 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Ungrounded Alignment Problem
Aug 08, 2024



Modern machine learning systems have demonstrated substantial abilities with methods that either embrace or ignore human-provided knowledge, but combining benefits of both styles remains a challenge. One particular challenge involves designing learning systems that exhibit built-in responses to specific abstract stimulus patterns, yet are still plastic enough to be agnostic about the modality and exact form of their inputs. In this paper, we investigate what we call The Ungrounded Alignment Problem, which asks How can we build in predefined knowledge in a system where we don't know how a given stimulus will be grounded? This paper examines a simplified version of the general problem, where an unsupervised learner is presented with a sequence of images for the characters in a text corpus, and this learner is later evaluated on its ability to recognize specific (possibly rare) sequential patterns. Importantly, the learner is given no labels during learning or evaluation, but must map images from an unknown font or permutation to its correct class label. That is, at no point is our learner given labeled images, where an image vector is explicitly associated with a class label. Despite ample work in unsupervised and self-supervised loss functions, all current methods require a labeled fine-tuning phase to map the learned representations to correct classes. Finding this mapping in the absence of labels may seem a fool's errand, but our main result resolves this seeming paradox. We show that leveraging only letter bigram frequencies is sufficient for an unsupervised learner both to reliably associate images to class labels and to reliably identify trigger words in the sequence of inputs. More generally, this method suggests an approach for encoding specific desired innate behaviour in modality-agnostic models.
Transformer Layers as Painters
Jul 12, 2024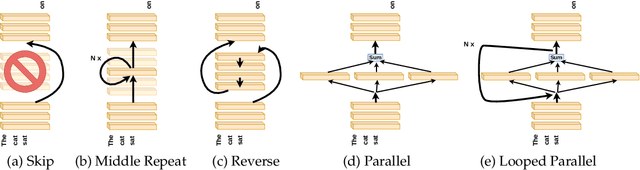
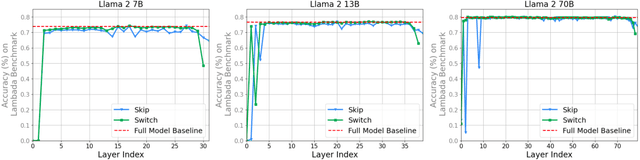
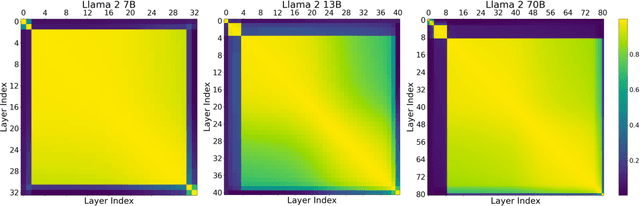
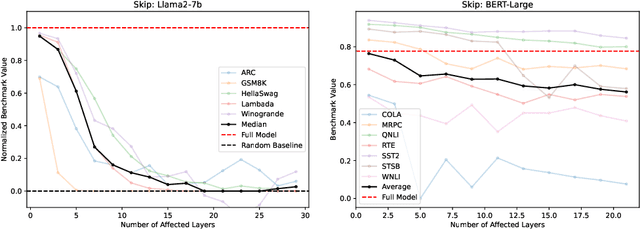
Despite their nearly universal adoption for large language models, the internal workings of transformers are not well understood. We aim to better understand the impact of removing or reorganizing information throughout the layers of a pretrained transformer. Such an understanding could both yield better usage of existing models as well as to make architectural improvements to produce new variants. We present a series of empirical studies on frozen models that show that the lower and final layers of pretrained transformers differ from middle layers, but that middle layers have a surprising amount of uniformity. We further show that some classes of problems have robustness to skipping layers, running the layers in an order different from how they were trained, or running the layers in parallel. Our observations suggest that even frozen pretrained models may gracefully trade accuracy for latency by skipping layers or running layers in parallel.
The Costly Dilemma: Generalization, Evaluation and Cost-Optimal Deployment of Large Language Models
Aug 15, 2023When deploying machine learning models in production for any product/application, there are three properties that are commonly desired. First, the models should be generalizable, in that we can extend it to further use cases as our knowledge of the domain area develops. Second they should be evaluable, so that there are clear metrics for performance and the calculation of those metrics in production settings are feasible. Finally, the deployment should be cost-optimal as far as possible. In this paper we propose that these three objectives (i.e. generalization, evaluation and cost-optimality) can often be relatively orthogonal and that for large language models, despite their performance over conventional NLP models, enterprises need to carefully assess all the three factors before making substantial investments in this technology. We propose a framework for generalization, evaluation and cost-modeling specifically tailored to large language models, offering insights into the intricacies of development, deployment and management for these large language models.