 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefensive Escort Teams via Multi-Agent Deep Reinforcement Learning
Oct 09, 2019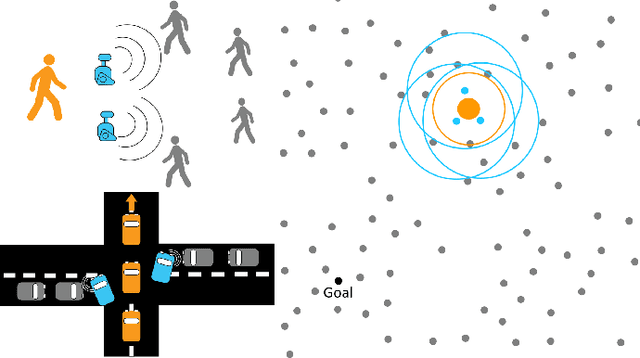
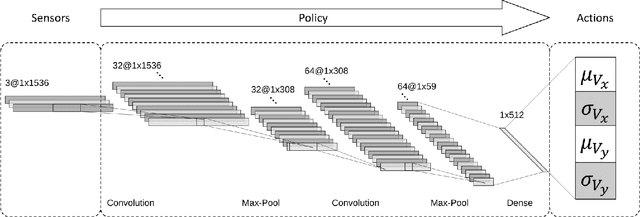
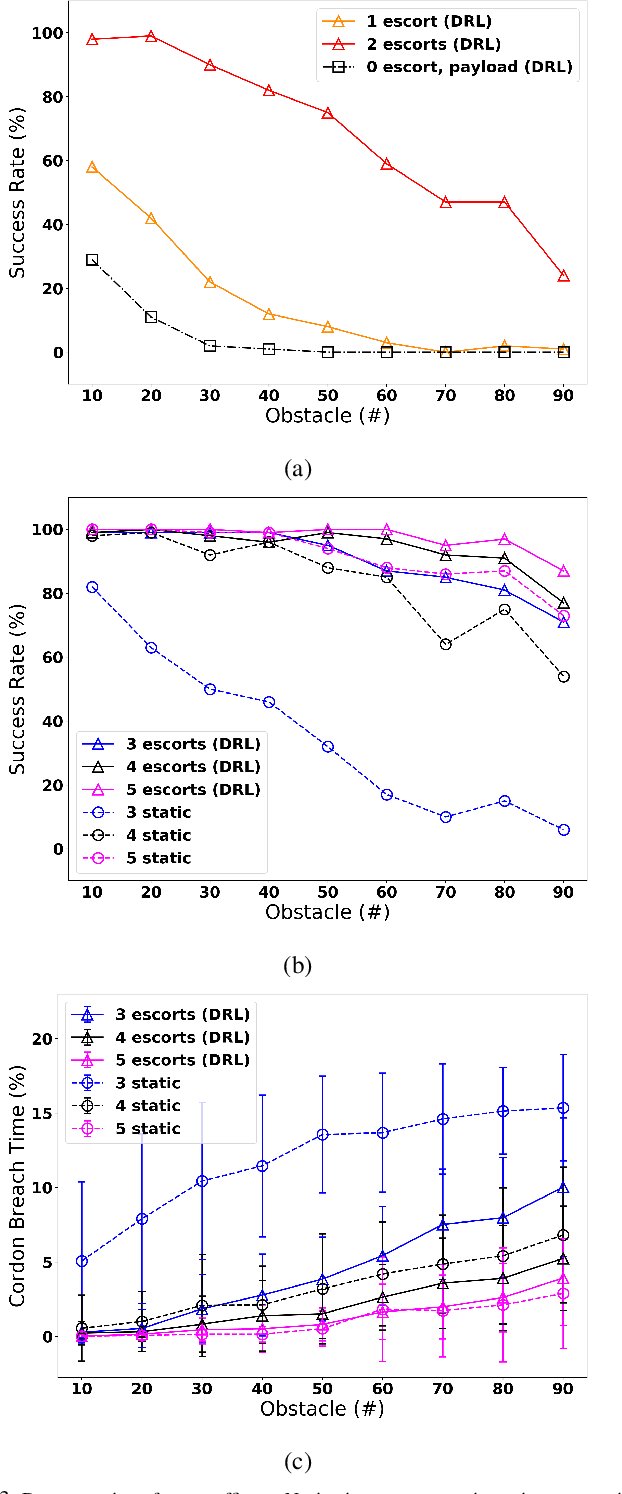
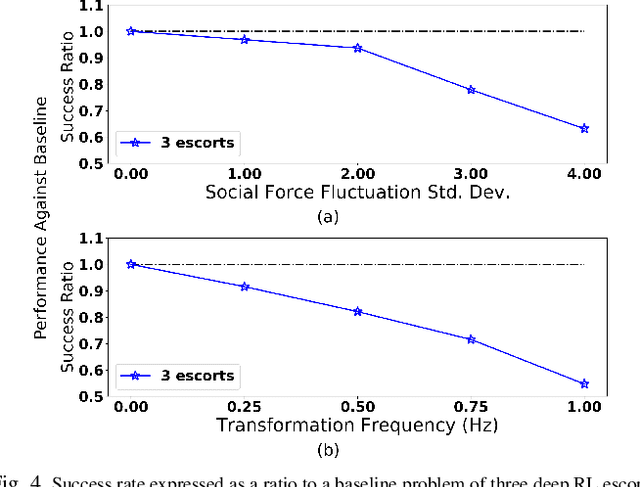
Coordinated defensive escorts can aid a navigating payload by positioning themselves in order to maintain the safety of the payload from obstacles. In this paper, we present a novel, end-to-end solution for coordinating an escort team for protecting high-value payloads. Our solution employs deep reinforcement learning (RL) in order to train a team of escorts to maintain payload safety while navigating alongside the payload. This is done in a distributed fashion, relying only on limited range positional information of other escorts, the payload, and the obstacles. When compared to a state-of-art algorithm for obstacle avoidance, our solution with a single escort increases navigation success up to 31%. Additionally, escort teams increase success rate by up to 75% percent over escorts in static formations. We also show that this learned solution is general to several adaptations in the scenario including: a changing number of escorts in the team, changing obstacle density, and changes in payload conformation. Video: https://youtu.be/SoYesKti4VA.
RL-RRT: Kinodynamic Motion Planning via Learning Reachability Estimators from RL Policies
Jul 12, 2019


This paper addresses two challenges facing sampling-based kinodynamic motion planning: a way to identify good candidate states for local transitions and the subsequent computationally intractable steering between these candidate states. Through the combination of sampling-based planning, a Rapidly Exploring Randomized Tree (RRT) and an efficient kinodynamic motion planner through machine learning, we propose an efficient solution to long-range planning for kinodynamic motion planning. First, we use deep reinforcement learning to learn an obstacle-avoiding policy that maps a robot's sensor observations to actions, which is used as a local planner during planning and as a controller during execution. Second, we train a reachability estimator in a supervised manner, which predicts the RL policy's time to reach a state in the presence of obstacles. Lastly, we introduce RL-RRT that uses the RL policy as a local planner, and the reachability estimator as the distance function to bias tree-growth towards promising regions. We evaluate our method on three kinodynamic systems, including physical robot experiments. Results across all three robots tested indicate that RL-RRT outperforms state of the art kinodynamic planners in efficiency, and also provides a shorter path finish time than a steering function free method. The learned local planner policy and accompanying reachability estimator demonstrate transferability to the previously unseen experimental environments, making RL-RRT fast because the expensive computations are replaced with simple neural network inference. Video: https://youtu.be/dDMVMTOI8KY
* Accepted to Robotics and Automation Letters in June 2019
PEARL: PrEference Appraisal Reinforcement Learning for Motion Planning
Nov 30, 2018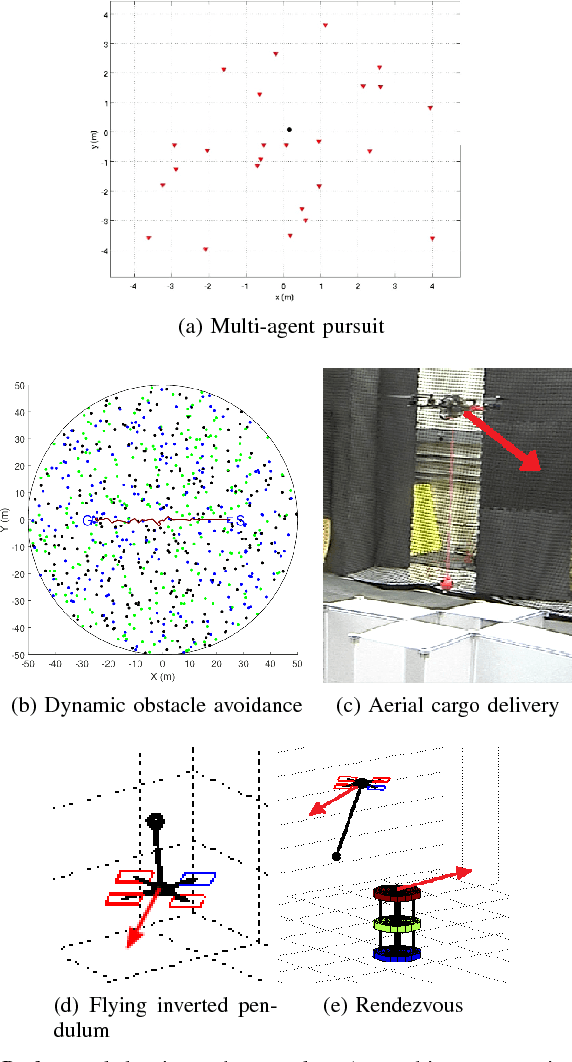
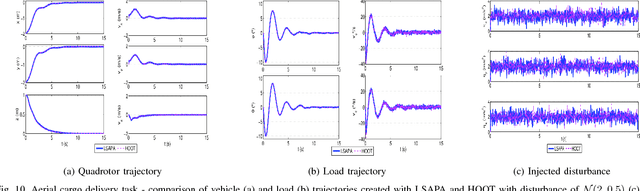
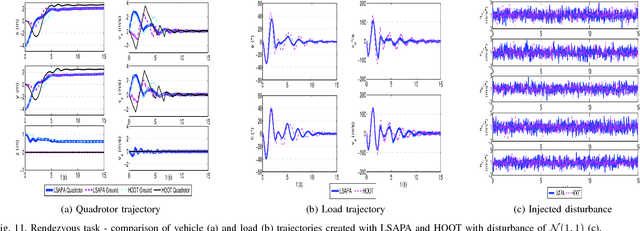
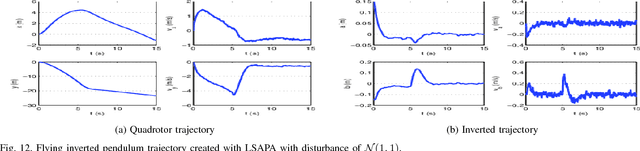
Robot motion planning often requires finding trajectories that balance different user intents, or preferences. One of these preferences is usually arrival at the goal, while another might be obstacle avoidance. Here, we formalize these, and similar, tasks as preference balancing tasks (PBTs) on acceleration controlled robots, and propose a motion planning solution, PrEference Appraisal Reinforcement Learning (PEARL). PEARL uses reinforcement learning on a restricted training domain, combined with features engineered from user-given intents. PEARL's planner then generates trajectories in expanded domains for more complex problems. We present an adaptation for rejection of stochastic disturbances and offer in-depth analysis, including task completion conditions and behavior analysis when the conditions do not hold. PEARL is evaluated on five problems, two multi-agent obstacle avoidance tasks and three that stochastically disturb the system at run-time: 1) a multi-agent pursuit problem with 1000 pursuers, 2) robot navigation through 900 moving obstacles, which is is trained with in an environment with only 4 static obstacles, 3) aerial cargo delivery, 4) two robot rendezvous, and 5) flying inverted pendulum. Lastly, we evaluate the method on a physical quadrotor UAV robot with a suspended load influenced by a stochastic disturbance. The video, https://youtu.be/ZkFt1uY6vlw contains the experiments and visualization of the simulations.
Resilient Computing with Reinforcement Learning on a Dynamical System: Case Study in Sorting
Sep 25, 2018

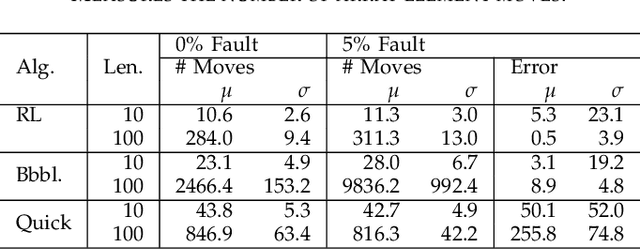

Robots and autonomous agents often complete goal-based tasks with limited resources, relying on imperfect models and sensor measurements. In particular, reinforcement learning (RL) and feedback control can be used to help a robot achieve a goal. Taking advantage of this body of work, this paper formulates general computation as a feedback-control problem, which allows the agent to autonomously overcome some limitations of standard procedural language programming: resilience to errors and early program termination. Our formulation considers computation to be trajectory generation in the program's variable space. The computing then becomes a sequential decision making problem, solved with reinforcement learning (RL), and analyzed with Lyapunov stability theory to assess the agent's resilience and progression to the goal. We do this through a case study on a quintessential computer science problem, array sorting. Evaluations show that our RL sorting agent makes steady progress to an asymptotically stable goal, is resilient to faulty components, and performs less array manipulations than traditional Quicksort and Bubble sort.
Deep Neural Networks for Swept Volume Prediction Between Configurations
May 29, 2018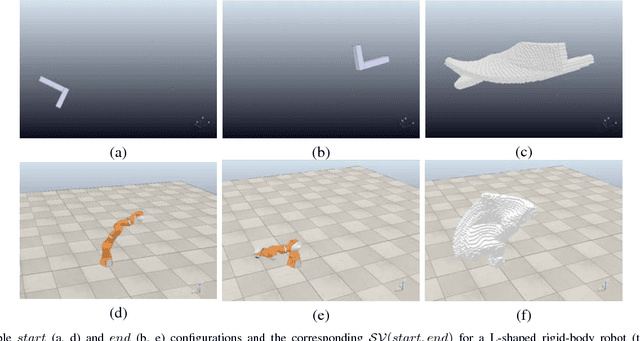
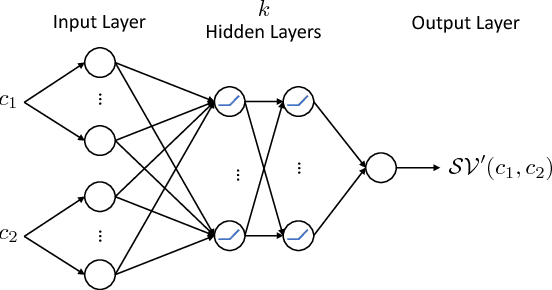
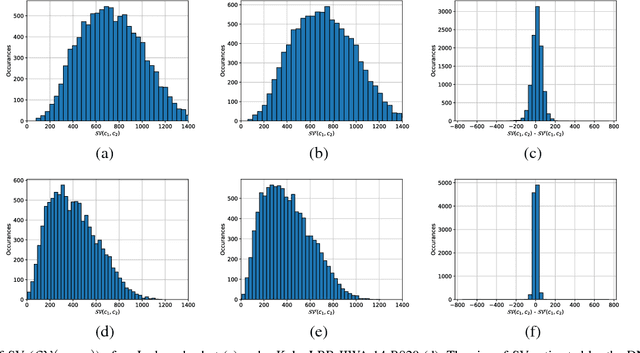
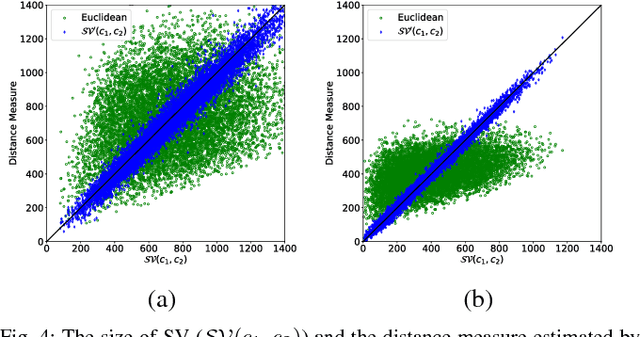
Swept Volume (SV), the volume displaced by an object when it is moving along a trajectory, is considered a useful metric for motion planning. First, SV has been used to identify collisions along a trajectory, because it directly measures the amount of space required for an object to move. Second, in sampling-based motion planning, SV is an ideal distance metric, because it correlates to the likelihood of success of the expensive local planning step between two sampled configurations. However, in both of these applications, traditional SV algorithms are too computationally expensive for efficient motion planning. In this work, we train Deep Neural Networks (DNNs) to learn the size of SV for specific robot geometries. Results for two robots, a 6 degree of freedom (DOF) rigid body and a 7 DOF fixed-based manipulator, indicate that the network estimations are very close to the true size of SV and is more than 1500 times faster than a state of the art SV estimation algorithm.
PRM-RL: Long-range Robotic Navigation Tasks by Combining Reinforcement Learning and Sampling-based Planning
May 16, 2018
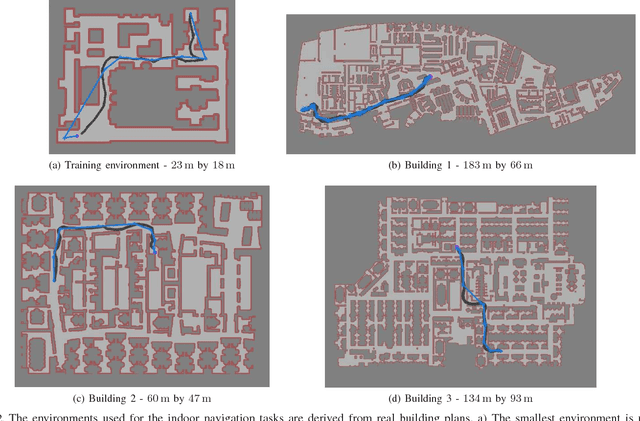

We present PRM-RL, a hierarchical method for long-range navigation task completion that combines sampling based path planning with reinforcement learning (RL). The RL agents learn short-range, point-to-point navigation policies that capture robot dynamics and task constraints without knowledge of the large-scale topology. Next, the sampling-based planners provide roadmaps which connect robot configurations that can be successfully navigated by the RL agent. The same RL agents are used to control the robot under the direction of the planning, enabling long-range navigation. We use the Probabilistic Roadmaps (PRMs) for the sampling-based planner. The RL agents are constructed using feature-based and deep neural net policies in continuous state and action spaces. We evaluate PRM-RL, both in simulation and on-robot, on two navigation tasks with non-trivial robot dynamics: end-to-end differential drive indoor navigation in office environments, and aerial cargo delivery in urban environments with load displacement constraints. Our results show improvement in task completion over both RL agents on their own and traditional sampling-based planners. In the indoor navigation task, PRM-RL successfully completes up to 215 m long trajectories under noisy sensor conditions, and the aerial cargo delivery completes flights over 1000 m without violating the task constraints in an environment 63 million times larger than used in training.
* 9 pages, 7 figures