 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXTREME-UP: A User-Centric Scarce-Data Benchmark for Under-Represented Languages
May 24, 2023



Data scarcity is a crucial issue for the development of highly multilingual NLP systems. Yet for many under-represented languages (ULs) -- languages for which NLP re-search is particularly far behind in meeting user needs -- it is feasible to annotate small amounts of data. Motivated by this, we propose XTREME-UP, a benchmark defined by: its focus on the scarce-data scenario rather than zero-shot; its focus on user-centric tasks -- tasks with broad adoption by speakers of high-resource languages; and its focus on under-represented languages where this scarce-data scenario tends to be most realistic. XTREME-UP evaluates the capabilities of language models across 88 under-represented languages over 9 key user-centric technologies including ASR, OCR, MT, and information access tasks that are of general utility. We create new datasets for OCR, autocomplete, semantic parsing, and transliteration, and build on and refine existing datasets for other tasks. XTREME-UP provides methodology for evaluating many modeling scenarios including text-only, multi-modal (vision, audio, and text),supervised parameter tuning, and in-context learning. We evaluate commonly used models on the benchmark. We release all code and scripts to train and evaluate models
mmT5: Modular Multilingual Pre-Training Solves Source Language Hallucinations
May 23, 2023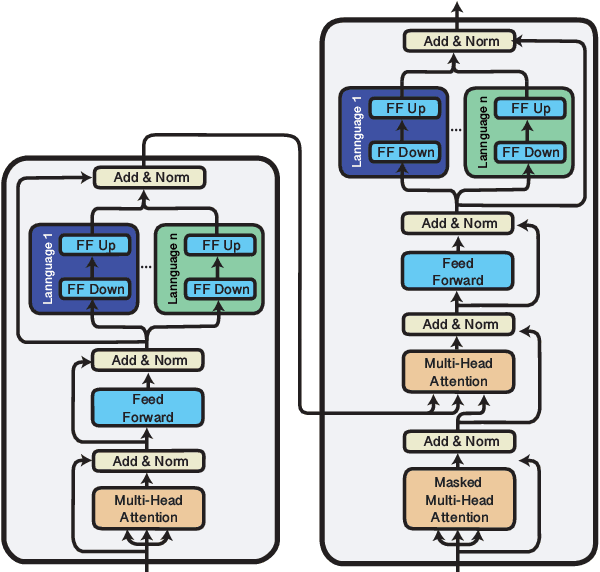



Multilingual sequence-to-sequence models perform poorly with increased language coverage and fail to consistently generate text in the correct target language in few-shot settings. To address these challenges, we propose mmT5, a modular multilingual sequence-to-sequence model. mmT5 utilizes language-specific modules during pre-training, which disentangle language-specific information from language-agnostic information. We identify representation drift during fine-tuning as a key limitation of modular generative models and develop strategies that enable effective zero-shot transfer. Our model outperforms mT5 at the same parameter sizes by a large margin on representative natural language understanding and generation tasks in 40+ languages. Compared to mT5, mmT5 raises the rate of generating text in the correct language under zero-shot settings from 7% to 99%, thereby greatly alleviating the source language hallucination problem.
Evaluating Byte and Wordpiece Level Models for Massively Multilingual Semantic Parsing
Dec 14, 2022



Token free approaches have been successfully applied to a series of word and span level tasks. In this work, we compare a byte-level (ByT5) and a wordpiece based (mT5) sequence to sequence model on the 51 languages of the MASSIVE multilingual semantic parsing dataset. We examine multiple experimental settings: (i) zero-shot, (ii) full gold data and (iii) zero-shot with synthetic data. By leveraging a state-of-the-art label projection method for machine translated examples, we are able to reduce the gap in exact match accuracy to only 5 points with respect to a model trained on gold data from all the languages. We additionally provide insights on the cross-lingual transfer of ByT5 and show how the model compares with respect to mT5 across all parameter sizes.
Translate & Fill: Improving Zero-Shot Multilingual Semantic Parsing with Synthetic Data
Sep 09, 2021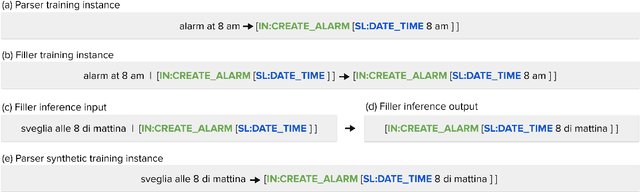

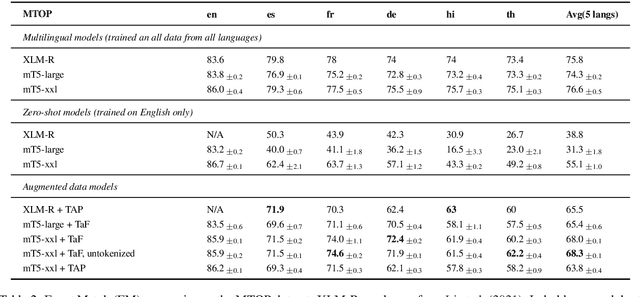
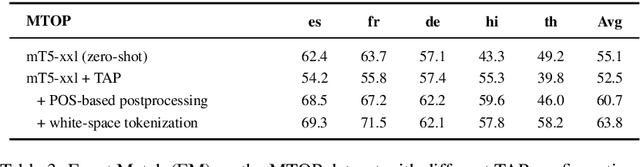
While multilingual pretrained language models (LMs) fine-tuned on a single language have shown substantial cross-lingual task transfer capabilities, there is still a wide performance gap in semantic parsing tasks when target language supervision is available. In this paper, we propose a novel Translate-and-Fill (TaF) method to produce silver training data for a multilingual semantic parser. This method simplifies the popular Translate-Align-Project (TAP) pipeline and consists of a sequence-to-sequence filler model that constructs a full parse conditioned on an utterance and a view of the same parse. Our filler is trained on English data only but can accurately complete instances in other languages (i.e., translations of the English training utterances), in a zero-shot fashion. Experimental results on three multilingual semantic parsing datasets show that data augmentation with TaF reaches accuracies competitive with similar systems which rely on traditional alignment techniques.
Answering Conversational Questions on Structured Data without Logical Forms
Aug 30, 2019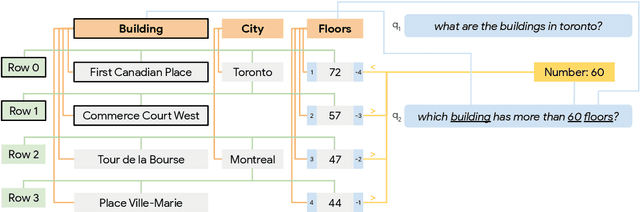
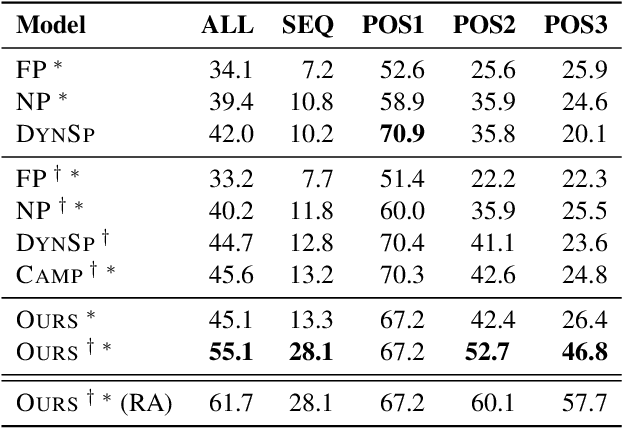
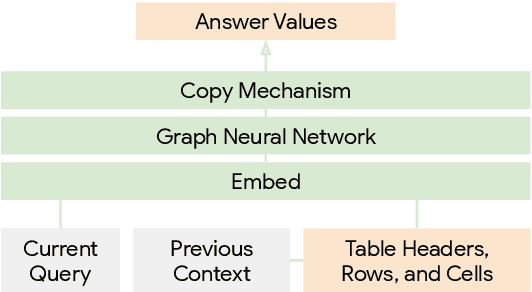

We present a novel approach to answering sequential questions based on structured objects such as knowledge bases or tables without using a logical form as an intermediate representation. We encode tables as graphs using a graph neural network model based on the Transformer architecture. The answers are then selected from the encoded graph using a pointer network. This model is appropriate for processing conversations around structured data, where the attention mechanism that selects the answers to a question can also be used to resolve conversational references. We demonstrate the validity of this approach with competitive results on the Sequential Question Answering (SQA) task (Iyyer et al., 2017).