 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graph Reasoning with Self-supervised Reinforcement Learning
May 22, 2024



Reinforcement learning (RL) is an effective method of finding reasoning pathways in incomplete knowledge graphs (KGs). To overcome the challenges of a large action space, a self-supervised pre-training method is proposed to warm up the policy network before the RL training stage. To alleviate the distributional mismatch issue in general self-supervised RL (SSRL), in our supervised learning (SL) stage, the agent selects actions based on the policy network and learns from generated labels; this self-generation of labels is the intuition behind the name self-supervised. With this training framework, the information density of our SL objective is increased and the agent is prevented from getting stuck with the early rewarded paths. Our self-supervised RL (SSRL) method improves the performance of RL by pairing it with the wide coverage achieved by SL during pretraining, since the breadth of the SL objective makes it infeasible to train an agent with that alone. We show that our SSRL model meets or exceeds current state-of-the-art results on all Hits@k and mean reciprocal rank (MRR) metrics on four large benchmark KG datasets. This SSRL method can be used as a plug-in for any RL architecture for a KGR task. We adopt two RL architectures, i.e., MINERVA and MultiHopKG as our baseline RL models and experimentally show that our SSRL model consistently outperforms both baselines on all of these four KG reasoning tasks. Full code for the paper available at https://github.com/owenonline/Knowledge-Graph-Reasoning-with-Self-supervised-Reinforcement-Learning.
Learning to Learn Faster from Human Feedback with Language Model Predictive Control
Feb 18, 2024



Large language models (LLMs) have been shown to exhibit a wide range of capabilities, such as writing robot code from language commands -- enabling non-experts to direct robot behaviors, modify them based on feedback, or compose them to perform new tasks. However, these capabilities (driven by in-context learning) are limited to short-term interactions, where users' feedback remains relevant for only as long as it fits within the context size of the LLM, and can be forgotten over longer interactions. In this work, we investigate fine-tuning the robot code-writing LLMs, to remember their in-context interactions and improve their teachability i.e., how efficiently they adapt to human inputs (measured by average number of corrections before the user considers the task successful). Our key observation is that when human-robot interactions are formulated as a partially observable Markov decision process (in which human language inputs are observations, and robot code outputs are actions), then training an LLM to complete previous interactions can be viewed as training a transition dynamics model -- that can be combined with classic robotics techniques such as model predictive control (MPC) to discover shorter paths to success. This gives rise to Language Model Predictive Control (LMPC), a framework that fine-tunes PaLM 2 to improve its teachability on 78 tasks across 5 robot embodiments -- improving non-expert teaching success rates of unseen tasks by 26.9% while reducing the average number of human corrections from 2.4 to 1.9. Experiments show that LMPC also produces strong meta-learners, improving the success rate of in-context learning new tasks on unseen robot embodiments and APIs by 31.5%. See videos, code, and demos at: https://robot-teaching.github.io/.
Retrieval Augmented End-to-End Spoken Dialog Models
Feb 02, 2024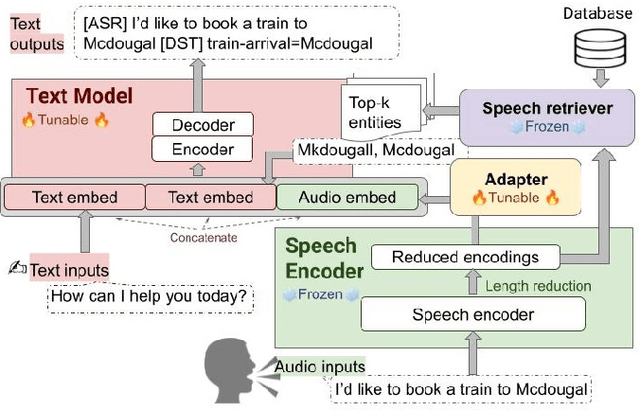
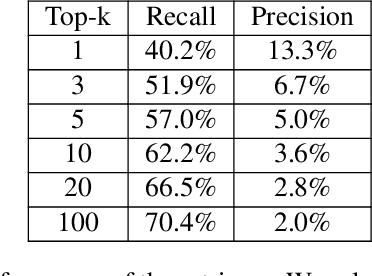

We recently developed SLM, a joint speech and language model, which fuses a pretrained foundational speech model and a large language model (LLM), while preserving the in-context learning capability intrinsic to the pretrained LLM. In this paper, we apply SLM to speech dialog applications where the dialog states are inferred directly from the audio signal. Task-oriented dialogs often contain domain-specific entities, i.e., restaurants, hotels, train stations, and city names, which are difficult to recognize, however, critical for the downstream applications. Inspired by the RAG (retrieval-augmented generation) paradigm, we propose a retrieval augmented SLM (ReSLM) that overcomes this weakness. We first train a speech retriever to retrieve text entities mentioned in the audio. The retrieved entities are then added as text inputs to the underlying SLM to bias model predictions. We evaluated ReSLM on speech MultiWoz task (DSTC-11 challenge), and found that this retrieval augmentation boosts model performance, achieving joint goal accuracy (38.6% vs 32.7%), slot error rate (20.6% vs 24.8%) and ASR word error rate (5.5% vs 6.7%). While demonstrated on dialog state tracking, our approach is broadly applicable to other speech tasks requiring contextual information or domain-specific entities, such as contextual ASR with biasing capability.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
RoboVQA: Multimodal Long-Horizon Reasoning for Robotics
Nov 01, 2023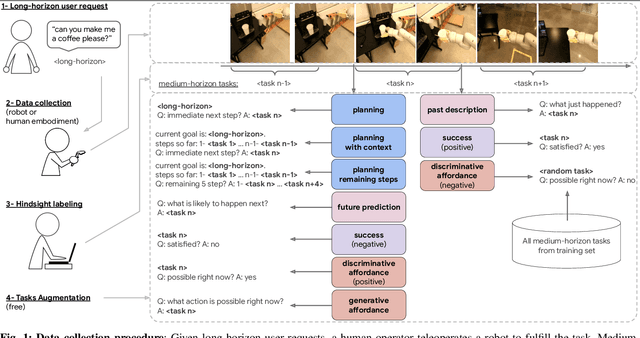

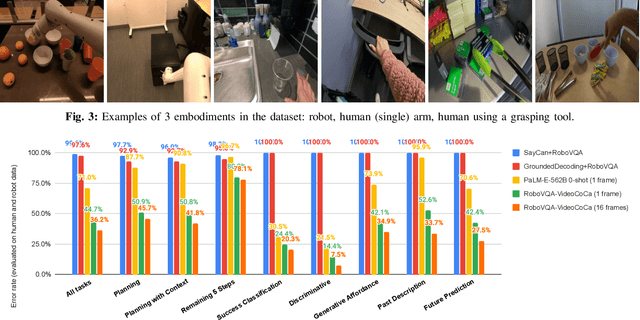
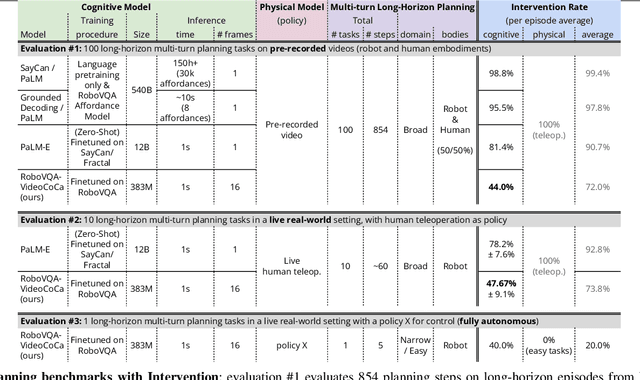
We present a scalable, bottom-up and intrinsically diverse data collection scheme that can be used for high-level reasoning with long and medium horizons and that has 2.2x higher throughput compared to traditional narrow top-down step-by-step collection. We collect realistic data by performing any user requests within the entirety of 3 office buildings and using multiple robot and human embodiments. With this data, we show that models trained on all embodiments perform better than ones trained on the robot data only, even when evaluated solely on robot episodes. We find that for a fixed collection budget it is beneficial to take advantage of cheaper human collection along with robot collection. We release a large and highly diverse (29,520 unique instructions) dataset dubbed RoboVQA containing 829,502 (video, text) pairs for robotics-focused visual question answering. We also demonstrate how evaluating real robot experiments with an intervention mechanism enables performing tasks to completion, making it deployable with human oversight even if imperfect while also providing a single performance metric. We demonstrate a single video-conditioned model named RoboVQA-VideoCoCa trained on our dataset that is capable of performing a variety of grounded high-level reasoning tasks in broad realistic settings with a cognitive intervention rate 46% lower than the zero-shot state of the art visual language model (VLM) baseline and is able to guide real robots through long-horizon tasks. The performance gap with zero-shot state-of-the-art models indicates that a lot of grounded data remains to be collected for real-world deployment, emphasizing the critical need for scalable data collection approaches. Finally, we show that video VLMs significantly outperform single-image VLMs with an average error rate reduction of 19% across all VQA tasks. Data and videos available at https://robovqa.github.io
Detecting Speech Abnormalities with a Perceiver-based Sequence Classifier that Leverages a Universal Speech Model
Oct 16, 2023



We propose a Perceiver-based sequence classifier to detect abnormalities in speech reflective of several neurological disorders. We combine this classifier with a Universal Speech Model (USM) that is trained (unsupervised) on 12 million hours of diverse audio recordings. Our model compresses long sequences into a small set of class-specific latent representations and a factorized projection is used to predict different attributes of the disordered input speech. The benefit of our approach is that it allows us to model different regions of the input for different classes and is at the same time data efficient. We evaluated the proposed model extensively on a curated corpus from the Mayo Clinic. Our model outperforms standard transformer (80.9%) and perceiver (81.8%) models and achieves an average accuracy of 83.1%. With limited task-specific data, we find that pretraining is important and surprisingly pretraining with the unrelated automatic speech recognition (ASR) task is also beneficial. Encodings from the middle layers provide a mix of both acoustic and phonetic information and achieve best prediction results compared to just using the final layer encodings (83.1% vs. 79.6%). The results are promising and with further refinements may help clinicians detect speech abnormalities without needing access to highly specialized speech-language pathologists.
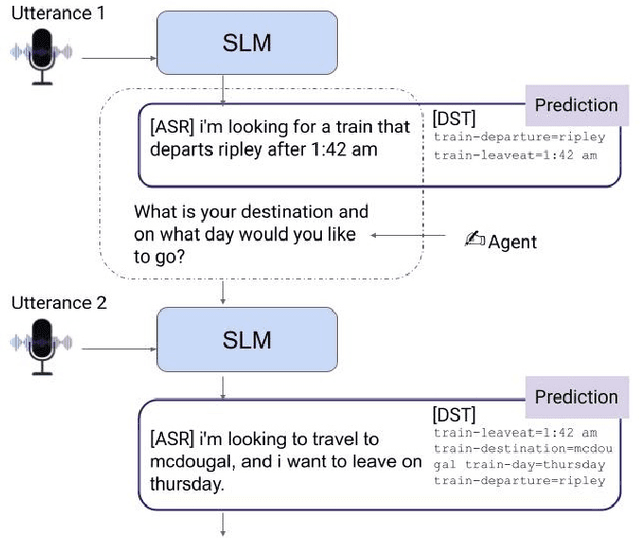
SLM: Bridge the thin gap between speech and text foundation models
Sep 30, 2023



We present a joint Speech and Language Model (SLM), a multitask, multilingual, and dual-modal model that takes advantage of pretrained foundational speech and language models. SLM freezes the pretrained foundation models to maximally preserves their capabilities, and only trains a simple adapter with just 1\% (156M) of the foundation models' parameters. This adaptation not only leads SLM to achieve strong performance on conventional tasks such as speech recognition (ASR) and speech translation (AST), but also introduces the novel capability of zero-shot instruction-following for more diverse tasks: given a speech input and a text instruction, SLM is able to perform unseen generation tasks including contextual biasing ASR using real-time context, dialog generation, speech continuation, and question answering, etc. Our approach demonstrates that the representational gap between pretrained speech and language models might be narrower than one would expect, and can be bridged by a simple adaptation mechanism. As a result, SLM is not only efficient to train, but also inherits strong capabilities already acquired in foundation models of different modalities.
Efficient Adapters for Giant Speech Models
Jun 13, 2023
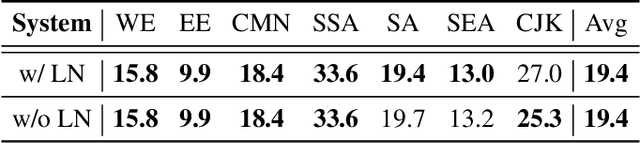


Large pre-trained speech models are widely used as the de-facto paradigm, especially in scenarios when there is a limited amount of labeled data available. However, finetuning all parameters from the self-supervised learned model can be computationally expensive, and becomes infeasiable as the size of the model and the number of downstream tasks scales. In this paper, we propose a novel approach called Two Parallel Adapter (TPA) that is inserted into the conformer-based model pre-trained model instead. TPA is based on systematic studies of the residual adapter, a popular approach for finetuning a subset of parameters. We evaluate TPA on various public benchmarks and experiment results demonstrates its superior performance, which is close to the full finetuning on different datasets and speech tasks. These results show that TPA is an effective and efficient approach for serving large pre-trained speech models. Ablation studies show that TPA can also be pruned, especially for lower blocks.
Speech-to-Text Adapter and Speech-to-Entity Retriever Augmented LLMs for Speech Understanding
Jun 08, 2023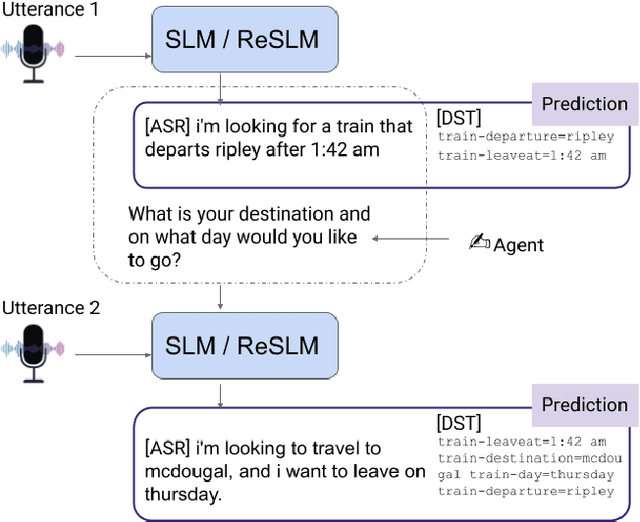



Large Language Models (LLMs) have been applied in the speech domain, often incurring a performance drop due to misaligned between speech and language representations. To bridge this gap, we propose a joint speech and language model (SLM) using a Speech2Text adapter, which maps speech into text token embedding space without speech information loss. Additionally, using a CTC-based blank-filtering, we can reduce the speech sequence length to that of text. In speech MultiWoz dataset (DSTC11 challenge), SLM largely improves the dialog state tracking (DST) performance (24.7% to 28.4% accuracy). Further to address errors on rare entities, we augment SLM with a Speech2Entity retriever, which uses speech to retrieve relevant entities, and then adds them to the original SLM input as a prefix. With this retrieval-augmented SLM (ReSLM), the DST performance jumps to 34.6% accuracy. Moreover, augmenting the ASR task with the dialog understanding task improves the ASR performance from 9.4% to 8.5% WER.
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
May 17, 2023



Language models are increasingly being deployed for general problem solving across a wide range of tasks, but are still confined to token-level, left-to-right decision-making processes during inference. This means they can fall short in tasks that require exploration, strategic lookahead, or where initial decisions play a pivotal role. To surmount these challenges, we introduce a new framework for language model inference, Tree of Thoughts (ToT), which generalizes over the popular Chain of Thought approach to prompting language models, and enables exploration over coherent units of text (thoughts) that serve as intermediate steps toward problem solving. ToT allows LMs to perform deliberate decision making by considering multiple different reasoning paths and self-evaluating choices to decide the next course of action, as well as looking ahead or backtracking when necessary to make global choices. Our experiments show that ToT significantly enhances language models' problem-solving abilities on three novel tasks requiring non-trivial planning or search: Game of 24, Creative Writing, and Mini Crosswords. For instance, in Game of 24, while GPT-4 with chain-of-thought prompting only solved 4% of tasks, our method achieved a success rate of 74%. Code repo with all prompts: https://github.com/ysymyth/tree-of-thought-llm.