 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Informally Romanized Language Identification
Apr 30, 2025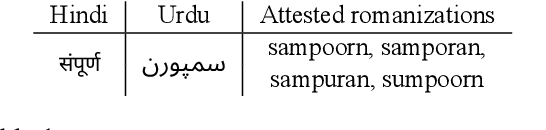
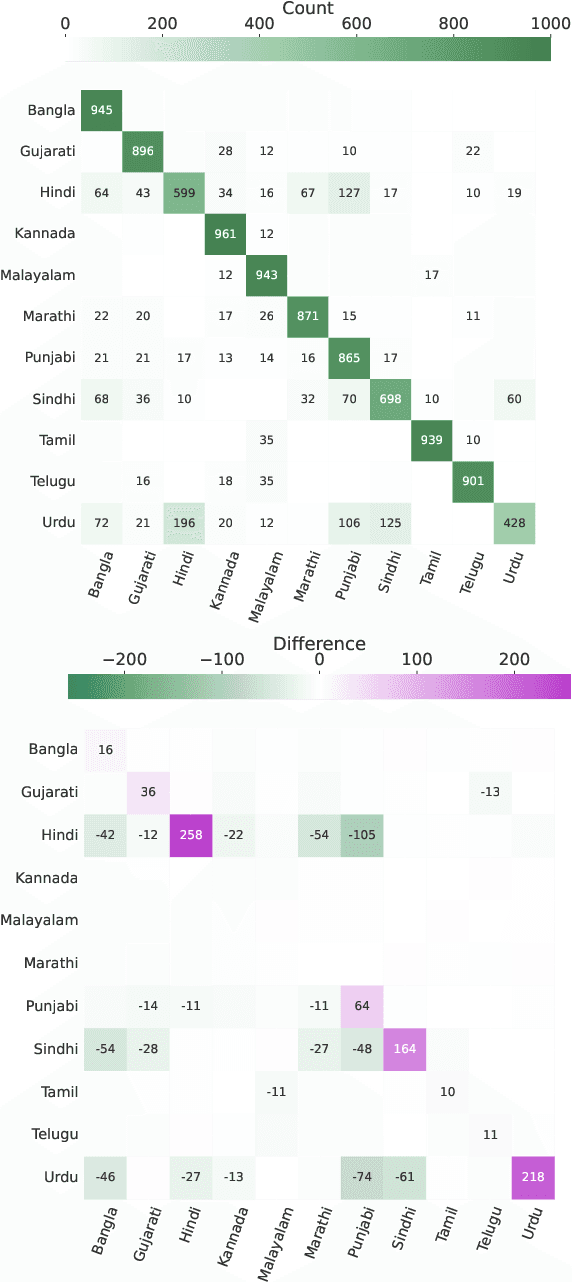

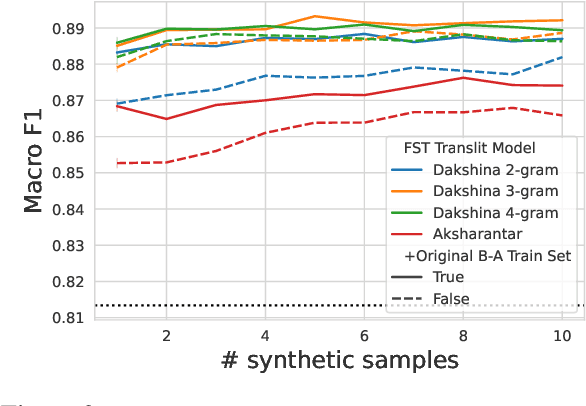
The Latin script is often used to informally write languages with non-Latin native scripts. In many cases (e.g., most languages in India), there is no conventional spelling of words in the Latin script, hence there will be high spelling variability in written text. Such romanization renders languages that are normally easily distinguished based on script highly confusable, such as Hindi and Urdu. In this work, we increase language identification (LID) accuracy for romanized text by improving the methods used to synthesize training sets. We find that training on synthetic samples which incorporate natural spelling variation yields higher LID system accuracy than including available naturally occurring examples in the training set, or even training higher capacity models. We demonstrate new state-of-the-art LID performance on romanized text from 20 Indic languages in the Bhasha-Abhijnaanam evaluation set (Madhani et al., 2023a), improving test F1 from the reported 74.7% (using a pretrained neural model) to 85.4% using a linear classifier trained solely on synthetic data and 88.2% when also training on available harvested text.
XTREME-UP: A User-Centric Scarce-Data Benchmark for Under-Represented Languages
May 24, 2023



Data scarcity is a crucial issue for the development of highly multilingual NLP systems. Yet for many under-represented languages (ULs) -- languages for which NLP re-search is particularly far behind in meeting user needs -- it is feasible to annotate small amounts of data. Motivated by this, we propose XTREME-UP, a benchmark defined by: its focus on the scarce-data scenario rather than zero-shot; its focus on user-centric tasks -- tasks with broad adoption by speakers of high-resource languages; and its focus on under-represented languages where this scarce-data scenario tends to be most realistic. XTREME-UP evaluates the capabilities of language models across 88 under-represented languages over 9 key user-centric technologies including ASR, OCR, MT, and information access tasks that are of general utility. We create new datasets for OCR, autocomplete, semantic parsing, and transliteration, and build on and refine existing datasets for other tasks. XTREME-UP provides methodology for evaluating many modeling scenarios including text-only, multi-modal (vision, audio, and text),supervised parameter tuning, and in-context learning. We evaluate commonly used models on the benchmark. We release all code and scripts to train and evaluate models
Beyond Arabic: Software for Perso-Arabic Script Manipulation
Jan 26, 2023



This paper presents an open-source software library that provides a set of finite-state transducer (FST) components and corresponding utilities for manipulating the writing systems of languages that use the Perso-Arabic script. The operations include various levels of script normalization, including visual invariance-preserving operations that subsume and go beyond the standard Unicode normalization forms, as well as transformations that modify the visual appearance of characters in accordance with the regional orthographies for eleven contemporary languages from diverse language families. The library also provides simple FST-based romanization and transliteration. We additionally attempt to formalize the typology of Perso-Arabic characters by providing one-to-many mappings from Unicode code points to the languages that use them. While our work focuses on the Arabic script diaspora rather than Arabic itself, this approach could be adopted for any language that uses the Arabic script, thus providing a unified framework for treating a script family used by close to a billion people.
Helpful Neighbors: Leveraging Neighbors in Geographic Feature Pronunciation
Oct 18, 2022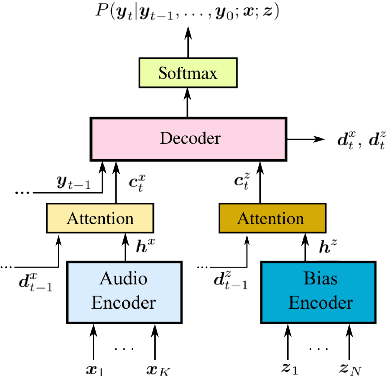

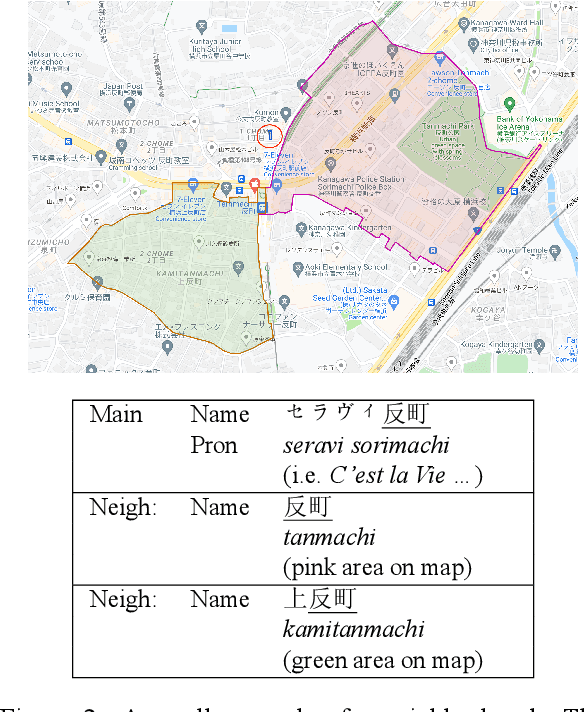
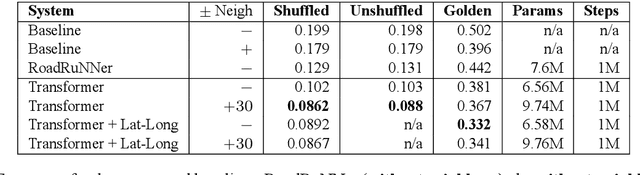
If one sees the place name Houston Mercer Dog Run in New York, how does one know how to pronounce it? Assuming one knows that Houston in New York is pronounced "how-ston" and not like the Texas city, then one can probably guess that "how-ston" is also used in the name of the dog park. We present a novel architecture that learns to use the pronunciations of neighboring names in order to guess the pronunciation of a given target feature. Applied to Japanese place names, we demonstrate the utility of the model to finding and proposing corrections for errors in Google Maps. To demonstrate the utility of this approach to structurally similar problems, we also report on an application to a totally different task: Cognate reflex prediction in comparative historical linguistics. A version of the code has been open-sourced (https://github.com/google-research/google-research/tree/master/cognate_inpaint_neighbors).
Building Machine Translation Systems for the Next Thousand Languages
May 16, 2022
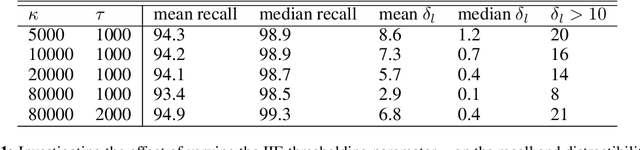

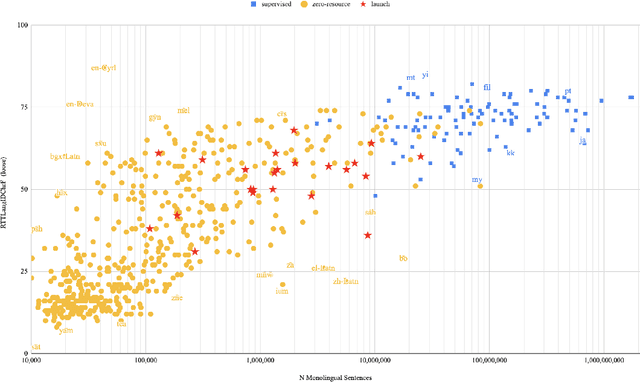
In this paper we share findings from our effort to build practical machine translation (MT) systems capable of translating across over one thousand languages. We describe results in three research domains: (i) Building clean, web-mined datasets for 1500+ languages by leveraging semi-supervised pre-training for language identification and developing data-driven filtering techniques; (ii) Developing practical MT models for under-served languages by leveraging massively multilingual models trained with supervised parallel data for over 100 high-resource languages and monolingual datasets for an additional 1000+ languages; and (iii) Studying the limitations of evaluation metrics for these languages and conducting qualitative analysis of the outputs from our MT models, highlighting several frequent error modes of these types of models. We hope that our work provides useful insights to practitioners working towards building MT systems for currently understudied languages, and highlights research directions that can complement the weaknesses of massively multilingual models in data-sparse settings.
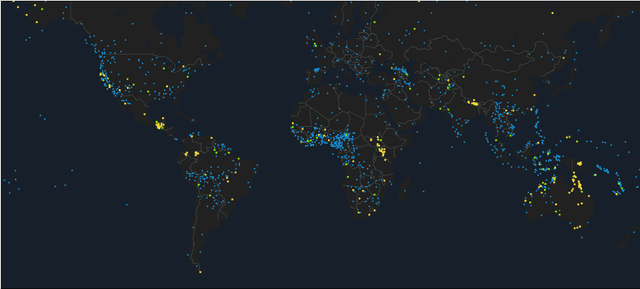
Google Crowdsourced Speech Corpora and Related Open-Source Resources for Low-Resource Languages and Dialects: An Overview
Oct 14, 2020This paper presents an overview of a program designed to address the growing need for developing freely available speech resources for under-represented languages. At present we have released 38 datasets for building text-to-speech and automatic speech recognition applications for languages and dialects of South and Southeast Asia, Africa, Europe and South America. The paper describes the methodology used for developing such corpora and presents some of our findings that could benefit under-represented language communities.
NEMO: Frequentist Inference Approach to Constrained Linguistic Typology Feature Prediction in SIGTYP 2020 Shared Task
Oct 12, 2020
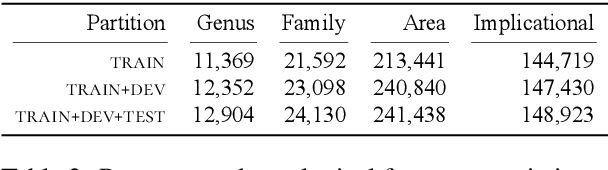
This paper describes the NEMO submission to SIGTYP 2020 shared task which deals with prediction of linguistic typological features for multiple languages using the data derived from World Atlas of Language Structures (WALS). We employ frequentist inference to represent correlations between typological features and use this representation to train simple multi-class estimators that predict individual features. We describe two submitted ridge regression-based configurations which ranked second and third overall in the constrained task. Our best configuration achieved the micro-averaged accuracy score of 0.66 on 149 test languages.
Towards Induction of Structured Phoneme Inventories
Oct 12, 2020This extended abstract surveying the work on phonological typology was prepared for "SIGTYP 2020: The Second Workshop on Computational Research in Linguistic Typology" to be held at EMNLP 2020.
Linguistic Typology Features from Text: Inferring the Sparse Features of World Atlas of Language Structures
May 04, 2020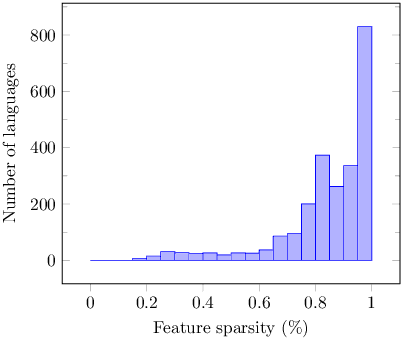
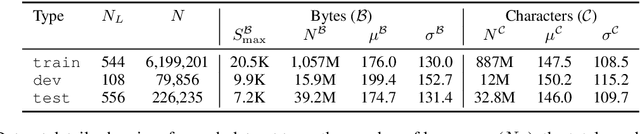
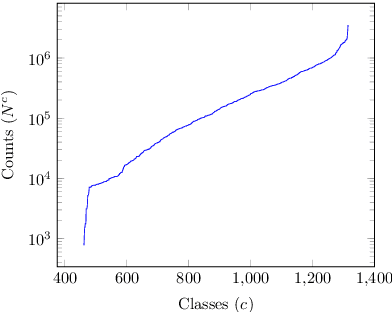
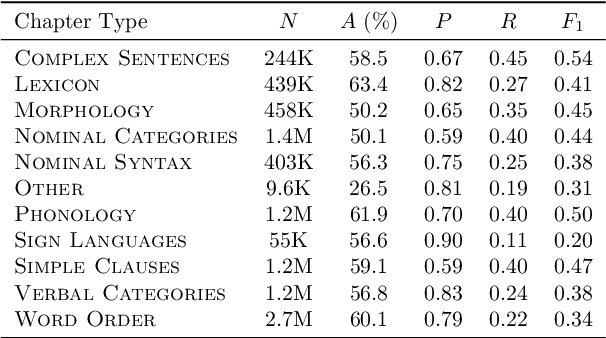
The use of linguistic typological resources in natural language processing has been steadily gaining more popularity. It has been observed that the use of typological information, often combined with distributed language representations, leads to significantly more powerful models. While linguistic typology representations from various resources have mostly been used for conditioning the models, there has been relatively little attention on predicting features from these resources from the input data. In this paper we investigate whether the various linguistic features from World Atlas of Language Structures (WALS) can be reliably inferred from multi-lingual text. Such a predictor can be used to infer structural features for a language never observed in training data. We frame this task as a multi-label classification involving predicting the set of non-mutually exclusive and extremely sparse multi-valued labels (WALS features). We construct a recurrent neural network predictor based on byte embeddings and convolutional layers and test its performance on 556 languages, providing analysis for various linguistic types, macro-areas, language families and individual features. We show that some features from various linguistic types can be predicted reliably.
Sampling from Stochastic Finite Automata with Applications to CTC Decoding
May 21, 2019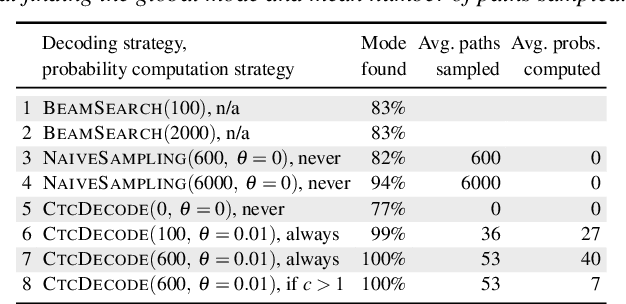
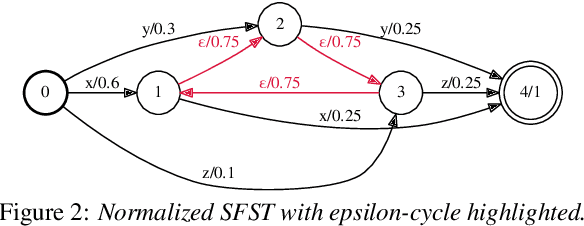
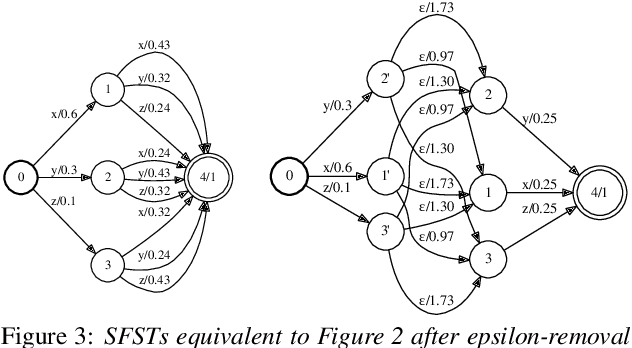
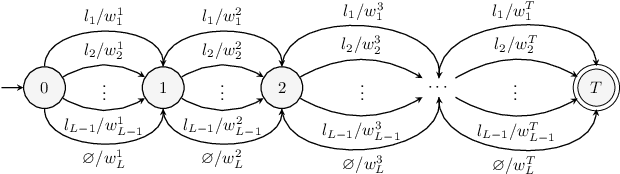
Stochastic finite automata arise naturally in many language and speech processing tasks. They include stochastic acceptors, which represent certain probability distributions over random strings. We consider the problem of efficient sampling: drawing random string variates from the probability distribution represented by stochastic automata and transformations of those. We show that path-sampling is effective and can be efficient if the epsilon-graph of a finite automaton is acyclic. We provide an algorithm that ensures this by conflating epsilon-cycles within strongly connected components. Sampling is also effective in the presence of non-injective transformations of strings. We illustrate this in the context of decoding for Connectionist Temporal Classification (CTC), where the predictive probabilities yield auxiliary sequences which are transformed into shorter labeling strings. We can sample efficiently from the transformed labeling distribution and use this in two different strategies for finding the most probable CTC labeling.