 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Ungrounded Alignment Problem
Aug 08, 2024



Modern machine learning systems have demonstrated substantial abilities with methods that either embrace or ignore human-provided knowledge, but combining benefits of both styles remains a challenge. One particular challenge involves designing learning systems that exhibit built-in responses to specific abstract stimulus patterns, yet are still plastic enough to be agnostic about the modality and exact form of their inputs. In this paper, we investigate what we call The Ungrounded Alignment Problem, which asks How can we build in predefined knowledge in a system where we don't know how a given stimulus will be grounded? This paper examines a simplified version of the general problem, where an unsupervised learner is presented with a sequence of images for the characters in a text corpus, and this learner is later evaluated on its ability to recognize specific (possibly rare) sequential patterns. Importantly, the learner is given no labels during learning or evaluation, but must map images from an unknown font or permutation to its correct class label. That is, at no point is our learner given labeled images, where an image vector is explicitly associated with a class label. Despite ample work in unsupervised and self-supervised loss functions, all current methods require a labeled fine-tuning phase to map the learned representations to correct classes. Finding this mapping in the absence of labels may seem a fool's errand, but our main result resolves this seeming paradox. We show that leveraging only letter bigram frequencies is sufficient for an unsupervised learner both to reliably associate images to class labels and to reliably identify trigger words in the sequence of inputs. More generally, this method suggests an approach for encoding specific desired innate behaviour in modality-agnostic models.
Better RAG using Relevant Information Gain
Jul 16, 2024



A common way to extend the memory of large language models (LLMs) is by retrieval augmented generation (RAG), which inserts text retrieved from a larger memory into an LLM's context window. However, the context window is typically limited to several thousand tokens, which limits the number of retrieved passages that can inform a model's response. For this reason, it's important to avoid occupying context window space with redundant information by ensuring a degree of diversity among retrieved passages. At the same time, the information should also be relevant to the current task. Most prior methods that encourage diversity among retrieved results, such as Maximal Marginal Relevance (MMR), do so by incorporating an objective that explicitly trades off diversity and relevance. We propose a novel simple optimization metric based on relevant information gain, a probabilistic measure of the total information relevant to a query for a set of retrieved results. By optimizing this metric, diversity organically emerges from our system. When used as a drop-in replacement for the retrieval component of a RAG system, this method yields state-of-the-art performance on question answering tasks from the Retrieval Augmented Generation Benchmark (RGB), outperforming existing metrics that directly optimize for relevance and diversity.
Transformer Layers as Painters
Jul 12, 2024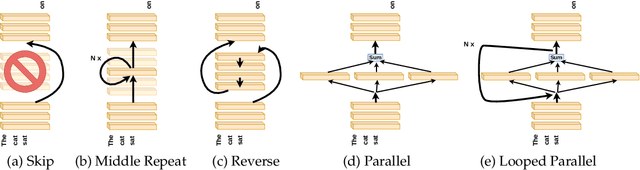
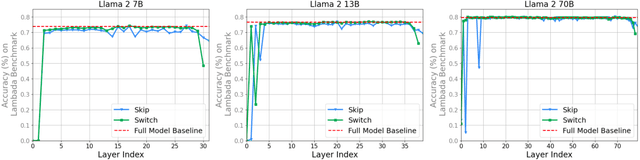
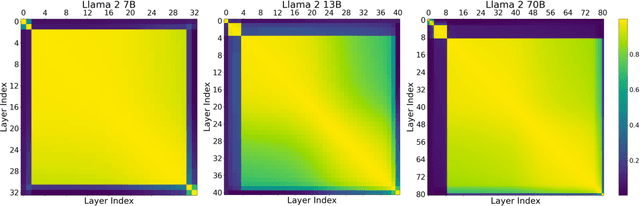
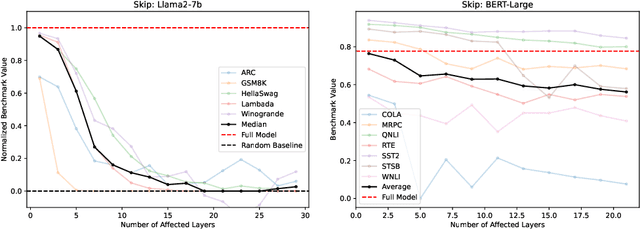
Despite their nearly universal adoption for large language models, the internal workings of transformers are not well understood. We aim to better understand the impact of removing or reorganizing information throughout the layers of a pretrained transformer. Such an understanding could both yield better usage of existing models as well as to make architectural improvements to produce new variants. We present a series of empirical studies on frozen models that show that the lower and final layers of pretrained transformers differ from middle layers, but that middle layers have a surprising amount of uniformity. We further show that some classes of problems have robustness to skipping layers, running the layers in an order different from how they were trained, or running the layers in parallel. Our observations suggest that even frozen pretrained models may gracefully trade accuracy for latency by skipping layers or running layers in parallel.
LaMDA: Language Models for Dialog Applications
Feb 10, 2022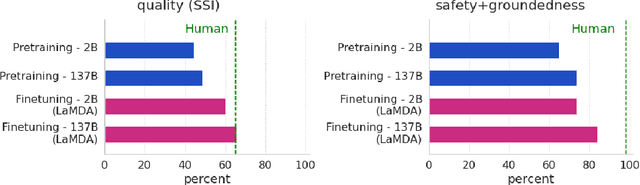
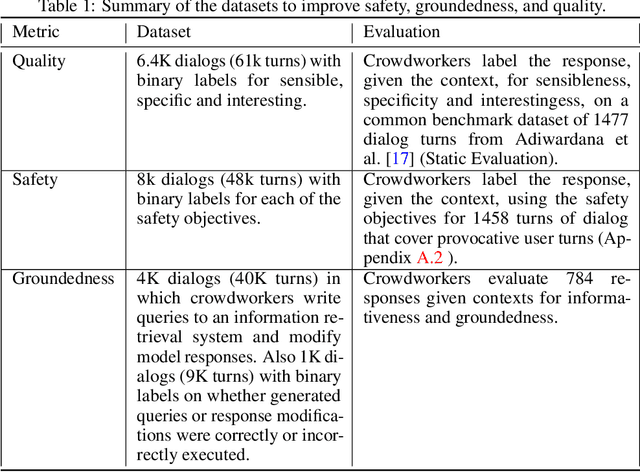

We present LaMDA: Language Models for Dialog Applications. LaMDA is a family of Transformer-based neural language models specialized for dialog, which have up to 137B parameters and are pre-trained on 1.56T words of public dialog data and web text. While model scaling alone can improve quality, it shows less improvements on safety and factual grounding. We demonstrate that fine-tuning with annotated data and enabling the model to consult external knowledge sources can lead to significant improvements towards the two key challenges of safety and factual grounding. The first challenge, safety, involves ensuring that the model's responses are consistent with a set of human values, such as preventing harmful suggestions and unfair bias. We quantify safety using a metric based on an illustrative set of human values, and we find that filtering candidate responses using a LaMDA classifier fine-tuned with a small amount of crowdworker-annotated data offers a promising approach to improving model safety. The second challenge, factual grounding, involves enabling the model to consult external knowledge sources, such as an information retrieval system, a language translator, and a calculator. We quantify factuality using a groundedness metric, and we find that our approach enables the model to generate responses grounded in known sources, rather than responses that merely sound plausible. Finally, we explore the use of LaMDA in the domains of education and content recommendations, and analyze their helpfulness and role consistency.
CVPR 2020 Continual Learning in Computer Vision Competition: Approaches, Results, Current Challenges and Future Directions
Sep 14, 2020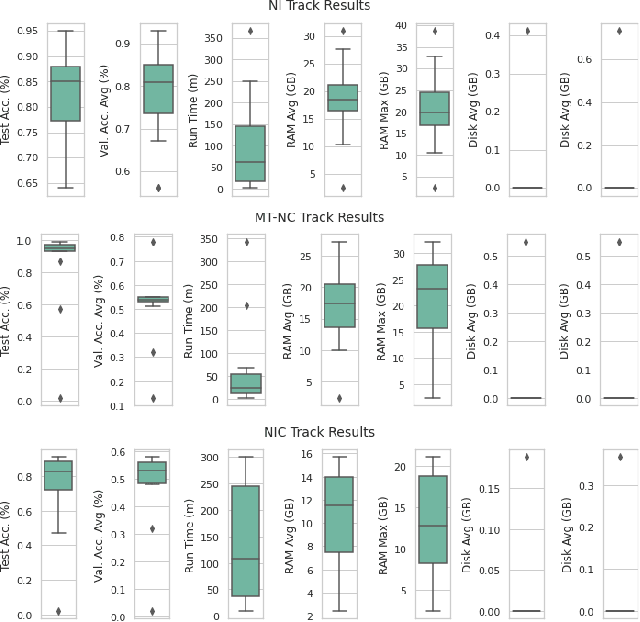

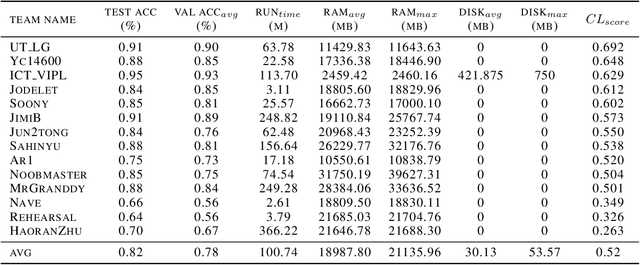
In the last few years, we have witnessed a renewed and fast-growing interest in continual learning with deep neural networks with the shared objective of making current AI systems more adaptive, efficient and autonomous. However, despite the significant and undoubted progress of the field in addressing the issue of catastrophic forgetting, benchmarking different continual learning approaches is a difficult task by itself. In fact, given the proliferation of different settings, training and evaluation protocols, metrics and nomenclature, it is often tricky to properly characterize a continual learning algorithm, relate it to other solutions and gauge its real-world applicability. The first Continual Learning in Computer Vision challenge held at CVPR in 2020 has been one of the first opportunities to evaluate different continual learning algorithms on a common hardware with a large set of shared evaluation metrics and 3 different settings based on the realistic CORe50 video benchmark. In this paper, we report the main results of the competition, which counted more than 79 teams registered, 11 finalists and 2300$ in prizes. We also summarize the winning approaches, current challenges and future research directions.
A Brief Study of In-Domain Transfer and Learning from Fewer Samples using A Few Simple Priors
Jul 13, 2017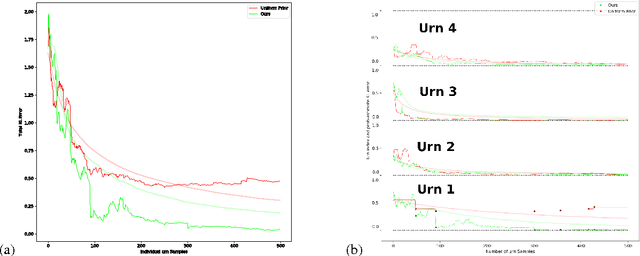
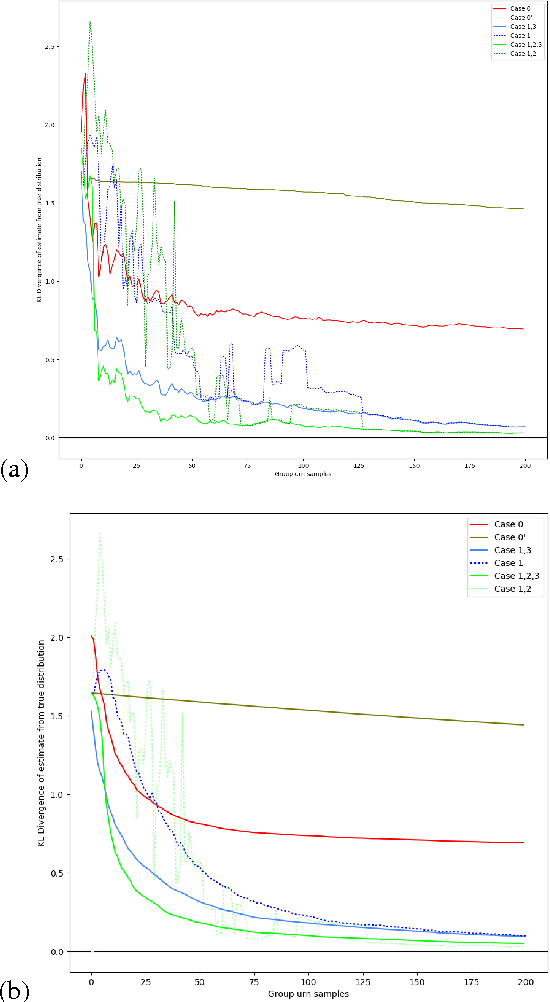
Domain knowledge can often be encoded in the structure of a network, such as convolutional layers for vision, which has been shown to increase generalization and decrease sample complexity, or the number of samples required for successful learning. In this study, we ask whether sample complexity can be reduced for systems where the structure of the domain is unknown beforehand, and the structure and parameters must both be learned from the data. We show that sample complexity reduction through learning structure is possible for at least two simple cases. In studying these cases, we also gain insight into how this might be done for more complex domains.
A Growing Long-term Episodic & Semantic Memory
Oct 20, 2016
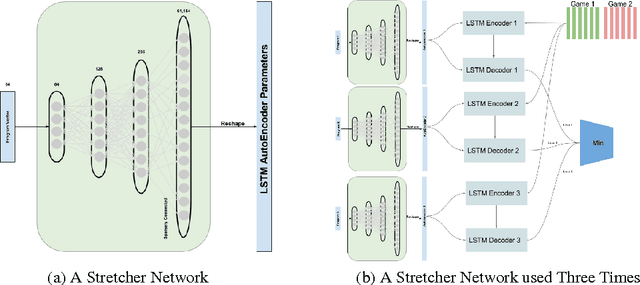
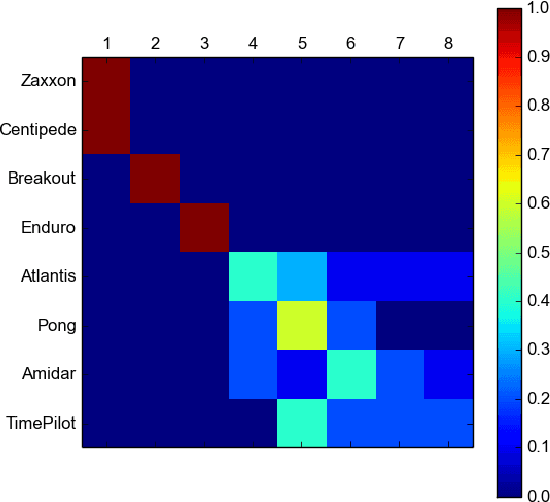
The long-term memory of most connectionist systems lies entirely in the weights of the system. Since the number of weights is typically fixed, this bounds the total amount of knowledge that can be learned and stored. Though this is not normally a problem for a neural network designed for a specific task, such a bound is undesirable for a system that continually learns over an open range of domains. To address this, we describe a lifelong learning system that leverages a fast, though non-differentiable, content-addressable memory which can be exploited to encode both a long history of sequential episodic knowledge and semantic knowledge over many episodes for an unbounded number of domains. This opens the door for investigation into transfer learning, and leveraging prior knowledge that has been learned over a lifetime of experiences to new domains.
Conversational Contextual Cues: The Case of Personalization and History for Response Ranking
Jun 01, 2016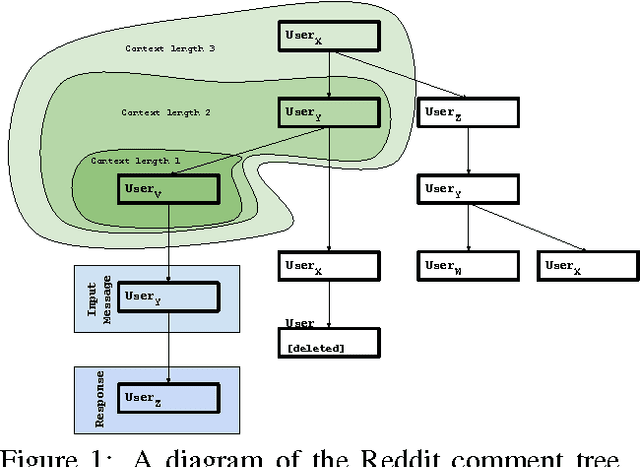
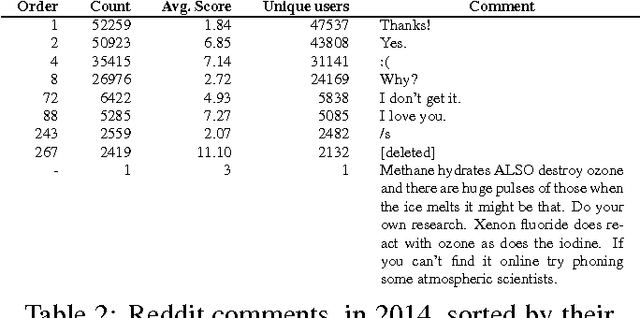
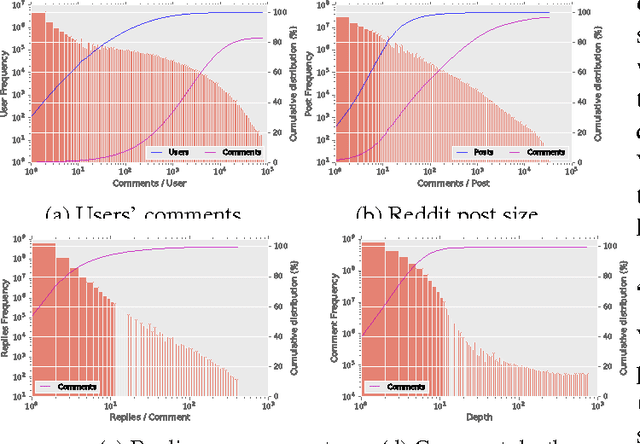
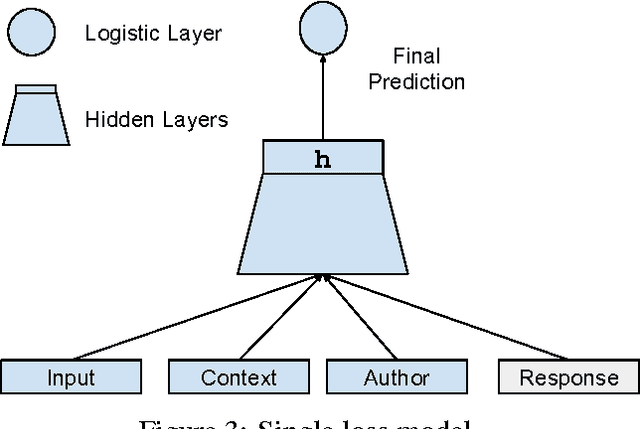
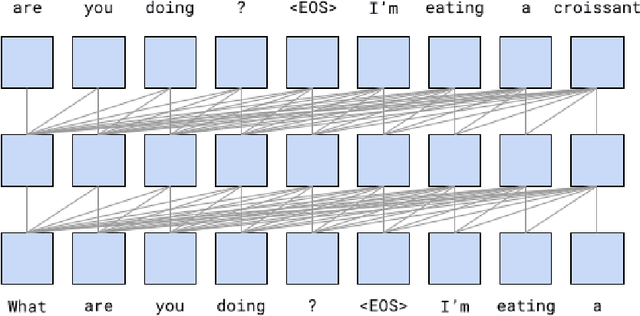
We investigate the task of modeling open-domain, multi-turn, unstructured, multi-participant, conversational dialogue. We specifically study the effect of incorporating different elements of the conversation. Unlike previous efforts, which focused on modeling messages and responses, we extend the modeling to long context and participant's history. Our system does not rely on handwritten rules or engineered features; instead, we train deep neural networks on a large conversational dataset. In particular, we exploit the structure of Reddit comments and posts to extract 2.1 billion messages and 133 million conversations. We evaluate our models on the task of predicting the next response in a conversation, and we find that modeling both context and participants improves prediction accuracy.
Spontaneous Analogy by Piggybacking on a Perceptual System
Oct 10, 2013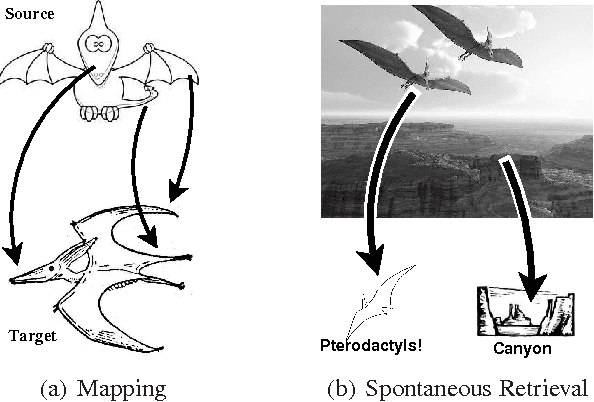


Most computational models of analogy assume they are given a delineated source domain and often a specified target domain. These systems do not address how analogs can be isolated from large domains and spontaneously retrieved from long-term memory, a process we call spontaneous analogy. We present a system that represents relational structures as feature bags. Using this representation, our system leverages perceptual algorithms to automatically create an ontology of relational structures and to efficiently retrieve analogs for new relational structures from long-term memory. We provide a demonstration of our approach that takes a set of unsegmented stories, constructs an ontology of analogical schemas (corresponding to plot devices), and uses this ontology to efficiently find analogs within new stories, yielding significant time-savings over linear analog retrieval at a small accuracy cost.