 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalking Turns: Benchmarking Audio Foundation Models on Turn-Taking Dynamics
Mar 03, 2025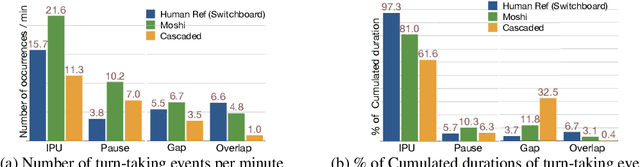

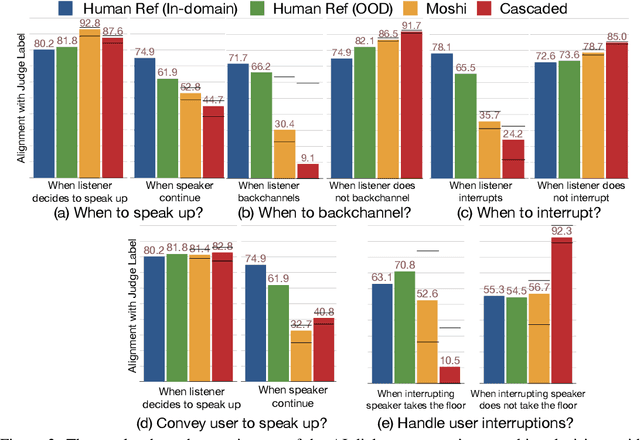

The recent wave of audio foundation models (FMs) could provide new capabilities for conversational modeling. However, there have been limited efforts to evaluate these audio FMs comprehensively on their ability to have natural and interactive conversations. To engage in meaningful conversation with the end user, we would want the FMs to additionally perform a fluent succession of turns without too much overlapping speech or long stretches of silence. Inspired by this, we ask whether the recently proposed audio FMs can understand, predict, and perform turn-taking events? To answer this, we propose a novel evaluation protocol that can assess spoken dialog system's turn-taking capabilities using a supervised model as a judge that has been trained to predict turn-taking events in human-human conversations. Using this protocol, we present the first comprehensive user study that evaluates existing spoken dialogue systems on their ability to perform turn-taking events and reveal many interesting insights, such as they sometimes do not understand when to speak up, can interrupt too aggressively and rarely backchannel. We further evaluate multiple open-source and proprietary audio FMs accessible through APIs on carefully curated test benchmarks from Switchboard to measure their ability to understand and predict turn-taking events and identify significant room for improvement. We will open source our evaluation platform to promote the development of advanced conversational AI systems.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Handling Ambiguity in Emotion: From Out-of-Domain Detection to Distribution Estimation
Feb 20, 2024



The subjective perception of emotion leads to inconsistent labels from human annotators. Typically, utterances lacking majority-agreed labels are excluded when training an emotion classifier, which cause problems when encountering ambiguous emotional expressions during testing. This paper investigates three methods to handle ambiguous emotion. First, we show that incorporating utterances without majority-agreed labels as an additional class in the classifier reduces the classification performance of the other emotion classes. Then, we propose detecting utterances with ambiguous emotions as out-of-domain samples by quantifying the uncertainty in emotion classification using evidential deep learning. This approach retains the classification accuracy while effectively detects ambiguous emotion expressions. Furthermore, to obtain fine-grained distinctions among ambiguous emotions, we propose representing emotion as a distribution instead of a single class label. The task is thus re-framed from classification to distribution estimation where every individual annotation is taken into account, not just the majority opinion. The evidential uncertainty measure is extended to quantify the uncertainty in emotion distribution estimation. Experimental results on the IEMOCAP and CREMA-D datasets demonstrate the superior capability of the proposed method in terms of majority class prediction, emotion distribution estimation, and uncertainty estimation.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
SLM: Bridge the thin gap between speech and text foundation models
Sep 30, 2023



We present a joint Speech and Language Model (SLM), a multitask, multilingual, and dual-modal model that takes advantage of pretrained foundational speech and language models. SLM freezes the pretrained foundation models to maximally preserves their capabilities, and only trains a simple adapter with just 1\% (156M) of the foundation models' parameters. This adaptation not only leads SLM to achieve strong performance on conventional tasks such as speech recognition (ASR) and speech translation (AST), but also introduces the novel capability of zero-shot instruction-following for more diverse tasks: given a speech input and a text instruction, SLM is able to perform unseen generation tasks including contextual biasing ASR using real-time context, dialog generation, speech continuation, and question answering, etc. Our approach demonstrates that the representational gap between pretrained speech and language models might be narrower than one would expect, and can be bridged by a simple adaptation mechanism. As a result, SLM is not only efficient to train, but also inherits strong capabilities already acquired in foundation models of different modalities.
Efficient Adapters for Giant Speech Models
Jun 13, 2023
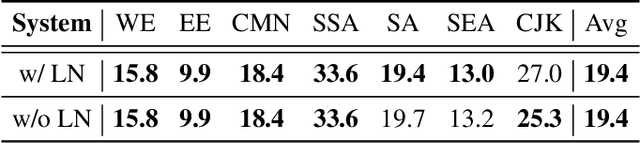


Large pre-trained speech models are widely used as the de-facto paradigm, especially in scenarios when there is a limited amount of labeled data available. However, finetuning all parameters from the self-supervised learned model can be computationally expensive, and becomes infeasiable as the size of the model and the number of downstream tasks scales. In this paper, we propose a novel approach called Two Parallel Adapter (TPA) that is inserted into the conformer-based model pre-trained model instead. TPA is based on systematic studies of the residual adapter, a popular approach for finetuning a subset of parameters. We evaluate TPA on various public benchmarks and experiment results demonstrates its superior performance, which is close to the full finetuning on different datasets and speech tasks. These results show that TPA is an effective and efficient approach for serving large pre-trained speech models. Ablation studies show that TPA can also be pruned, especially for lower blocks.
Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages
Mar 03, 2023
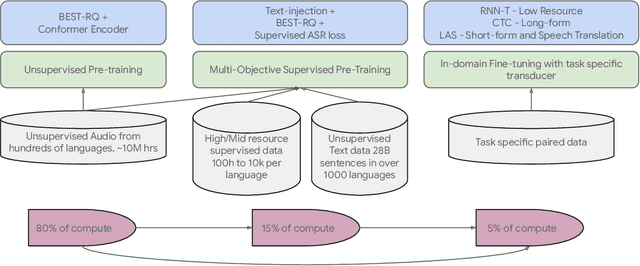
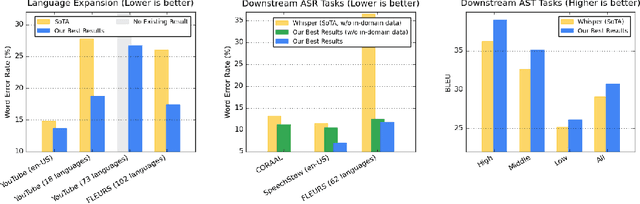

We introduce the Universal Speech Model (USM), a single large model that performs automatic speech recognition (ASR) across 100+ languages. This is achieved by pre-training the encoder of the model on a large unlabeled multilingual dataset of 12 million (M) hours spanning over 300 languages, and fine-tuning on a smaller labeled dataset. We use multilingual pre-training with random-projection quantization and speech-text modality matching to achieve state-of-the-art performance on downstream multilingual ASR and speech-to-text translation tasks. We also demonstrate that despite using a labeled training set 1/7-th the size of that used for the Whisper model, our model exhibits comparable or better performance on both in-domain and out-of-domain speech recognition tasks across many languages.
Textless Direct Speech-to-Speech Translation with Discrete Speech Representation
Oct 31, 2022



Research on speech-to-speech translation (S2ST) has progressed rapidly in recent years. Many end-to-end systems have been proposed and show advantages over conventional cascade systems, which are often composed of recognition, translation and synthesis sub-systems. However, most of the end-to-end systems still rely on intermediate textual supervision during training, which makes it infeasible to work for languages without written forms. In this work, we propose a novel model, Textless Translatotron, which is based on Translatotron 2, for training an end-to-end direct S2ST model without any textual supervision. Instead of jointly training with an auxiliary task predicting target phonemes as in Translatotron 2, the proposed model uses an auxiliary task predicting discrete speech representations which are obtained from learned or random speech quantizers. When a speech encoder pre-trained with unsupervised speech data is used for both models, the proposed model obtains translation quality nearly on-par with Translatotron 2 on the multilingual CVSS-C corpus as well as the bilingual Fisher Spanish-English corpus. On the latter, it outperforms the prior state-of-the-art textless model by +18.5 BLEU.
Accented Speech Recognition: Benchmarking, Pre-training, and Diverse Data
May 16, 2022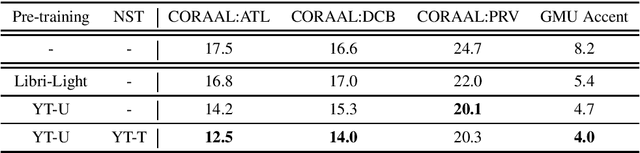

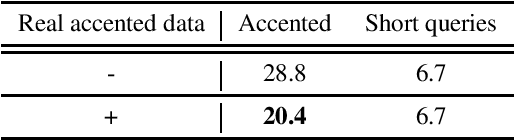
Building inclusive speech recognition systems is a crucial step towards developing technologies that speakers of all language varieties can use. Therefore, ASR systems must work for everybody independently of the way they speak. To accomplish this goal, there should be available data sets representing language varieties, and also an understanding of model configuration that is the most helpful in achieving robust understanding of all types of speech. However, there are not enough data sets for accented speech, and for the ones that are already available, more training approaches need to be explored to improve the quality of accented speech recognition. In this paper, we discuss recent progress towards developing more inclusive ASR systems, namely, the importance of building new data sets representing linguistic diversity, and exploring novel training approaches to improve performance for all users. We address recent directions within benchmarking ASR systems for accented speech, measure the effects of wav2vec 2.0 pre-training on accented speech recognition, and highlight corpora relevant for diverse ASR evaluations.