 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
Gemma: Open Models Based on Gemini Research and Technology
Mar 13, 2024



This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
BUFFET: Benchmarking Large Language Models for Few-shot Cross-lingual Transfer
May 24, 2023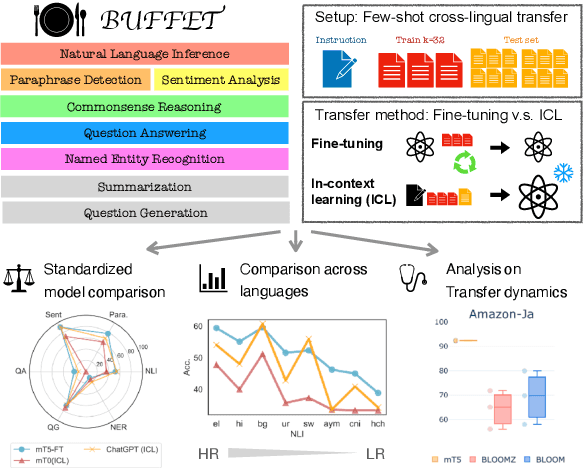
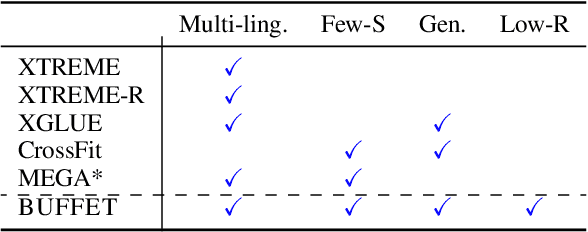
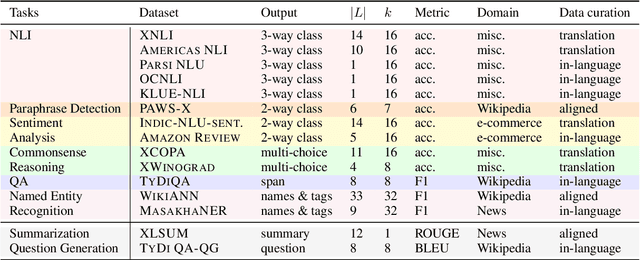
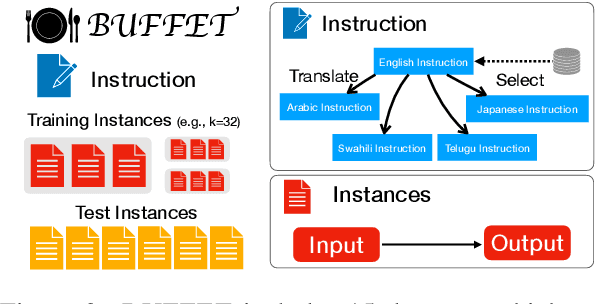
Despite remarkable advancements in few-shot generalization in natural language processing, most models are developed and evaluated primarily in English. To facilitate research on few-shot cross-lingual transfer, we introduce a new benchmark, called BUFFET, which unifies 15 diverse tasks across 54 languages in a sequence-to-sequence format and provides a fixed set of few-shot examples and instructions. BUFFET is designed to establish a rigorous and equitable evaluation framework for few-shot cross-lingual transfer across a broad range of tasks and languages. Using BUFFET, we perform thorough evaluations of state-of-the-art multilingual large language models with different transfer methods, namely in-context learning and fine-tuning. Our findings reveal significant room for improvement in few-shot in-context cross-lingual transfer. In particular, ChatGPT with in-context learning often performs worse than much smaller mT5-base models fine-tuned on English task data and few-shot in-language examples. Our analysis suggests various avenues for future research in few-shot cross-lingual transfer, such as improved pretraining, understanding, and future evaluations.
mmT5: Modular Multilingual Pre-Training Solves Source Language Hallucinations
May 23, 2023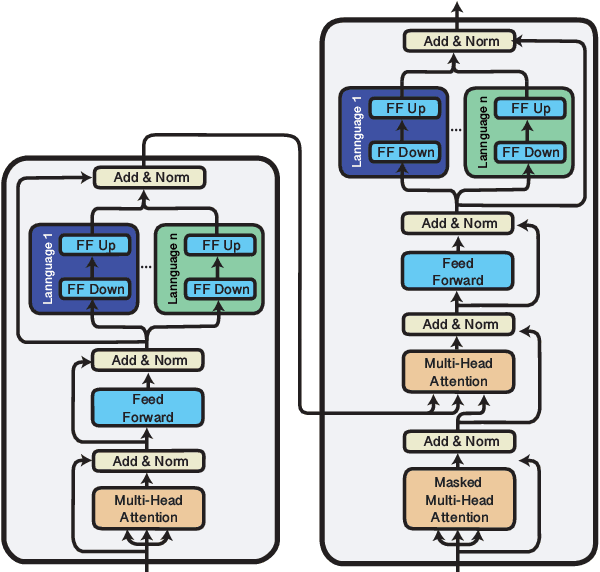



Multilingual sequence-to-sequence models perform poorly with increased language coverage and fail to consistently generate text in the correct target language in few-shot settings. To address these challenges, we propose mmT5, a modular multilingual sequence-to-sequence model. mmT5 utilizes language-specific modules during pre-training, which disentangle language-specific information from language-agnostic information. We identify representation drift during fine-tuning as a key limitation of modular generative models and develop strategies that enable effective zero-shot transfer. Our model outperforms mT5 at the same parameter sizes by a large margin on representative natural language understanding and generation tasks in 40+ languages. Compared to mT5, mmT5 raises the rate of generating text in the correct language under zero-shot settings from 7% to 99%, thereby greatly alleviating the source language hallucination problem.
On the Role of Parallel Data in Cross-lingual Transfer Learning
Dec 20, 2022


While prior work has established that the use of parallel data is conducive for cross-lingual learning, it is unclear if the improvements come from the data itself, or if it is the modeling of parallel interactions that matters. Exploring this, we examine the usage of unsupervised machine translation to generate synthetic parallel data, and compare it to supervised machine translation and gold parallel data. We find that even model generated parallel data can be useful for downstream tasks, in both a general setting (continued pretraining) as well as the task-specific setting (translate-train), although our best results are still obtained using real parallel data. Our findings suggest that existing multilingual models do not exploit the full potential of monolingual data, and prompt the community to reconsider the traditional categorization of cross-lingual learning approaches.
DiffusER: Discrete Diffusion via Edit-based Reconstruction
Oct 30, 2022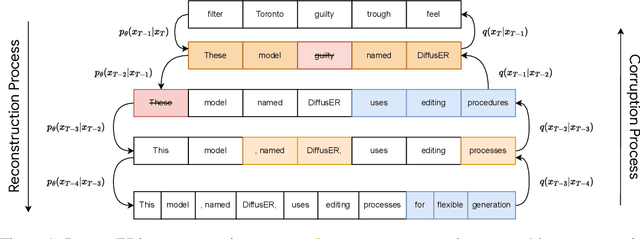

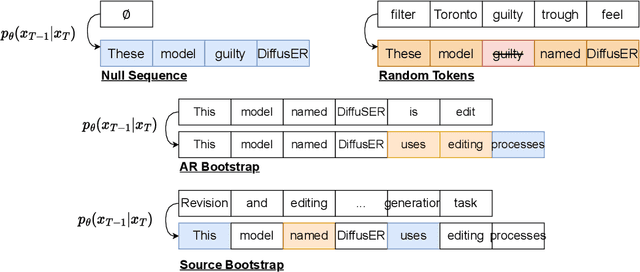
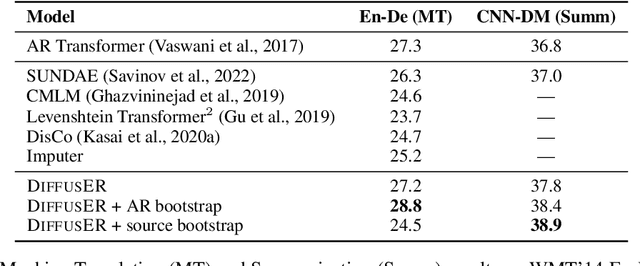
In text generation, models that generate text from scratch one token at a time are currently the dominant paradigm. Despite being performant, these models lack the ability to revise existing text, which limits their usability in many practical scenarios. We look to address this, with DiffusER (Diffusion via Edit-based Reconstruction), a new edit-based generative model for text based on denoising diffusion models -- a class of models that use a Markov chain of denoising steps to incrementally generate data. DiffusER is not only a strong generative model in general, rivalling autoregressive models on several tasks spanning machine translation, summarization, and style transfer; it can also perform other varieties of generation that standard autoregressive models are not well-suited for. For instance, we demonstrate that DiffusER makes it possible for a user to condition generation on a prototype, or an incomplete sequence, and continue revising based on previous edit steps.
M2D2: A Massively Multi-domain Language Modeling Dataset
Oct 13, 2022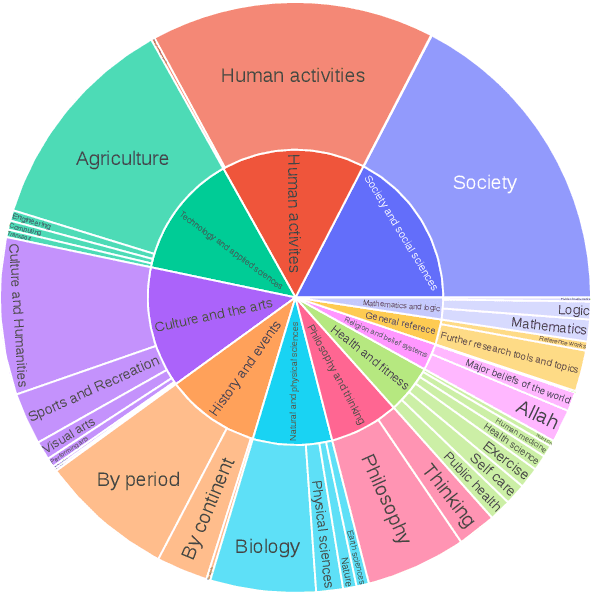
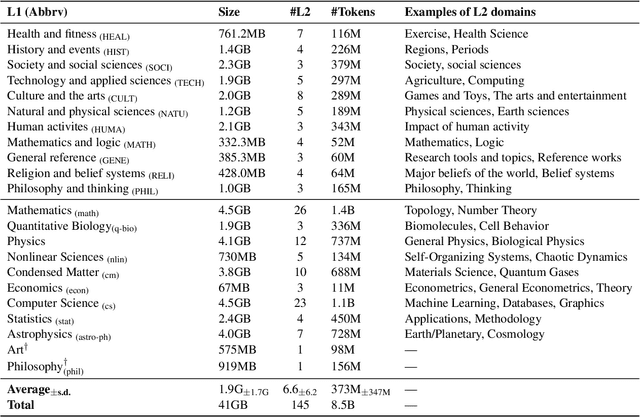
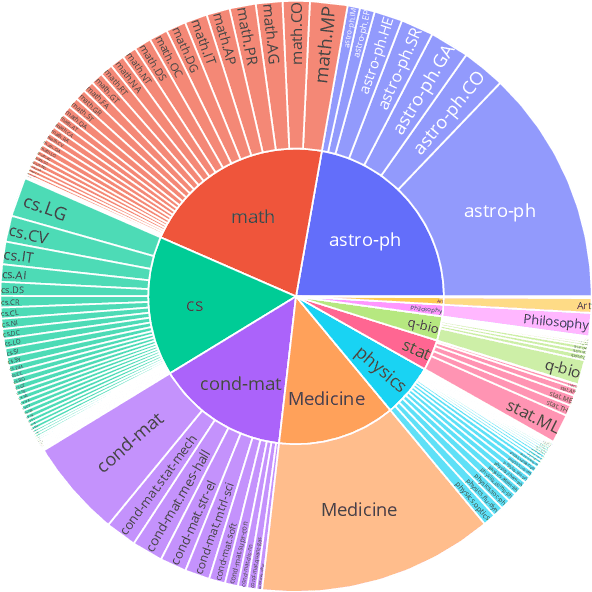
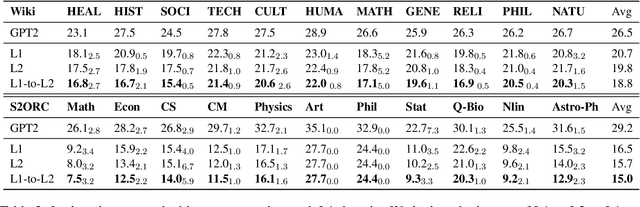
We present M2D2, a fine-grained, massively multi-domain corpus for studying domain adaptation in language models (LMs). M2D2 consists of 8.5B tokens and spans 145 domains extracted from Wikipedia and Semantic Scholar. Using ontologies derived from Wikipedia and ArXiv categories, we organize the domains in each data source into 22 groups. This two-level hierarchy enables the study of relationships between domains and their effects on in- and out-of-domain performance after adaptation. We also present a number of insights into the nature of effective domain adaptation in LMs, as examples of the new types of studies M2D2 enables. To improve in-domain performance, we show the benefits of adapting the LM along a domain hierarchy; adapting to smaller amounts of fine-grained domain-specific data can lead to larger in-domain performance gains than larger amounts of weakly relevant data. We further demonstrate a trade-off between in-domain specialization and out-of-domain generalization within and across ontologies, as well as a strong correlation between out-of-domain performance and lexical overlap between domains.
Learning to Model Editing Processes
May 24, 2022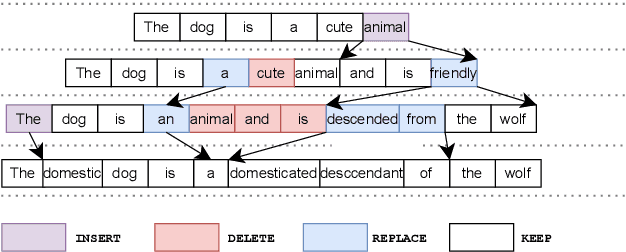


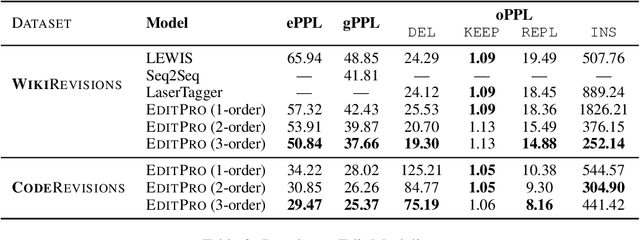
Most existing sequence generation models produce outputs in one pass, usually left-to-right. However, this is in contrast with a more natural approach that humans use in generating content; iterative refinement and editing. Recent work has introduced edit-based models for various tasks (such as neural machine translation and text style transfer), but these generally model a single edit step. In this work, we propose modeling editing processes, modeling the whole process of iteratively generating sequences. We form a conceptual framework to describe the likelihood of multi-step edits, and describe neural models that can learn a generative model of sequences based on these multistep edits. We introduce baseline results and metrics on this task, finding that modeling editing processes improves performance on a variety of axes on both our proposed task and related downstream tasks compared to previous single-step models of edits.