 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHKVM-RAG: Key-Value-Separated Hypergraph Evidence Organization for Multi-Hop RAG
Jun 05, 2026Multi-hop RAG poses a data-engineering problem beyond passage matching: under fixed retrieval budgets, a system must organize retrieved text into evidence units that expose answer chains. Dense retrievers score passages independently, while graph-based memories make associations explicit but often rely on pairwise or entity-centered keys that fragment multi-hop evidence. We present HKVM-RAG, a key-value-separated evidence-organization layer. It assembles answer-path hyperedges from cached passage-level LLM evidence tuples and uses them as retrieval keys, while retaining passage text as answer values. To isolate key-space design, our fixed-substrate protocol holds the tuple cache, candidate passages, reader, and evaluation budget constant across pairwise graph and hypergraph variants. Weighted hypergraph key-value retrieval improves over KG-PPR by +3.426 F1 on 2WikiMultiHopQA and +3.592 F1 on MuSiQue; HotpotQA shows that higher structured support coverage need not yield standalone answer-F1 gains. We therefore study WHG-KV as an evidence-control signal rather than a dense-retrieval replacement. Oracle and train-to-dev analyses identify support selection as repairable, and a dense-aware controller combines frozen ColBERTv2 and HKVM rank/score features using out-of-fold HKVM predictions. It reaches 88.846, 65.073, and 85.810 F1 on the three benchmarks, improving over ColBERTv2 by +11.084, +6.763, and +5.966 F1. Source-level ablations show that matched non-WHG structured signals do not match the WHG-KV gains. These results provide bounded evidence that key-value-separated hypergraph organization can serve as a reusable evidence-control mechanism for multi-hop RAG.
Scalable Mean-Field Variational Inference via Preconditioned Primal-Dual Optimization
Feb 07, 2026In this work, we investigate the large-scale mean-field variational inference (MFVI) problem from a mini-batch primal-dual perspective. By reformulating MFVI as a constrained finite-sum problem, we develop a novel primal-dual algorithm based on an augmented Lagrangian formulation, termed primal-dual variational inference (PD-VI). PD-VI jointly updates global and local variational parameters in the evidence lower bound in a scalable manner. To further account for heterogeneous loss geometry across different variational parameter blocks, we introduce a block-preconditioned extension, P$^2$D-VI, which adapts the primal-dual updates to the geometry of each parameter block and improves both numerical robustness and practical efficiency. We establish convergence guarantees for both PD-VI and P$^2$D-VI under properly chosen constant step size, without relying on conjugacy assumptions or explicit bounded-variance conditions. In particular, we prove $O(1/T)$ convergence to a stationary point in general settings and linear convergence under strong convexity. Numerical experiments on synthetic data and a real large-scale spatial transcriptomics dataset demonstrate that our methods consistently outperform existing stochastic variational inference approaches in terms of convergence speed and solution quality.
Adaptive Diffusion-based Augmentation for Recommendation
Jan 04, 2026Recommendation systems often rely on implicit feedback, where only positive user-item interactions can be observed. Negative sampling is therefore crucial to provide proper negative training signals. However, existing methods tend to mislabel potentially positive but unobserved items as negatives and lack precise control over negative sample selection. We aim to address these by generating controllable negative samples, rather than sampling from the existing item pool. In this context, we propose Adaptive Diffusion-based Augmentation for Recommendation (ADAR), a novel and model-agnostic module that leverages diffusion to synthesize informative negatives. Inspired by the progressive corruption process in diffusion, ADAR simulates a continuous transition from positive to negative, allowing for fine-grained control over sample hardness. To mine suitable negative samples, we theoretically identify the transition point at which a positive sample turns negative and derive a score-aware function to adaptively determine the optimal sampling timestep. By identifying this transition point, ADAR generates challenging negative samples that effectively refine the model's decision boundary. Experiments confirm that ADAR is broadly compatible and boosts the performance of existing recommendation models substantially, including collaborative filtering and sequential recommendation, without architectural modifications.
RTV-Bench: Benchmarking MLLM Continuous Perception, Understanding and Reasoning through Real-Time Video
May 04, 2025Multimodal Large Language Models (MLLMs) increasingly excel at perception, understanding, and reasoning. However, current benchmarks inadequately evaluate their ability to perform these tasks continuously in dynamic, real-world environments. To bridge this gap, we introduce RTV-Bench, a fine-grained benchmark for MLLM real-time video analysis. RTV-Bench uses three key principles: (1) Multi-Timestamp Question Answering (MTQA), where answers evolve with scene changes; (2) Hierarchical Question Structure, combining basic and advanced queries; and (3) Multi-dimensional Evaluation, assessing the ability of continuous perception, understanding, and reasoning. RTV-Bench contains 552 diverse videos (167.2 hours) and 4,631 high-quality QA pairs. We evaluated leading MLLMs, including proprietary (GPT-4o, Gemini 2.0), open-source offline (Qwen2.5-VL, VideoLLaMA3), and open-source real-time (VITA-1.5, InternLM-XComposer2.5-OmniLive) models. Experiment results show open-source real-time models largely outperform offline ones but still trail top proprietary models. Our analysis also reveals that larger model size or higher frame sampling rates do not significantly boost RTV-Bench performance, sometimes causing slight decreases. This underscores the need for better model architectures optimized for video stream processing and long sequences to advance real-time video analysis with MLLMs. Our benchmark toolkit is available at: https://github.com/LJungang/RTV-Bench.
Temporal Causal Discovery in Dynamic Bayesian Networks Using Federated Learning
Dec 13, 2024



Traditionally, learning the structure of a Dynamic Bayesian Network has been centralized, with all data pooled in one location. However, in real-world scenarios, data are often dispersed among multiple parties (e.g., companies, devices) that aim to collaboratively learn a Dynamic Bayesian Network while preserving their data privacy and security. In this study, we introduce a federated learning approach for estimating the structure of a Dynamic Bayesian Network from data distributed horizontally across different parties. We propose a distributed structure learning method that leverages continuous optimization so that only model parameters are exchanged during optimization. Experimental results on synthetic and real datasets reveal that our method outperforms other state-of-the-art techniques, particularly when there are many clients with limited individual sample sizes.
Enabling On-Device LLMs Personalization with Smartphone Sensing
Jul 05, 2024

This demo presents a novel end-to-end framework that combines on-device large language models (LLMs) with smartphone sensing technologies to achieve context-aware and personalized services. The framework addresses critical limitations of current personalization solutions via cloud-based LLMs, such as privacy concerns, latency and cost, and limited personal sensor data. To achieve this, we innovatively proposed deploying LLMs on smartphones with multimodal sensor data and customized prompt engineering, ensuring privacy and enhancing personalization performance through context-aware sensing. A case study involving a university student demonstrated the proposed framework's capability to provide tailored recommendations. In addition, we show that the proposed framework achieves the best trade-off in privacy, performance, latency, cost, battery and energy consumption between on-device and cloud LLMs. Future work aims to integrate more diverse sensor data and conduct large-scale user studies to further refine the personalization. We envision the proposed framework could significantly improve user experiences in various domains such as healthcare, productivity, and entertainment by providing secure, context-aware, and efficient interactions directly on users' devices.
Knowledge Graph Reasoning with Self-supervised Reinforcement Learning
May 22, 2024



Reinforcement learning (RL) is an effective method of finding reasoning pathways in incomplete knowledge graphs (KGs). To overcome the challenges of a large action space, a self-supervised pre-training method is proposed to warm up the policy network before the RL training stage. To alleviate the distributional mismatch issue in general self-supervised RL (SSRL), in our supervised learning (SL) stage, the agent selects actions based on the policy network and learns from generated labels; this self-generation of labels is the intuition behind the name self-supervised. With this training framework, the information density of our SL objective is increased and the agent is prevented from getting stuck with the early rewarded paths. Our self-supervised RL (SSRL) method improves the performance of RL by pairing it with the wide coverage achieved by SL during pretraining, since the breadth of the SL objective makes it infeasible to train an agent with that alone. We show that our SSRL model meets or exceeds current state-of-the-art results on all Hits@k and mean reciprocal rank (MRR) metrics on four large benchmark KG datasets. This SSRL method can be used as a plug-in for any RL architecture for a KGR task. We adopt two RL architectures, i.e., MINERVA and MultiHopKG as our baseline RL models and experimentally show that our SSRL model consistently outperforms both baselines on all of these four KG reasoning tasks. Full code for the paper available at https://github.com/owenonline/Knowledge-Graph-Reasoning-with-Self-supervised-Reinforcement-Learning.
Diverse Motion In-betweening with Dual Posture Stitching
Mar 25, 2023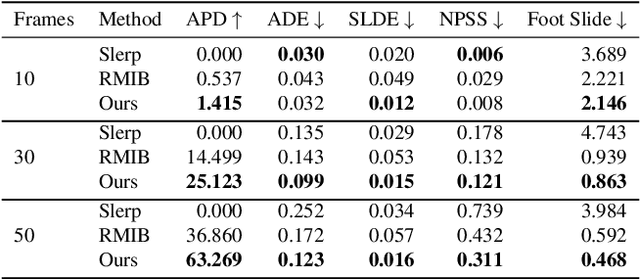
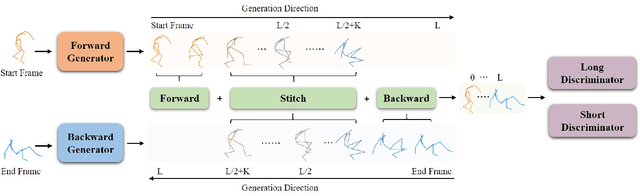
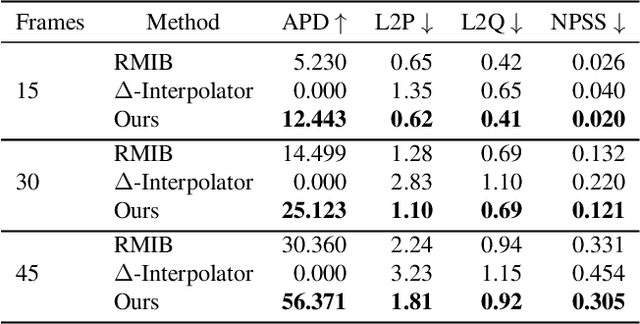
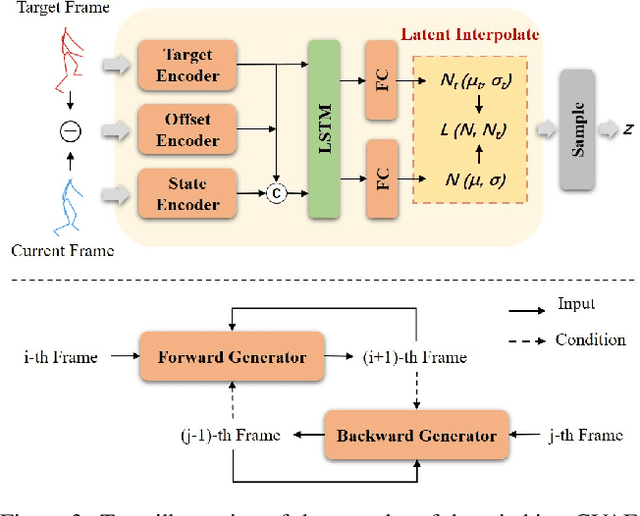
In-betweening is a technique for generating transitions given initial and target character states. The majority of existing works require multiple (often $>$10) frames as input, which are not always accessible. Our work deals with a focused yet challenging problem: to generate the transition when given exactly two frames (only the first and last). To cope with this challenging scenario, we implement our bi-directional scheme which generates forward and backward transitions from the start and end frames with two adversarial autoregressive networks, and stitches them in the middle of the transition where there is no strict ground truth. The autoregressive networks based on conditional variational autoencoders (CVAE) are optimized by searching for a pair of optimal latent codes that minimize a novel stitching loss between their outputs. Results show that our method achieves higher motion quality and more diverse results than existing methods on both the LaFAN1 and Human3.6m datasets.
Lattice-based Improvements for Voice Triggering Using Graph Neural Networks
Jan 25, 2020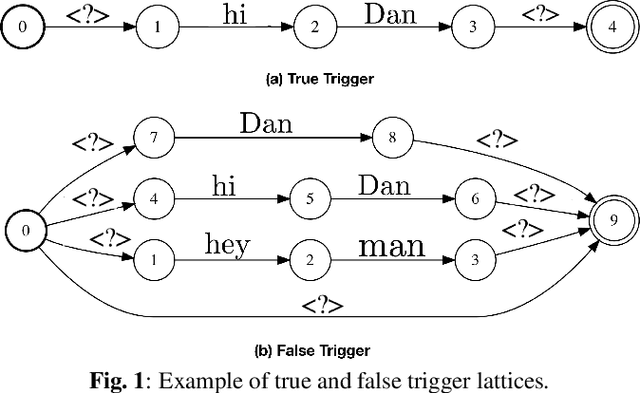
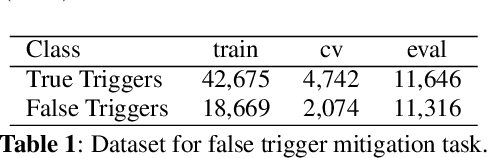
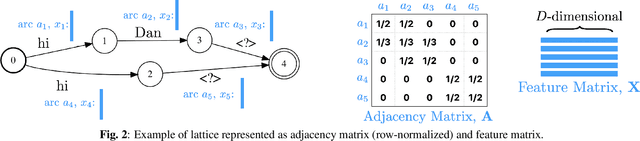

Voice-triggered smart assistants often rely on detection of a trigger-phrase before they start listening for the user request. Mitigation of false triggers is an important aspect of building a privacy-centric non-intrusive smart assistant. In this paper, we address the task of false trigger mitigation (FTM) using a novel approach based on analyzing automatic speech recognition (ASR) lattices using graph neural networks (GNN). The proposed approach uses the fact that decoding lattice of a falsely triggered audio exhibits uncertainties in terms of many alternative paths and unexpected words on the lattice arcs as compared to the lattice of a correctly triggered audio. A pure trigger-phrase detector model doesn't fully utilize the intent of the user speech whereas by using the complete decoding lattice of user audio, we can effectively mitigate speech not intended for the smart assistant. We deploy two variants of GNNs in this paper based on 1) graph convolution layers and 2) self-attention mechanism respectively. Our experiments demonstrate that GNNs are highly accurate in FTM task by mitigating ~87% of false triggers at 99% true positive rate (TPR). Furthermore, the proposed models are fast to train and efficient in parameter requirements.
Penalized matrix decomposition for denoising, compression, and improved demixing of functional imaging data
Jul 17, 2018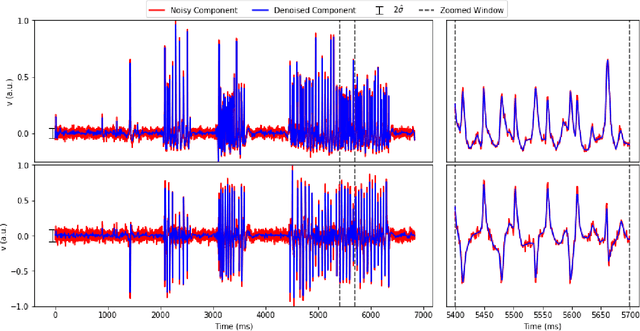
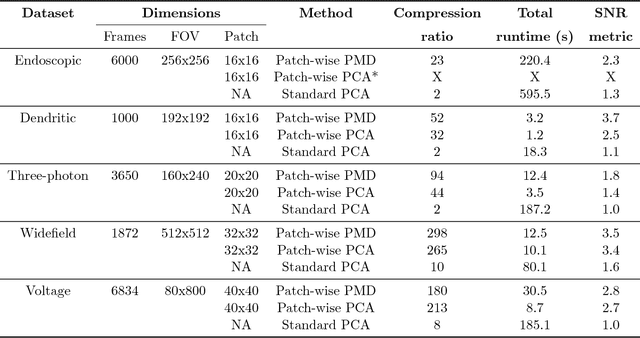

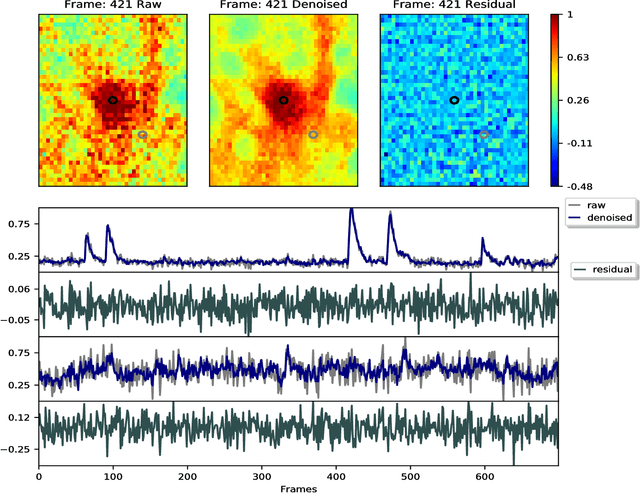
Calcium imaging has revolutionized systems neuroscience, providing the ability to image large neural populations with single-cell resolution. The resulting datasets are quite large, which has presented a barrier to routine open sharing of this data, slowing progress in reproducible research. State of the art methods for analyzing this data are based on non-negative matrix factorization (NMF); these approaches solve a non-convex optimization problem, and are effective when good initializations are available, but can break down in low-SNR settings where common initialization approaches fail. Here we introduce an approach to compressing and denoising functional imaging data. The method is based on a spatially-localized penalized matrix decomposition (PMD) of the data to separate (low-dimensional) signal from (temporally-uncorrelated) noise. This approach can be applied in parallel on local spatial patches and is therefore highly scalable, does not impose non-negativity constraints or require stringent identifiability assumptions (leading to significantly more robust results compared to NMF), and estimates all parameters directly from the data, so no hand-tuning is required. We have applied the method to a wide range of functional imaging data (including one-photon, two-photon, three-photon, widefield, somatic, axonal, dendritic, calcium, and voltage imaging datasets): in all cases, we observe ~2-4x increases in SNR and compression rates of 20-300x with minimal visible loss of signal, with no adjustment of hyperparameters; this in turn facilitates the process of demixing the observed activity into contributions from individual neurons. We focus on two challenging applications: dendritic calcium imaging data and voltage imaging data in the context of optogenetic stimulation. In both cases, we show that our new approach leads to faster and much more robust extraction of activity from the data.