 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multi-Agent Coordination via Sheaf-ADMM
May 29, 2026We present a differentiable optimization framework for multi-agent coordination. An input is decomposed into overlapping local views, each processed by an agent that solves a convex subproblem parameterized by a neural encoder. Agents coordinate through the Alternating Direction Method of Multipliers (ADMM) with inter-agent constraints specified by a cellular sheaf. The sheaf specifies which aspects of neighboring solutions must agree, allowing for heterogeneous notions of global consensus. Backpropagating through the unrolled optimization jointly trains all components of the multi-agent system. We evaluate on maze pathfinding, image classification, and Sudoku, where agents with individually insufficient local views learn to coordinate to produce correct global outputs. On MNIST, the local-view decomposition yields improved robustness to distribution shifts relative to a standard CNN. On Sudoku, the optimization-derived structure yields markedly higher solve rates than parameter-matched MPNN baselines. Finally, the ADMM structure exposes distinct primal, consensus, and dual state variables, opening the coordination dynamics to direct analysis and intervention -- a property unavailable in standard message-passing architectures.
Sparser, Faster, Lighter Transformer Language Models
Mar 24, 2026Scaling autoregressive large language models (LLMs) has driven unprecedented progress but comes with vast computational costs. In this work, we tackle these costs by leveraging unstructured sparsity within an LLM's feedforward layers, the components accounting for most of the model parameters and execution FLOPs. To achieve this, we introduce a new sparse packing format and a set of CUDA kernels designed to seamlessly integrate with the optimized execution pipelines of modern GPUs, enabling efficient sparse computation during LLM inference and training. To substantiate our gains, we provide a quantitative study of LLM sparsity, demonstrating that simple L1 regularization can induce over 99% sparsity with negligible impact on downstream performance. When paired with our kernels, we show that these sparsity levels translate into substantial throughput, energy efficiency, and memory usage benefits that increase with model scale. We will release all code and kernels under an open-source license to promote adoption and accelerate research toward establishing sparsity as a practical axis for improving the efficiency and scalability of modern foundation models.
Fast-weight Product Key Memory
Jan 02, 2026Sequence modeling layers in modern language models typically face a trade-off between storage capacity and computational efficiency. While Softmax attention offers unbounded storage at prohibitive quadratic costs, linear variants provide efficiency but suffer from limited, fixed-size storage. We propose Fast-weight Product Key Memory (FwPKM), a novel architecture that resolves this tension by transforming the sparse Product Key Memory (PKM) from a static module into a dynamic, "fast-weight" episodic memory. Unlike PKM, FwPKM updates its parameters dynamically at both training and inference time via local chunk-level gradient descent, allowing the model to rapidly memorize and retrieve new key-value pairs from input sequences. Experiments reveal that FwPKM functions as an effective episodic memory that complements the semantic memory of standard modules, yielding significant perplexity reductions on long-context datasets. Notably, in Needle in a Haystack evaluations, FwPKM generalizes to 128K-token contexts despite being trained on only 4K-token sequences.
Sudoku-Bench: Evaluating creative reasoning with Sudoku variants
May 22, 2025



Existing reasoning benchmarks for large language models (LLMs) frequently fail to capture authentic creativity, often rewarding memorization of previously observed patterns. We address this shortcoming with Sudoku-Bench, a curated benchmark of challenging and unconventional Sudoku variants specifically selected to evaluate creative, multi-step logical reasoning. Sudoku variants form an unusually effective domain for reasoning research: each puzzle introduces unique or subtly interacting constraints, making memorization infeasible and requiring solvers to identify novel logical breakthroughs (``break-ins''). Despite their diversity, Sudoku variants maintain a common and compact structure, enabling clear and consistent evaluation. Sudoku-Bench includes a carefully chosen puzzle set, a standardized text-based puzzle representation, and flexible tools compatible with thousands of publicly available puzzles -- making it easy to extend into a general research environment. Baseline experiments show that state-of-the-art LLMs solve fewer than 15\% of puzzles unaided, highlighting significant opportunities to advance long-horizon, strategic reasoning capabilities.
Continuous Thought Machines
May 08, 2025



Biological brains demonstrate complex neural activity, where the timing and interplay between neurons is critical to how brains process information. Most deep learning architectures simplify neural activity by abstracting away temporal dynamics. In this paper we challenge that paradigm. By incorporating neuron-level processing and synchronization, we can effectively reintroduce neural timing as a foundational element. We present the Continuous Thought Machine (CTM), a model designed to leverage neural dynamics as its core representation. The CTM has two core innovations: (1) neuron-level temporal processing, where each neuron uses unique weight parameters to process a history of incoming signals; and (2) neural synchronization employed as a latent representation. The CTM aims to strike a balance between oversimplified neuron abstractions that improve computational efficiency, and biological realism. It operates at a level of abstraction that effectively captures essential temporal dynamics while remaining computationally tractable for deep learning. We demonstrate the CTM's strong performance and versatility across a range of challenging tasks, including ImageNet-1K classification, solving 2D mazes, sorting, parity computation, question-answering, and RL tasks. Beyond displaying rich internal representations and offering a natural avenue for interpretation owing to its internal process, the CTM is able to perform tasks that require complex sequential reasoning. The CTM can also leverage adaptive compute, where it can stop earlier for simpler tasks, or keep computing when faced with more challenging instances. The goal of this work is to share the CTM and its associated innovations, rather than pushing for new state-of-the-art results. To that end, we believe the CTM represents a significant step toward developing more biologically plausible and powerful artificial intelligence systems.
The Ungrounded Alignment Problem
Aug 08, 2024



Modern machine learning systems have demonstrated substantial abilities with methods that either embrace or ignore human-provided knowledge, but combining benefits of both styles remains a challenge. One particular challenge involves designing learning systems that exhibit built-in responses to specific abstract stimulus patterns, yet are still plastic enough to be agnostic about the modality and exact form of their inputs. In this paper, we investigate what we call The Ungrounded Alignment Problem, which asks How can we build in predefined knowledge in a system where we don't know how a given stimulus will be grounded? This paper examines a simplified version of the general problem, where an unsupervised learner is presented with a sequence of images for the characters in a text corpus, and this learner is later evaluated on its ability to recognize specific (possibly rare) sequential patterns. Importantly, the learner is given no labels during learning or evaluation, but must map images from an unknown font or permutation to its correct class label. That is, at no point is our learner given labeled images, where an image vector is explicitly associated with a class label. Despite ample work in unsupervised and self-supervised loss functions, all current methods require a labeled fine-tuning phase to map the learned representations to correct classes. Finding this mapping in the absence of labels may seem a fool's errand, but our main result resolves this seeming paradox. We show that leveraging only letter bigram frequencies is sufficient for an unsupervised learner both to reliably associate images to class labels and to reliably identify trigger words in the sequence of inputs. More generally, this method suggests an approach for encoding specific desired innate behaviour in modality-agnostic models.
Transformer Layers as Painters
Jul 12, 2024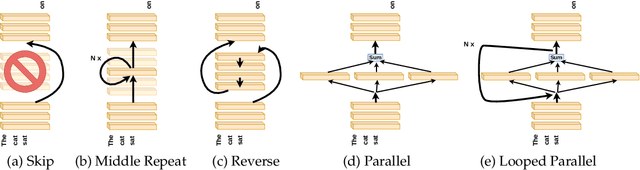
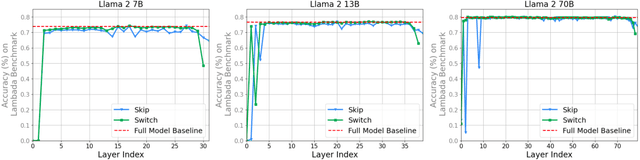
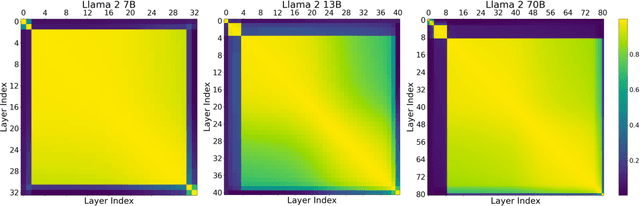
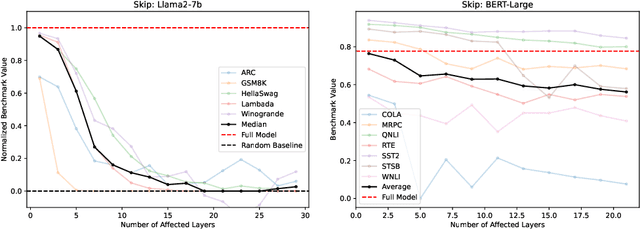
Despite their nearly universal adoption for large language models, the internal workings of transformers are not well understood. We aim to better understand the impact of removing or reorganizing information throughout the layers of a pretrained transformer. Such an understanding could both yield better usage of existing models as well as to make architectural improvements to produce new variants. We present a series of empirical studies on frozen models that show that the lower and final layers of pretrained transformers differ from middle layers, but that middle layers have a surprising amount of uniformity. We further show that some classes of problems have robustness to skipping layers, running the layers in an order different from how they were trained, or running the layers in parallel. Our observations suggest that even frozen pretrained models may gracefully trade accuracy for latency by skipping layers or running layers in parallel.
Helpful Neighbors: Leveraging Neighbors in Geographic Feature Pronunciation
Oct 18, 2022

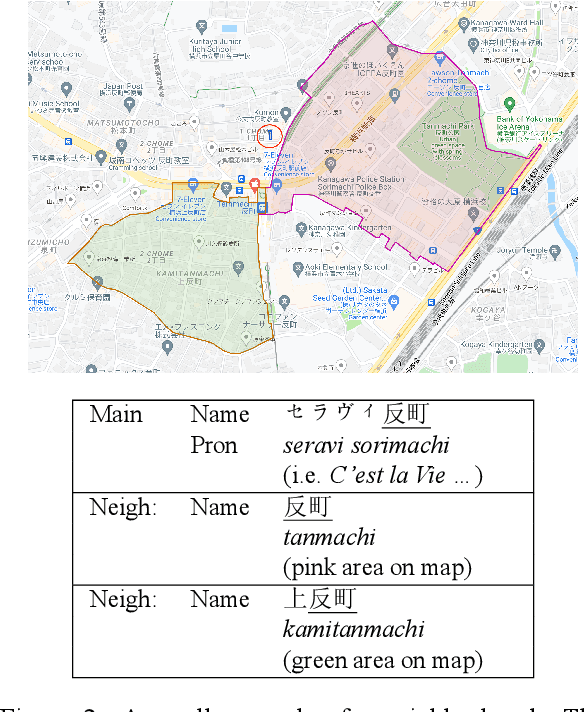
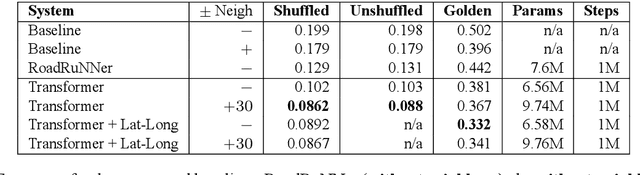
If one sees the place name Houston Mercer Dog Run in New York, how does one know how to pronounce it? Assuming one knows that Houston in New York is pronounced "how-ston" and not like the Texas city, then one can probably guess that "how-ston" is also used in the name of the dog park. We present a novel architecture that learns to use the pronunciations of neighboring names in order to guess the pronunciation of a given target feature. Applied to Japanese place names, we demonstrate the utility of the model to finding and proposing corrections for errors in Google Maps. To demonstrate the utility of this approach to structurally similar problems, we also report on an application to a totally different task: Cognate reflex prediction in comparative historical linguistics. A version of the code has been open-sourced (https://github.com/google-research/google-research/tree/master/cognate_inpaint_neighbors).
DF-Conformer: Integrated architecture of Conv-TasNet and Conformer using linear complexity self-attention for speech enhancement
Jun 30, 2021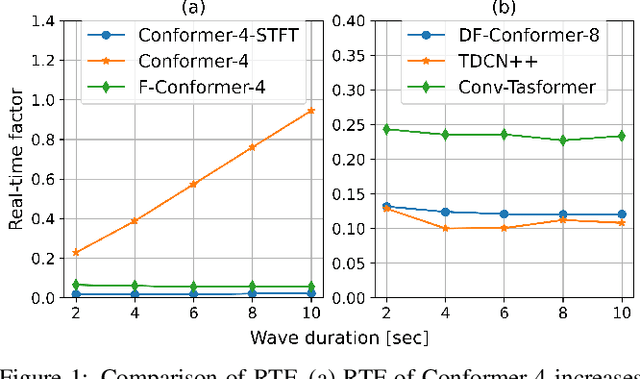
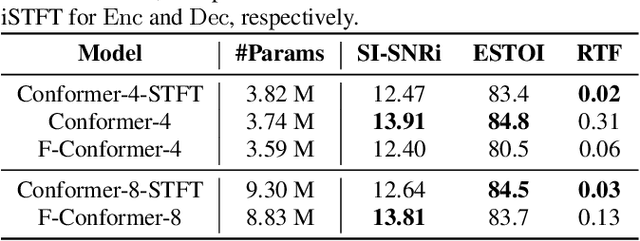
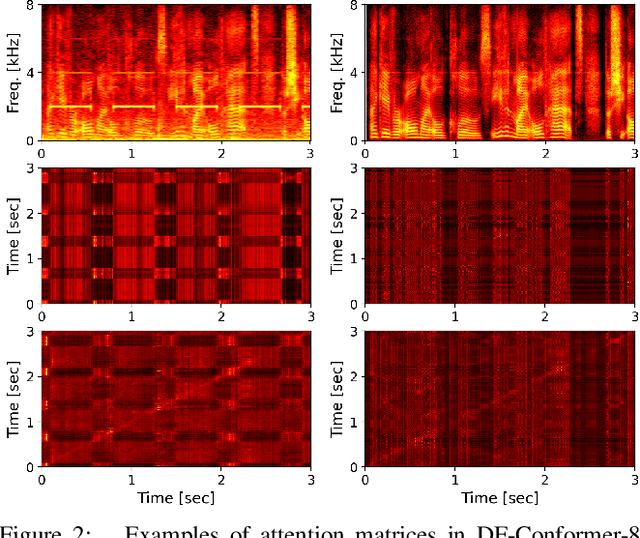
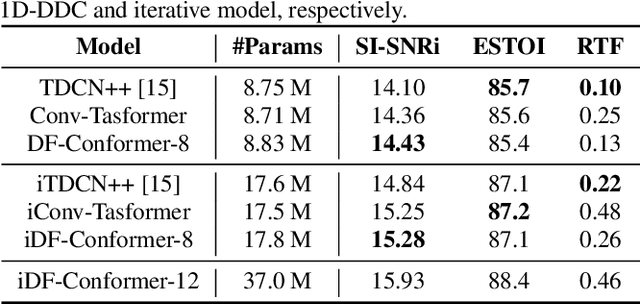
Single-channel speech enhancement (SE) is an important task in speech processing. A widely used framework combines an analysis/synthesis filterbank with a mask prediction network, such as the Conv-TasNet architecture. In such systems, the denoising performance and computational efficiency are mainly affected by the structure of the mask prediction network. In this study, we aim to improve the sequential modeling ability of Conv-TasNet architectures by integrating Conformer layers into a new mask prediction network. To make the model computationally feasible, we extend the Conformer using linear complexity attention and stacked 1-D dilated depthwise convolution layers. We trained the model on 3,396 hours of noisy speech data, and show that (i) the use of linear complexity attention avoids high computational complexity, and (ii) our model achieves higher scale-invariant signal-to-noise ratio than the improved time-dilated convolution network (TDCN++), an extended version of Conv-TasNet.
A Comparative Study on Neural Architectures and Training Methods for Japanese Speech Recognition
Jun 09, 2021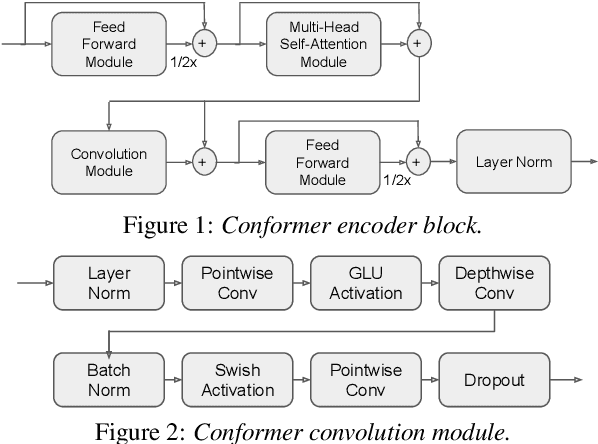
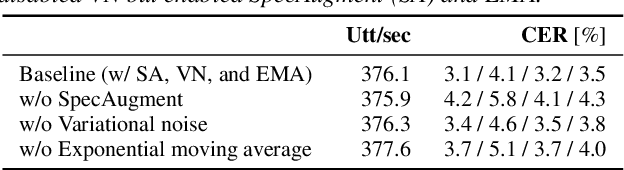
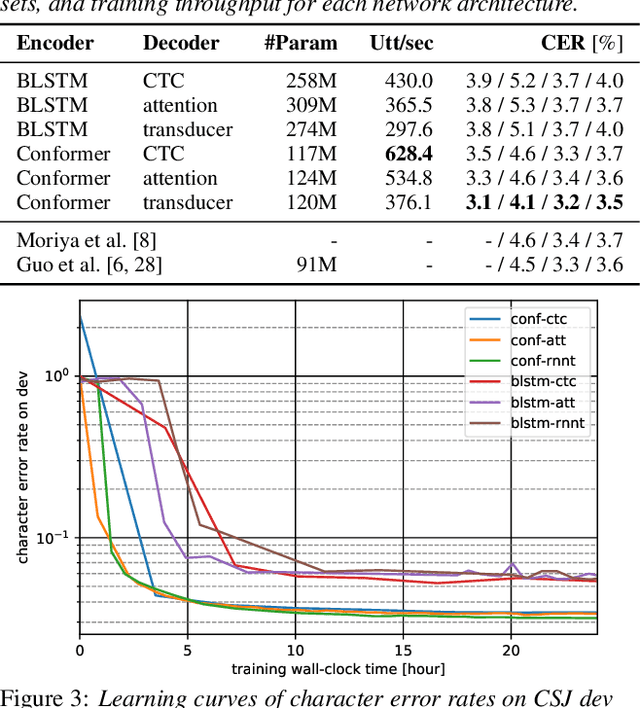
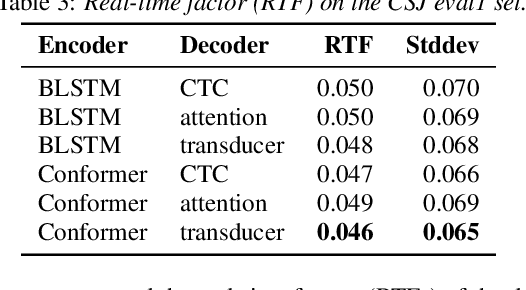
End-to-end (E2E) modeling is advantageous for automatic speech recognition (ASR) especially for Japanese since word-based tokenization of Japanese is not trivial, and E2E modeling is able to model character sequences directly. This paper focuses on the latest E2E modeling techniques, and investigates their performances on character-based Japanese ASR by conducting comparative experiments. The results are analyzed and discussed in order to understand the relative advantages of long short-term memory (LSTM), and Conformer models in combination with connectionist temporal classification, transducer, and attention-based loss functions. Furthermore, the paper investigates on effectivity of the recent training techniques such as data augmentation (SpecAugment), variational noise injection, and exponential moving average. The best configuration found in the paper achieved the state-of-the-art character error rates of 4.1%, 3.2%, and 3.5% for Corpus of Spontaneous Japanese (CSJ) eval1, eval2, and eval3 tasks, respectively. The system is also shown to be computationally efficient thanks to the efficiency of Conformer transducers.