 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech-to-Text Adapter and Speech-to-Entity Retriever Augmented LLMs for Speech Understanding
Paper and Code
Jun 08, 2023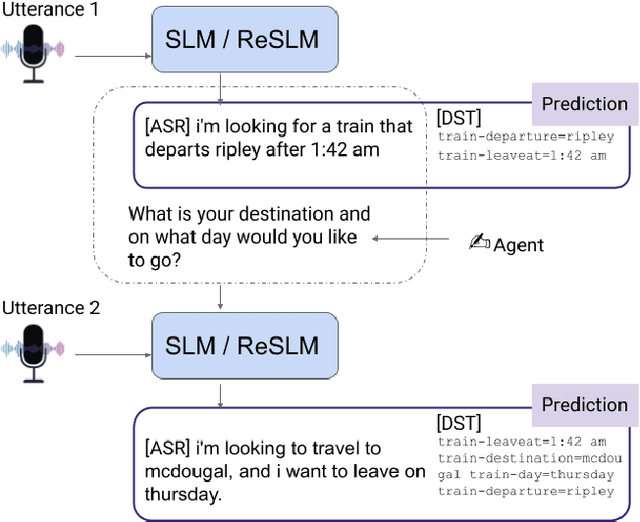



Large Language Models (LLMs) have been applied in the speech domain, often incurring a performance drop due to misaligned between speech and language representations. To bridge this gap, we propose a joint speech and language model (SLM) using a Speech2Text adapter, which maps speech into text token embedding space without speech information loss. Additionally, using a CTC-based blank-filtering, we can reduce the speech sequence length to that of text. In speech MultiWoz dataset (DSTC11 challenge), SLM largely improves the dialog state tracking (DST) performance (24.7% to 28.4% accuracy). Further to address errors on rare entities, we augment SLM with a Speech2Entity retriever, which uses speech to retrieve relevant entities, and then adds them to the original SLM input as a prefix. With this retrieval-augmented SLM (ReSLM), the DST performance jumps to 34.6% accuracy. Moreover, augmenting the ASR task with the dialog understanding task improves the ASR performance from 9.4% to 8.5% WER.