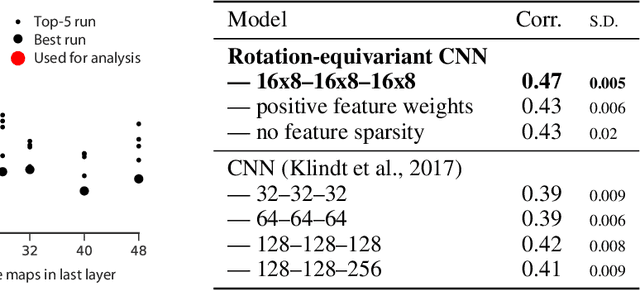
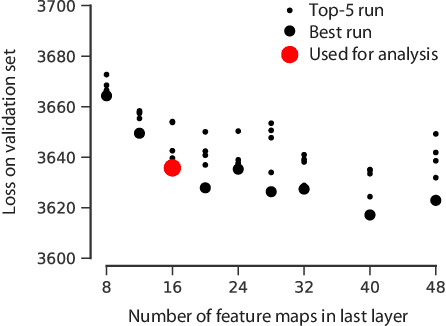
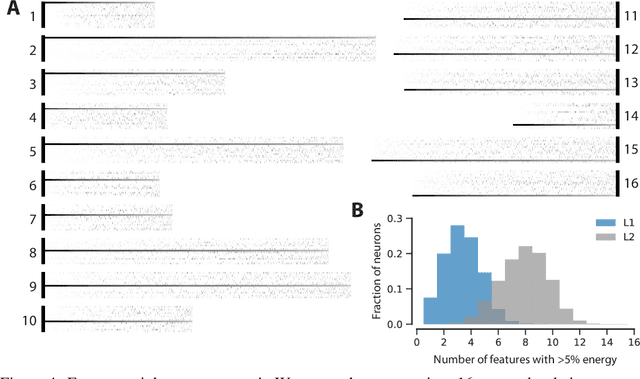
Classical models describe primary visual cortex (V1) as a filter bank of orientation-selective linear-nonlinear (LN) or energy models, but these models fail to predict neural responses to natural stimuli accurately. Recent work shows that models based on convolutional neural networks (CNNs) lead to much more accurate predictions, but it remains unclear which features are extracted by V1 neurons beyond orientation selectivity and phase invariance. Here we work towards systematically studying V1 computations by categorizing neurons into groups that perform similar computations. We present a framework to identify common features independent of individual neurons' orientation selectivity by using a rotation-equivariant convolutional neural network, which automatically extracts every feature at multiple different orientations. We fit this model to responses of a population of 6000 neurons to natural images recorded in mouse primary visual cortex using two-photon imaging. We show that our rotation-equivariant network not only outperforms a regular CNN with the same number of feature maps, but also reveals a number of common features shared by many V1 neurons, which deviate from the typical textbook idea of V1 as a bank of Gabor filters. Our findings are a first step towards a powerful new tool to study the nonlinear computations in V1.
Penalized matrix decomposition for denoising, compression, and improved demixing of functional imaging data
Jul 17, 2018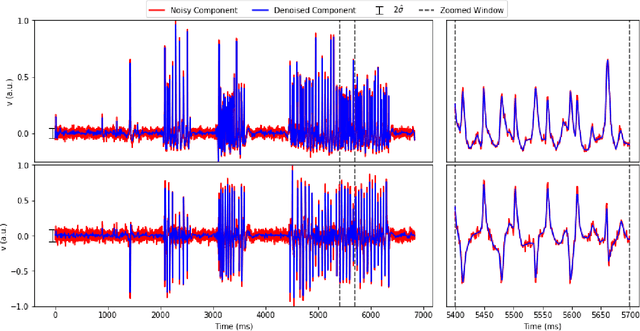
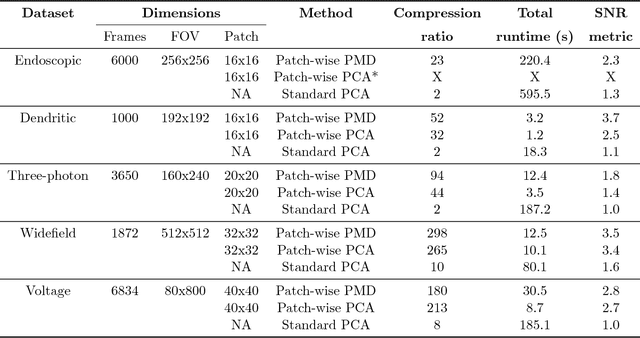

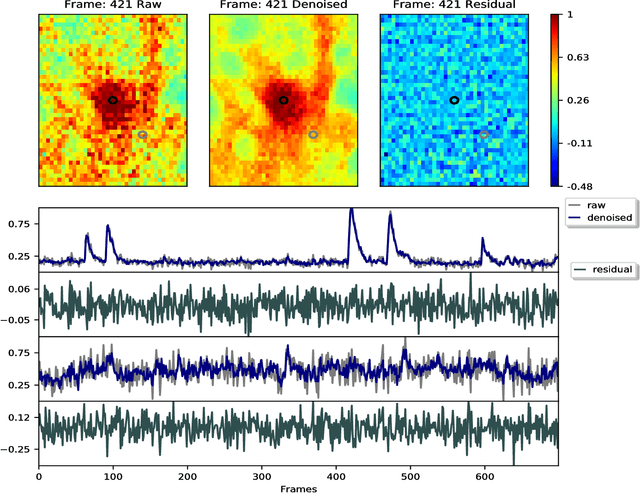
Calcium imaging has revolutionized systems neuroscience, providing the ability to image large neural populations with single-cell resolution. The resulting datasets are quite large, which has presented a barrier to routine open sharing of this data, slowing progress in reproducible research. State of the art methods for analyzing this data are based on non-negative matrix factorization (NMF); these approaches solve a non-convex optimization problem, and are effective when good initializations are available, but can break down in low-SNR settings where common initialization approaches fail. Here we introduce an approach to compressing and denoising functional imaging data. The method is based on a spatially-localized penalized matrix decomposition (PMD) of the data to separate (low-dimensional) signal from (temporally-uncorrelated) noise. This approach can be applied in parallel on local spatial patches and is therefore highly scalable, does not impose non-negativity constraints or require stringent identifiability assumptions (leading to significantly more robust results compared to NMF), and estimates all parameters directly from the data, so no hand-tuning is required. We have applied the method to a wide range of functional imaging data (including one-photon, two-photon, three-photon, widefield, somatic, axonal, dendritic, calcium, and voltage imaging datasets): in all cases, we observe ~2-4x increases in SNR and compression rates of 20-300x with minimal visible loss of signal, with no adjustment of hyperparameters; this in turn facilitates the process of demixing the observed activity into contributions from individual neurons. We focus on two challenging applications: dendritic calcium imaging data and voltage imaging data in the context of optogenetic stimulation. In both cases, we show that our new approach leads to faster and much more robust extraction of activity from the data.
Supervised learning sets benchmark for robust spike detection from calcium imaging signals
Feb 28, 2015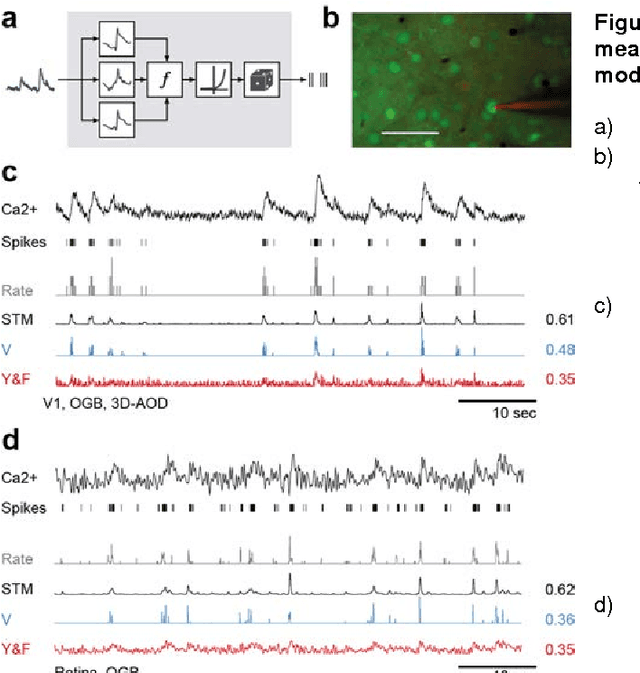

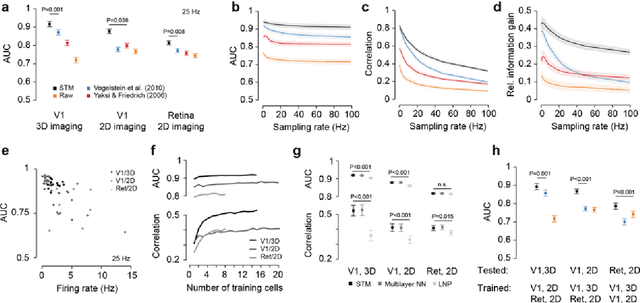
A fundamental challenge in calcium imaging has been to infer the timing of action potentials from the measured noisy calcium fluorescence traces. We systematically evaluate a range of spike inference algorithms on a large benchmark dataset recorded from varying neural tissue (V1 and retina) using different calcium indicators (OGB-1 and GCamp6). We show that a new algorithm based on supervised learning in flexible probabilistic models outperforms all previously published techniques, setting a new standard for spike inference from calcium signals. Importantly, it performs better than other algorithms even on datasets not seen during training. Future data acquired in new experimental conditions can easily be used to further improve its spike prediction accuracy and generalization performance. Finally, we show that comparing algorithms on artificial data is not informative about performance on real population imaging data, suggesting that a benchmark dataset may greatly facilitate future algorithmic developments.