 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Behavioral Cloning
Sep 01, 2021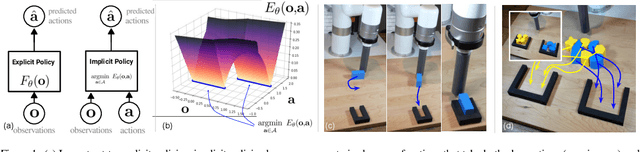

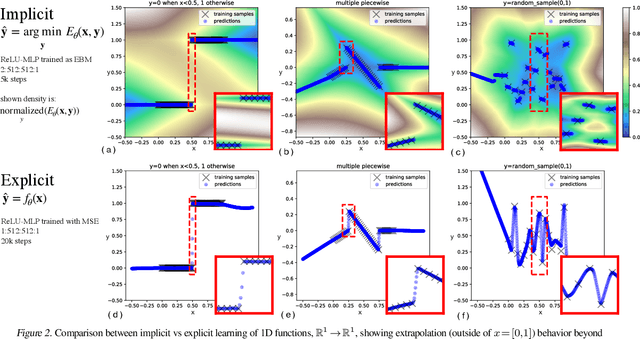
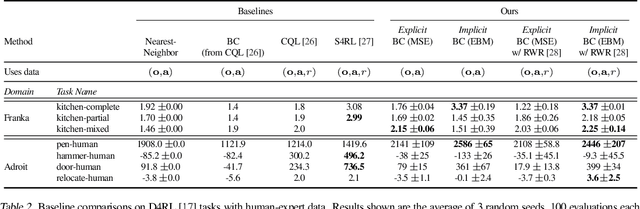
We find that across a wide range of robot policy learning scenarios, treating supervised policy learning with an implicit model generally performs better, on average, than commonly used explicit models. We present extensive experiments on this finding, and we provide both intuitive insight and theoretical arguments distinguishing the properties of implicit models compared to their explicit counterparts, particularly with respect to approximating complex, potentially discontinuous and multi-valued (set-valued) functions. On robotic policy learning tasks we show that implicit behavioral cloning policies with energy-based models (EBM) often outperform common explicit (Mean Square Error, or Mixture Density) behavioral cloning policies, including on tasks with high-dimensional action spaces and visual image inputs. We find these policies provide competitive results or outperform state-of-the-art offline reinforcement learning methods on the challenging human-expert tasks from the D4RL benchmark suite, despite using no reward information. In the real world, robots with implicit policies can learn complex and remarkably subtle behaviors on contact-rich tasks from human demonstrations, including tasks with high combinatorial complexity and tasks requiring 1mm precision.
The Distracting Control Suite -- A Challenging Benchmark for Reinforcement Learning from Pixels
Jan 07, 2021
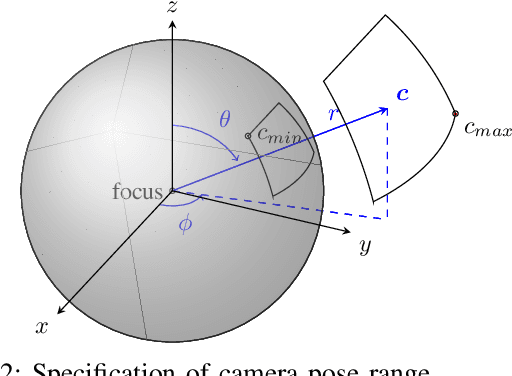
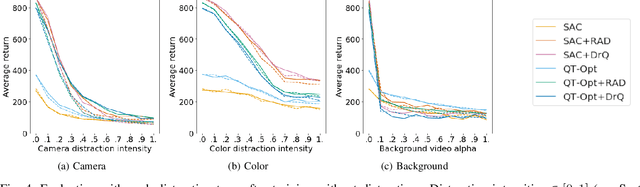
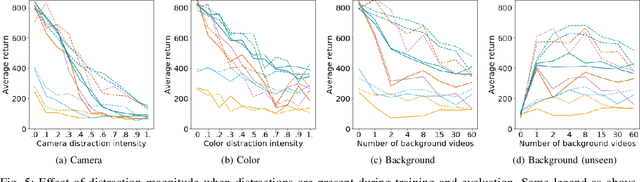
Robots have to face challenging perceptual settings, including changes in viewpoint, lighting, and background. Current simulated reinforcement learning (RL) benchmarks such as DM Control provide visual input without such complexity, which limits the transfer of well-performing methods to the real world. In this paper, we extend DM Control with three kinds of visual distractions (variations in background, color, and camera pose) to produce a new challenging benchmark for vision-based control, and we analyze state of the art RL algorithms in these settings. Our experiments show that current RL methods for vision-based control perform poorly under distractions, and that their performance decreases with increasing distraction complexity, showing that new methods are needed to cope with the visual complexities of the real world. We also find that combinations of multiple distraction types are more difficult than a mere combination of their individual effects.
PRM-RL: Long-range Robotic Navigation Tasks by Combining Reinforcement Learning and Sampling-based Planning
May 16, 2018
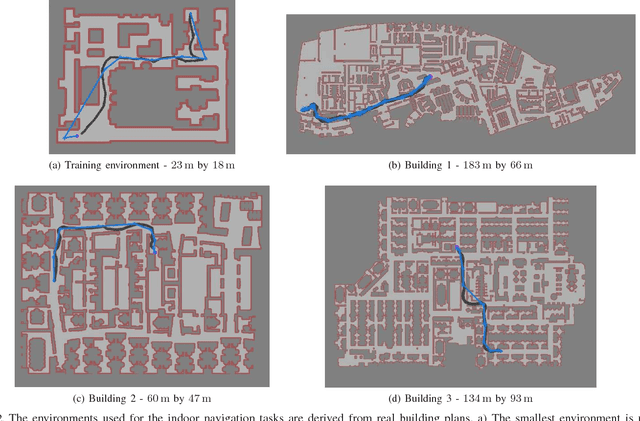

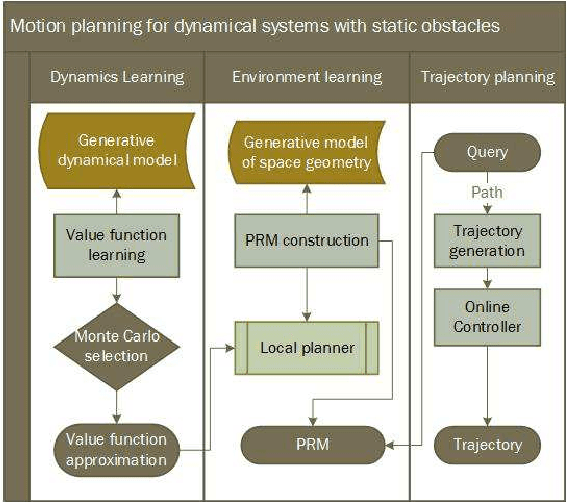
We present PRM-RL, a hierarchical method for long-range navigation task completion that combines sampling based path planning with reinforcement learning (RL). The RL agents learn short-range, point-to-point navigation policies that capture robot dynamics and task constraints without knowledge of the large-scale topology. Next, the sampling-based planners provide roadmaps which connect robot configurations that can be successfully navigated by the RL agent. The same RL agents are used to control the robot under the direction of the planning, enabling long-range navigation. We use the Probabilistic Roadmaps (PRMs) for the sampling-based planner. The RL agents are constructed using feature-based and deep neural net policies in continuous state and action spaces. We evaluate PRM-RL, both in simulation and on-robot, on two navigation tasks with non-trivial robot dynamics: end-to-end differential drive indoor navigation in office environments, and aerial cargo delivery in urban environments with load displacement constraints. Our results show improvement in task completion over both RL agents on their own and traditional sampling-based planners. In the indoor navigation task, PRM-RL successfully completes up to 215 m long trajectories under noisy sensor conditions, and the aerial cargo delivery completes flights over 1000 m without violating the task constraints in an environment 63 million times larger than used in training.
* 9 pages, 7 figures