 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitive Mapping and Planning for Visual Navigation
Feb 07, 2019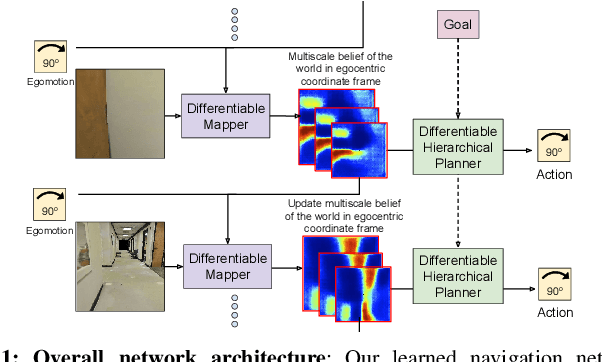
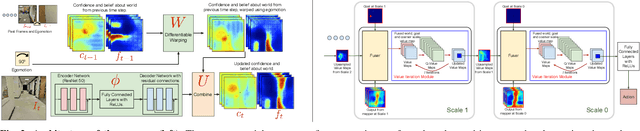
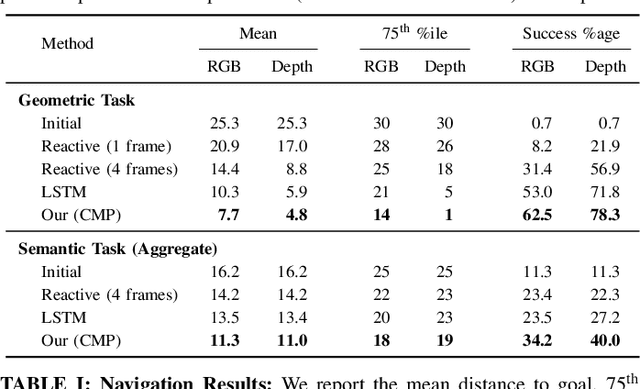
We introduce a neural architecture for navigation in novel environments. Our proposed architecture learns to map from first-person views and plans a sequence of actions towards goals in the environment. The Cognitive Mapper and Planner (CMP) is based on two key ideas: a) a unified joint architecture for mapping and planning, such that the mapping is driven by the needs of the task, and b) a spatial memory with the ability to plan given an incomplete set of observations about the world. CMP constructs a top-down belief map of the world and applies a differentiable neural net planner to produce the next action at each time step. The accumulated belief of the world enables the agent to track visited regions of the environment. We train and test CMP on navigation problems in simulation environments derived from scans of real world buildings. Our experiments demonstrate that CMP outperforms alternate learning-based architectures, as well as, classical mapping and path planning approaches in many cases. Furthermore, it naturally extends to semantically specified goals, such as 'going to a chair'. We also deploy CMP on physical robots in indoor environments, where it achieves reasonable performance, even though it is trained entirely in simulation.
Learning Latent Dynamics for Planning from Pixels
Dec 03, 2018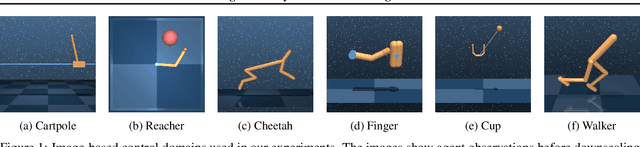



Planning has been very successful for control tasks with known environment dynamics. To leverage planning in unknown environments, the agent needs to learn the dynamics from interactions with the world. However, learning dynamics models that are accurate enough for planning has been a long-standing challenge, especially in image-based domains. We propose the Deep Planning Network (PlaNet), a purely model-based agent that learns the environment dynamics from pixels and chooses actions through online planning in latent space. To achieve high performance, the dynamics model must accurately predict the rewards ahead for multiple time steps. We approach this problem using a latent dynamics model with both deterministic and stochastic transition function and a generalized variational inference objective that we name latent overshooting. Using only pixel observations, our agent solves continuous control tasks with contact dynamics, partial observability, and sparse rewards. PlaNet uses significantly fewer episodes and reaches final performance close to and sometimes higher than top model-free algorithms.
Modulated Policy Hierarchies
Nov 30, 2018
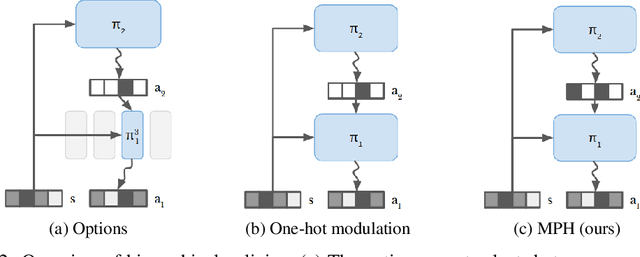
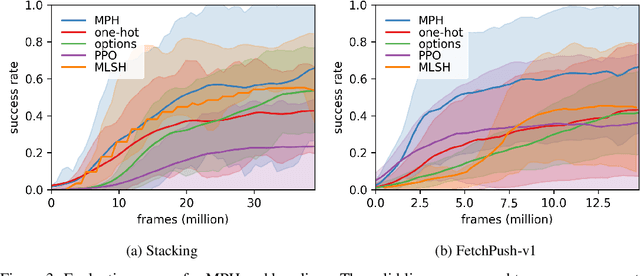

Solving tasks with sparse rewards is a main challenge in reinforcement learning. While hierarchical controllers are an intuitive approach to this problem, current methods often require manual reward shaping, alternating training phases, or manually defined sub tasks. We introduce modulated policy hierarchies (MPH), that can learn end-to-end to solve tasks from sparse rewards. To achieve this, we study different modulation signals and exploration for hierarchical controllers. Specifically, we find that communicating via bit-vectors is more efficient than selecting one out of multiple skills, as it enables mixing between them. To facilitate exploration, MPH uses its different time scales for temporally extended intrinsic motivation at each level of the hierarchy. We evaluate MPH on the robotics tasks of pushing and sparse block stacking, where it outperforms recent baselines.
TensorFlow Agents: Efficient Batched Reinforcement Learning in TensorFlow
Oct 31, 2018

We introduce TensorFlow Agents, an efficient infrastructure paradigm for building parallel reinforcement learning algorithms in TensorFlow. We simulate multiple environments in parallel, and group them to perform the neural network computation on a batch rather than individual observations. This allows the TensorFlow execution engine to parallelize computation, without the need for manual synchronization. Environments are stepped in separate Python processes to progress them in parallel without interference of the global interpreter lock. As part of this project, we introduce BatchPPO, an efficient implementation of the proximal policy optimization algorithm. By open sourcing TensorFlow Agents, we hope to provide a flexible starting point for future projects that accelerates future research in the field.
Reliable Uncertainty Estimates in Deep Neural Networks using Noise Contrastive Priors
Oct 31, 2018


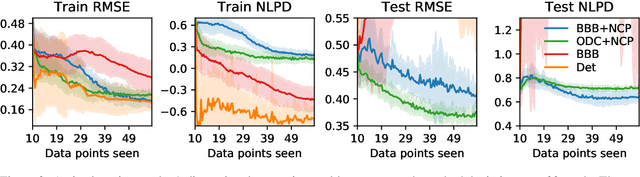
Obtaining reliable uncertainty estimates of neural network predictions is a long standing challenge. Bayesian neural networks have been proposed as a solution, but it remains open how to specify their prior. In particular, the common practice of a standard normal prior in weight space imposes only weak regularities, causing the function posterior to possibly generalize in unforeseen ways on inputs outside of the training distribution. We propose noise contrastive priors (NCPs) to obtain reliable uncertainty estimates. The key idea is to train the model to output high uncertainty for data points outside of the training distribution. NCPs do so using an input prior, which adds noise to the inputs of the current mini batch, and an output prior, which is a wide distribution given these inputs. NCPs are compatible with any model that can output uncertainty estimates, are easy to scale, and yield reliable uncertainty estimates throughout training. Empirically, we show that NCPs prevent overfitting outside of the training distribution and result in uncertainty estimates that are useful for active learning. We demonstrate the scalability of our method on the flight delays data set, where we significantly improve upon previously published results.
Interpretable Intuitive Physics Model
Aug 29, 2018



Humans have a remarkable ability to use physical commonsense and predict the effect of collisions. But do they understand the underlying factors? Can they predict if the underlying factors have changed? Interestingly, in most cases humans can predict the effects of similar collisions with different conditions such as changes in mass, friction, etc. It is postulated this is primarily because we learn to model physics with meaningful latent variables. This does not imply we can estimate the precise values of these meaningful variables (estimate exact values of mass or friction). Inspired by this observation, we propose an interpretable intuitive physics model where specific dimensions in the bottleneck layers correspond to different physical properties. In order to demonstrate that our system models these underlying physical properties, we train our model on collisions of different shapes (cube, cone, cylinder, spheres etc.) and test on collisions of unseen combinations of shapes. Furthermore, we demonstrate our model generalizes well even when similar scenes are simulated with different underlying properties.
Discrete Sequential Prediction of Continuous Actions for Deep RL
Jun 16, 2018



It has long been assumed that high dimensional continuous control problems cannot be solved effectively by discretizing individual dimensions of the action space due to the exponentially large number of bins over which policies would have to be learned. In this paper, we draw inspiration from the recent success of sequence-to-sequence models for structured prediction problems to develop policies over discretized spaces. Central to this method is the realization that complex functions over high dimensional spaces can be modeled by neural networks that predict one dimension at a time. Specifically, we show how Q-values and policies over continuous spaces can be modeled using a next step prediction model over discretized dimensions. With this parameterization, it is possible to both leverage the compositional structure of action spaces during learning, as well as compute maxima over action spaces (approximately). On a simple example task we demonstrate empirically that our method can perform global search, which effectively gets around the local optimization issues that plague DDPG. We apply the technique to off-policy (Q-learning) methods and show that our method can achieve the state-of-the-art for off-policy methods on several continuous control tasks.
Learning 6-DOF Grasping Interaction via Deep Geometry-aware 3D Representations
Jun 15, 2018
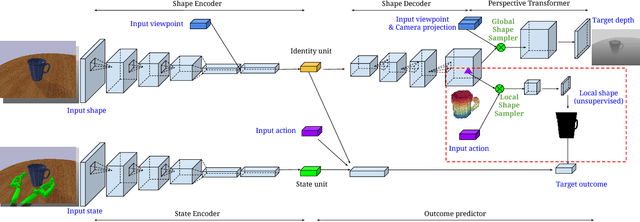
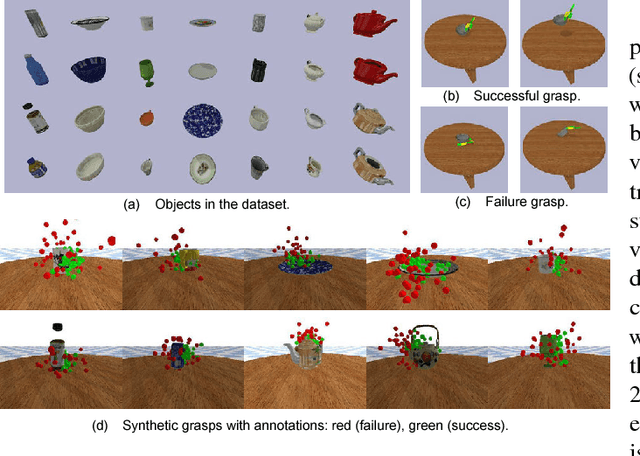
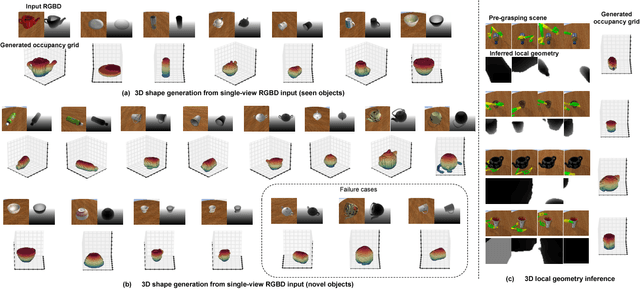
This paper focuses on the problem of learning 6-DOF grasping with a parallel jaw gripper in simulation. We propose the notion of a geometry-aware representation in grasping based on the assumption that knowledge of 3D geometry is at the heart of interaction. Our key idea is constraining and regularizing grasping interaction learning through 3D geometry prediction. Specifically, we formulate the learning of deep geometry-aware grasping model in two steps: First, we learn to build mental geometry-aware representation by reconstructing the scene (i.e., 3D occupancy grid) from RGBD input via generative 3D shape modeling. Second, we learn to predict grasping outcome with its internal geometry-aware representation. The learned outcome prediction model is used to sequentially propose grasping solutions via analysis-by-synthesis optimization. Our contributions are fourfold: (1) To best of our knowledge, we are presenting for the first time a method to learn a 6-DOF grasping net from RGBD input; (2) We build a grasping dataset from demonstrations in virtual reality with rich sensory and interaction annotations. This dataset includes 101 everyday objects spread across 7 categories, additionally, we propose a data augmentation strategy for effective learning; (3) We demonstrate that the learned geometry-aware representation leads to about 10 percent relative performance improvement over the baseline CNN on grasping objects from our dataset. (4) We further demonstrate that the model generalizes to novel viewpoints and object instances.
PRM-RL: Long-range Robotic Navigation Tasks by Combining Reinforcement Learning and Sampling-based Planning
May 16, 2018
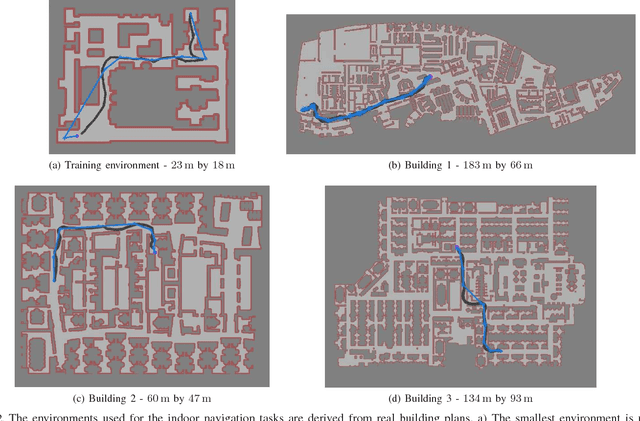

We present PRM-RL, a hierarchical method for long-range navigation task completion that combines sampling based path planning with reinforcement learning (RL). The RL agents learn short-range, point-to-point navigation policies that capture robot dynamics and task constraints without knowledge of the large-scale topology. Next, the sampling-based planners provide roadmaps which connect robot configurations that can be successfully navigated by the RL agent. The same RL agents are used to control the robot under the direction of the planning, enabling long-range navigation. We use the Probabilistic Roadmaps (PRMs) for the sampling-based planner. The RL agents are constructed using feature-based and deep neural net policies in continuous state and action spaces. We evaluate PRM-RL, both in simulation and on-robot, on two navigation tasks with non-trivial robot dynamics: end-to-end differential drive indoor navigation in office environments, and aerial cargo delivery in urban environments with load displacement constraints. Our results show improvement in task completion over both RL agents on their own and traditional sampling-based planners. In the indoor navigation task, PRM-RL successfully completes up to 215 m long trajectories under noisy sensor conditions, and the aerial cargo delivery completes flights over 1000 m without violating the task constraints in an environment 63 million times larger than used in training.
* 9 pages, 7 figures
Visual Representations for Semantic Target Driven Navigation
May 15, 2018
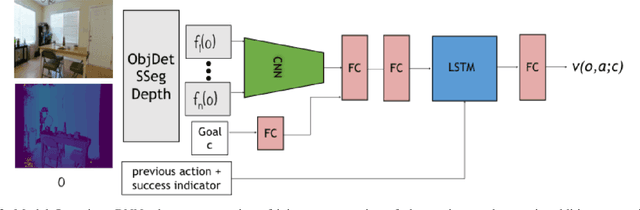
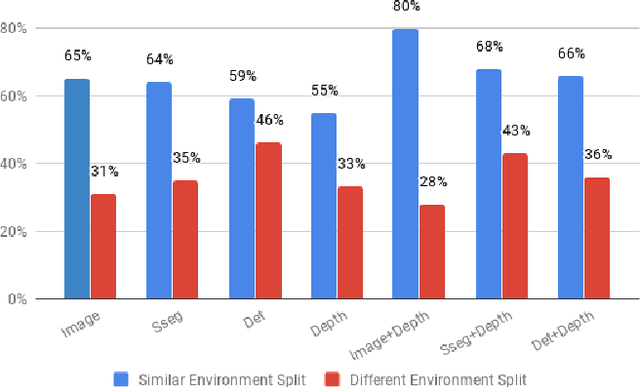
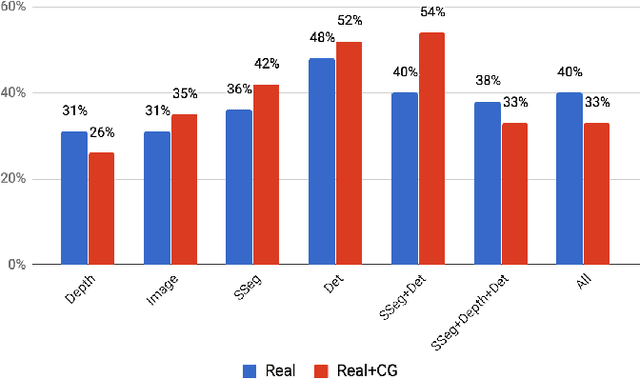
What is a good visual representation for autonomous agents? We address this question in the context of semantic visual navigation, which is the problem of a robot finding its way through a complex environment to a target object, e.g. go to the refrigerator. Instead of acquiring a metric semantic map of an environment and using planning for navigation, our approach learns navigation policies on top of representations that capture spatial layout and semantic contextual cues. We propose to using high level semantic and contextual features including segmentation and detection masks obtained by off-the-shelf state-of- the-art vision as observations and use deep network to learn the navigation policy. This choice allows using additional data, from orthogonal sources, to better train different parts of the model the representation extraction is trained on large standard vision datasets while the navigation component leverages large synthetic environments for training. This combination of real and synthetic is possible because equitable feature representations are available in both (e.g., segmentation and detection masks), which alleviates the need for domain adaptation. Both the representation and the navigation policy can be readily applied to real non-synthetic environments as demonstrated on the Active Vision Dataset [1]. Our approach gets successfully to the target in 54% of the cases in unexplored environments, compared to 46% for non-learning based approach, and 28% for the learning-based baseline.