 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graph Reasoning with Self-supervised Reinforcement Learning
May 22, 2024



Reinforcement learning (RL) is an effective method of finding reasoning pathways in incomplete knowledge graphs (KGs). To overcome the challenges of a large action space, a self-supervised pre-training method is proposed to warm up the policy network before the RL training stage. To alleviate the distributional mismatch issue in general self-supervised RL (SSRL), in our supervised learning (SL) stage, the agent selects actions based on the policy network and learns from generated labels; this self-generation of labels is the intuition behind the name self-supervised. With this training framework, the information density of our SL objective is increased and the agent is prevented from getting stuck with the early rewarded paths. Our self-supervised RL (SSRL) method improves the performance of RL by pairing it with the wide coverage achieved by SL during pretraining, since the breadth of the SL objective makes it infeasible to train an agent with that alone. We show that our SSRL model meets or exceeds current state-of-the-art results on all Hits@k and mean reciprocal rank (MRR) metrics on four large benchmark KG datasets. This SSRL method can be used as a plug-in for any RL architecture for a KGR task. We adopt two RL architectures, i.e., MINERVA and MultiHopKG as our baseline RL models and experimentally show that our SSRL model consistently outperforms both baselines on all of these four KG reasoning tasks. Full code for the paper available at https://github.com/owenonline/Knowledge-Graph-Reasoning-with-Self-supervised-Reinforcement-Learning.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Retrieval Augmented End-to-End Spoken Dialog Models
Feb 02, 2024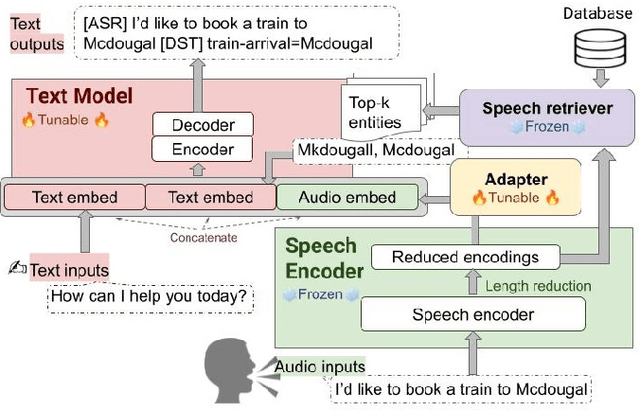
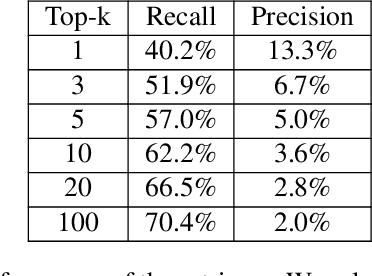

We recently developed SLM, a joint speech and language model, which fuses a pretrained foundational speech model and a large language model (LLM), while preserving the in-context learning capability intrinsic to the pretrained LLM. In this paper, we apply SLM to speech dialog applications where the dialog states are inferred directly from the audio signal. Task-oriented dialogs often contain domain-specific entities, i.e., restaurants, hotels, train stations, and city names, which are difficult to recognize, however, critical for the downstream applications. Inspired by the RAG (retrieval-augmented generation) paradigm, we propose a retrieval augmented SLM (ReSLM) that overcomes this weakness. We first train a speech retriever to retrieve text entities mentioned in the audio. The retrieved entities are then added as text inputs to the underlying SLM to bias model predictions. We evaluated ReSLM on speech MultiWoz task (DSTC-11 challenge), and found that this retrieval augmentation boosts model performance, achieving joint goal accuracy (38.6% vs 32.7%), slot error rate (20.6% vs 24.8%) and ASR word error rate (5.5% vs 6.7%). While demonstrated on dialog state tracking, our approach is broadly applicable to other speech tasks requiring contextual information or domain-specific entities, such as contextual ASR with biasing capability.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Speech-to-Text Adapter and Speech-to-Entity Retriever Augmented LLMs for Speech Understanding
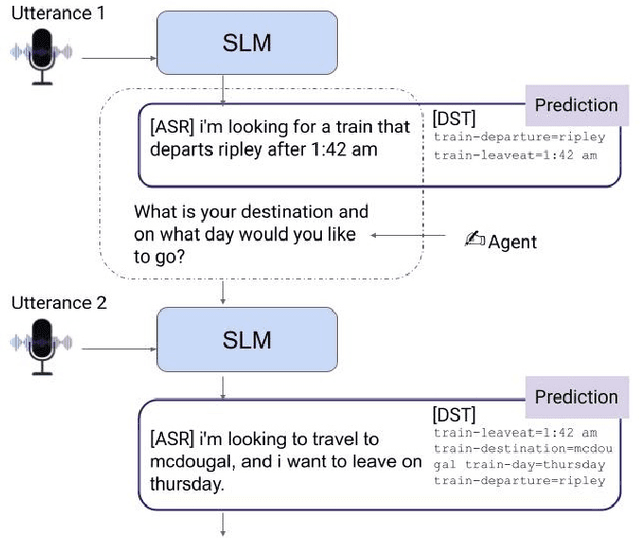
Jun 08, 2023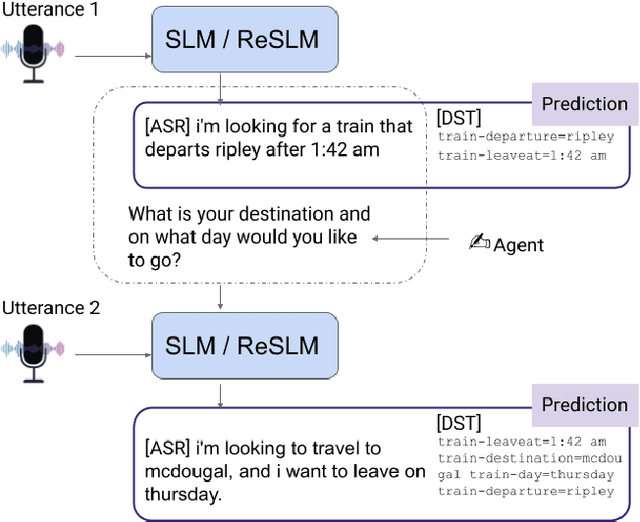



Large Language Models (LLMs) have been applied in the speech domain, often incurring a performance drop due to misaligned between speech and language representations. To bridge this gap, we propose a joint speech and language model (SLM) using a Speech2Text adapter, which maps speech into text token embedding space without speech information loss. Additionally, using a CTC-based blank-filtering, we can reduce the speech sequence length to that of text. In speech MultiWoz dataset (DSTC11 challenge), SLM largely improves the dialog state tracking (DST) performance (24.7% to 28.4% accuracy). Further to address errors on rare entities, we augment SLM with a Speech2Entity retriever, which uses speech to retrieve relevant entities, and then adds them to the original SLM input as a prefix. With this retrieval-augmented SLM (ReSLM), the DST performance jumps to 34.6% accuracy. Moreover, augmenting the ASR task with the dialog understanding task improves the ASR performance from 9.4% to 8.5% WER.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
Knowledge-grounded Dialog State Tracking
Oct 13, 2022


Knowledge (including structured knowledge such as schema and ontology, and unstructured knowledge such as web corpus) is a critical part of dialog understanding, especially for unseen tasks and domains. Traditionally, such domain-specific knowledge is encoded implicitly into model parameters for the execution of downstream tasks, which makes training inefficient. In addition, such models are not easily transferable to new tasks with different schemas. In this work, we propose to perform dialog state tracking grounded on knowledge encoded externally. We query relevant knowledge of various forms based on the dialog context where such information can ground the prediction of dialog states. We demonstrate superior performance of our proposed method over strong baselines, especially in the few-shot learning setting.
Unsupervised Slot Schema Induction for Task-oriented Dialog
May 09, 2022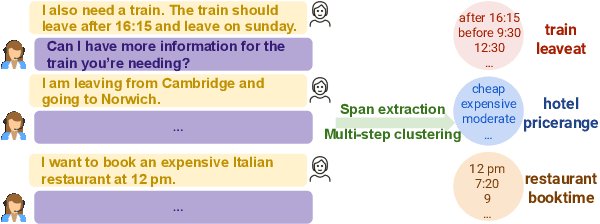

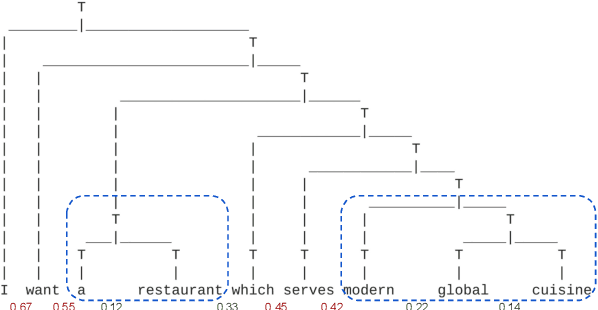

Carefully-designed schemas describing how to collect and annotate dialog corpora are a prerequisite towards building task-oriented dialog systems. In practical applications, manually designing schemas can be error-prone, laborious, iterative, and slow, especially when the schema is complicated. To alleviate this expensive and time consuming process, we propose an unsupervised approach for slot schema induction from unlabeled dialog corpora. Leveraging in-domain language models and unsupervised parsing structures, our data-driven approach extracts candidate slots without constraints, followed by coarse-to-fine clustering to induce slot types. We compare our method against several strong supervised baselines, and show significant performance improvement in slot schema induction on MultiWoz and SGD datasets. We also demonstrate the effectiveness of induced schemas on downstream applications including dialog state tracking and response generation.
Pathways: Asynchronous Distributed Dataflow for ML
Mar 23, 2022

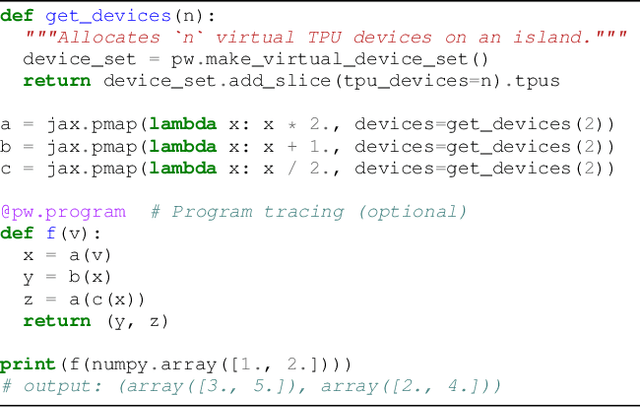

We present the design of a new large scale orchestration layer for accelerators. Our system, Pathways, is explicitly designed to enable exploration of new systems and ML research ideas, while retaining state of the art performance for current models. Pathways uses a sharded dataflow graph of asynchronous operators that consume and produce futures, and efficiently gang-schedules heterogeneous parallel computations on thousands of accelerators while coordinating data transfers over their dedicated interconnects. Pathways makes use of a novel asynchronous distributed dataflow design that lets the control plane execute in parallel despite dependencies in the data plane. This design, with careful engineering, allows Pathways to adopt a single-controller model that makes it easier to express complex new parallelism patterns. We demonstrate that Pathways can achieve performance parity (~100% accelerator utilization) with state-of-the-art systems when running SPMD computations over 2048 TPUs, while also delivering throughput comparable to the SPMD case for Transformer models that are pipelined across 16 stages, or sharded across two islands of accelerators connected over a data center network.
R2D2: Relational Text Decoding with Transformers
May 10, 2021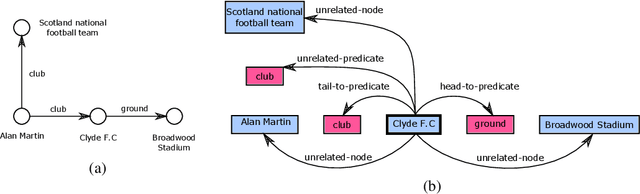
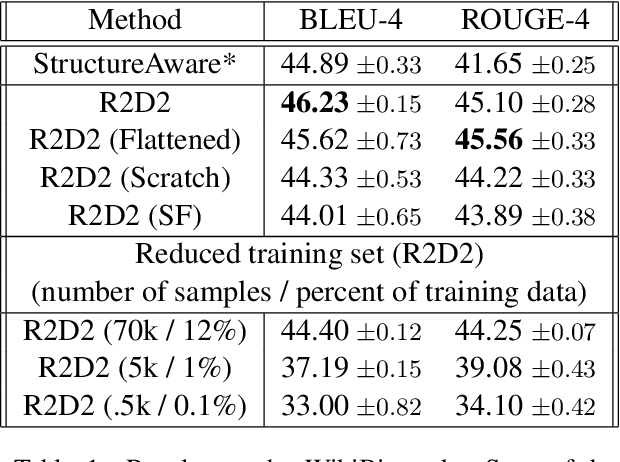
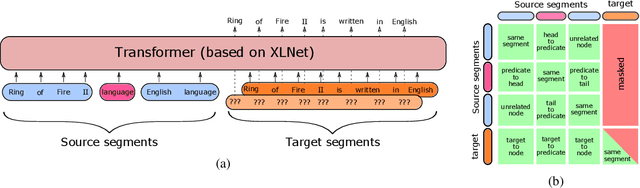
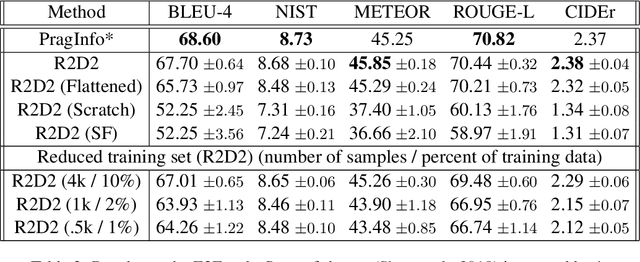
We propose a novel framework for modeling the interaction between graphical structures and the natural language text associated with their nodes and edges. Existing approaches typically fall into two categories. On group ignores the relational structure by converting them into linear sequences and then utilize the highly successful Seq2Seq models. The other side ignores the sequential nature of the text by representing them as fixed-dimensional vectors and apply graph neural networks. Both simplifications lead to information loss. Our proposed method utilizes both the graphical structure as well as the sequential nature of the texts. The input to our model is a set of text segments associated with the nodes and edges of the graph, which are then processed with a transformer encoder-decoder model, equipped with a self-attention mechanism that is aware of the graphical relations between the nodes containing the segments. This also allows us to use BERT-like models that are already trained on large amounts of text. While the proposed model has wide applications, we demonstrate its capabilities on data-to-text generation tasks. Our approach compares favorably against state-of-the-art methods in four tasks without tailoring the model architecture. We also provide an early demonstration in a novel practical application -- generating clinical notes from the medical entities mentioned during clinical visits.