 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoogle Scanned Objects: A High-Quality Dataset of 3D Scanned Household Items
Apr 25, 2022
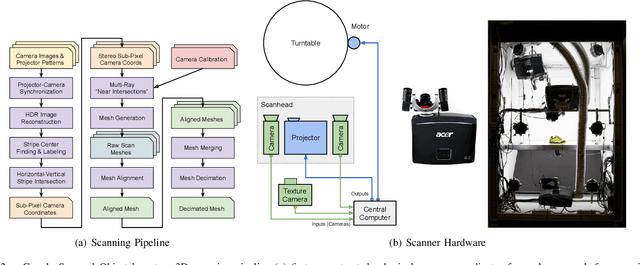

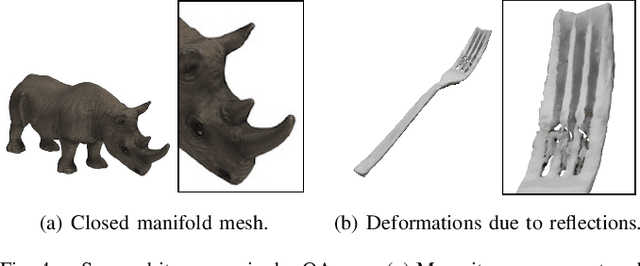
Interactive 3D simulations have enabled breakthroughs in robotics and computer vision, but simulating the broad diversity of environments needed for deep learning requires large corpora of photo-realistic 3D object models. To address this need, we present Google Scanned Objects, an open-source collection of over one thousand 3D-scanned household items released under a Creative Commons license; these models are preprocessed for use in Ignition Gazebo and the Bullet simulation platforms, but are easily adaptable to other simulators. We describe our object scanning and curation pipeline, then provide statistics about the contents of the dataset and its usage. We hope that the diversity, quality, and flexibility of Google Scanned Objects will lead to advances in interactive simulation, synthetic perception, and robotic learning.
Implicit Behavioral Cloning
Sep 01, 2021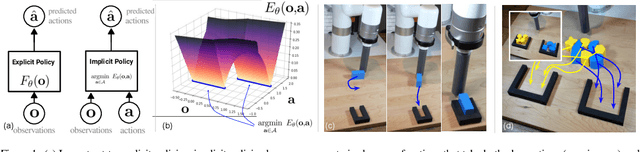

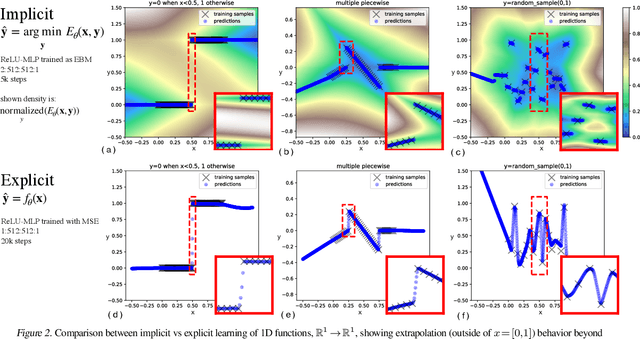
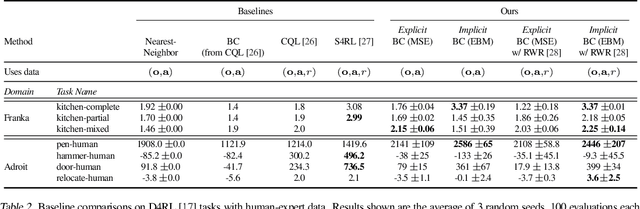
We find that across a wide range of robot policy learning scenarios, treating supervised policy learning with an implicit model generally performs better, on average, than commonly used explicit models. We present extensive experiments on this finding, and we provide both intuitive insight and theoretical arguments distinguishing the properties of implicit models compared to their explicit counterparts, particularly with respect to approximating complex, potentially discontinuous and multi-valued (set-valued) functions. On robotic policy learning tasks we show that implicit behavioral cloning policies with energy-based models (EBM) often outperform common explicit (Mean Square Error, or Mixture Density) behavioral cloning policies, including on tasks with high-dimensional action spaces and visual image inputs. We find these policies provide competitive results or outperform state-of-the-art offline reinforcement learning methods on the challenging human-expert tasks from the D4RL benchmark suite, despite using no reward information. In the real world, robots with implicit policies can learn complex and remarkably subtle behaviors on contact-rich tasks from human demonstrations, including tasks with high combinatorial complexity and tasks requiring 1mm precision.
Forward-Backward Reinforcement Learning
Mar 27, 2018
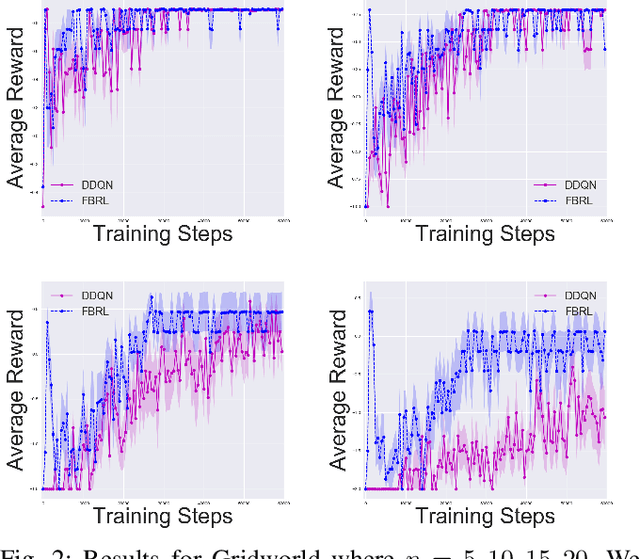
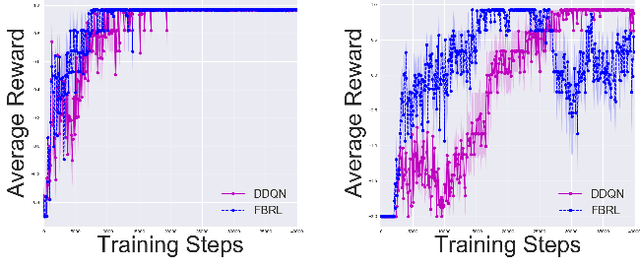
Goals for reinforcement learning problems are typically defined through hand-specified rewards. To design such problems, developers of learning algorithms must inherently be aware of what the task goals are, yet we often require agents to discover them on their own without any supervision beyond these sparse rewards. While much of the power of reinforcement learning derives from the concept that agents can learn with little guidance, this requirement greatly burdens the training process. If we relax this one restriction and endow the agent with knowledge of the reward function, and in particular of the goal, we can leverage backwards induction to accelerate training. To achieve this, we propose training a model to learn to take imagined reversal steps from known goal states. Rather than training an agent exclusively to determine how to reach a goal while moving forwards in time, our approach travels backwards to jointly predict how we got there. We evaluate our work in Gridworld and Towers of Hanoi and empirically demonstrate that it yields better performance than standard DDQN.
Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping
Sep 25, 2017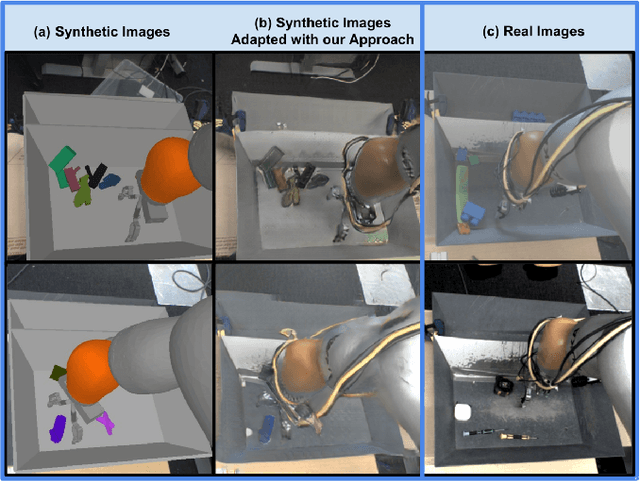


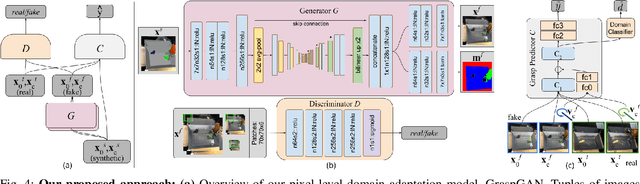
Instrumenting and collecting annotated visual grasping datasets to train modern machine learning algorithms can be extremely time-consuming and expensive. An appealing alternative is to use off-the-shelf simulators to render synthetic data for which ground-truth annotations are generated automatically. Unfortunately, models trained purely on simulated data often fail to generalize to the real world. We study how randomized simulated environments and domain adaptation methods can be extended to train a grasping system to grasp novel objects from raw monocular RGB images. We extensively evaluate our approaches with a total of more than 25,000 physical test grasps, studying a range of simulation conditions and domain adaptation methods, including a novel extension of pixel-level domain adaptation that we term the GraspGAN. We show that, by using synthetic data and domain adaptation, we are able to reduce the number of real-world samples needed to achieve a given level of performance by up to 50 times, using only randomly generated simulated objects. We also show that by using only unlabeled real-world data and our GraspGAN methodology, we obtain real-world grasping performance without any real-world labels that is similar to that achieved with 939,777 labeled real-world samples.