 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocate 3D: Real-World Object Localization via Self-Supervised Learning in 3D
Apr 19, 2025We present LOCATE 3D, a model for localizing objects in 3D scenes from referring expressions like "the small coffee table between the sofa and the lamp." LOCATE 3D sets a new state-of-the-art on standard referential grounding benchmarks and showcases robust generalization capabilities. Notably, LOCATE 3D operates directly on sensor observation streams (posed RGB-D frames), enabling real-world deployment on robots and AR devices. Key to our approach is 3D-JEPA, a novel self-supervised learning (SSL) algorithm applicable to sensor point clouds. It takes as input a 3D pointcloud featurized using 2D foundation models (CLIP, DINO). Subsequently, masked prediction in latent space is employed as a pretext task to aid the self-supervised learning of contextualized pointcloud features. Once trained, the 3D-JEPA encoder is finetuned alongside a language-conditioned decoder to jointly predict 3D masks and bounding boxes. Additionally, we introduce LOCATE 3D DATASET, a new dataset for 3D referential grounding, spanning multiple capture setups with over 130K annotations. This enables a systematic study of generalization capabilities as well as a stronger model.
DexterityGen: Foundation Controller for Unprecedented Dexterity
Feb 06, 2025



Teaching robots dexterous manipulation skills, such as tool use, presents a significant challenge. Current approaches can be broadly categorized into two strategies: human teleoperation (for imitation learning) and sim-to-real reinforcement learning. The first approach is difficult as it is hard for humans to produce safe and dexterous motions on a different embodiment without touch feedback. The second RL-based approach struggles with the domain gap and involves highly task-specific reward engineering on complex tasks. Our key insight is that RL is effective at learning low-level motion primitives, while humans excel at providing coarse motion commands for complex, long-horizon tasks. Therefore, the optimal solution might be a combination of both approaches. In this paper, we introduce DexterityGen (DexGen), which uses RL to pretrain large-scale dexterous motion primitives, such as in-hand rotation or translation. We then leverage this learned dataset to train a dexterous foundational controller. In the real world, we use human teleoperation as a prompt to the controller to produce highly dexterous behavior. We evaluate the effectiveness of DexGen in both simulation and real world, demonstrating that it is a general-purpose controller that can realize input dexterous manipulation commands and significantly improves stability by 10-100x measured as duration of holding objects across diverse tasks. Notably, with DexGen we demonstrate unprecedented dexterous skills including diverse object reorientation and dexterous tool use such as pen, syringe, and screwdriver for the first time.
Sparsh: Self-supervised touch representations for vision-based tactile sensing
Oct 31, 2024In this work, we introduce general purpose touch representations for the increasingly accessible class of vision-based tactile sensors. Such sensors have led to many recent advances in robot manipulation as they markedly complement vision, yet solutions today often rely on task and sensor specific handcrafted perception models. Collecting real data at scale with task centric ground truth labels, like contact forces and slip, is a challenge further compounded by sensors of various form factor differing in aspects like lighting and gel markings. To tackle this we turn to self-supervised learning (SSL) that has demonstrated remarkable performance in computer vision. We present Sparsh, a family of SSL models that can support various vision-based tactile sensors, alleviating the need for custom labels through pre-training on 460k+ tactile images with masking and self-distillation in pixel and latent spaces. We also build TacBench, to facilitate standardized benchmarking across sensors and models, comprising of six tasks ranging from comprehending tactile properties to enabling physical perception and manipulation planning. In evaluations, we find that SSL pre-training for touch representation outperforms task and sensor-specific end-to-end training by 95.1% on average over TacBench, and Sparsh (DINO) and Sparsh (IJEPA) are the most competitive, indicating the merits of learning in latent space for tactile images. Project page: https://sparsh-ssl.github.io/
Neural feels with neural fields: Visuo-tactile perception for in-hand manipulation
Dec 20, 2023To achieve human-level dexterity, robots must infer spatial awareness from multimodal sensing to reason over contact interactions. During in-hand manipulation of novel objects, such spatial awareness involves estimating the object's pose and shape. The status quo for in-hand perception primarily employs vision, and restricts to tracking a priori known objects. Moreover, visual occlusion of objects in-hand is imminent during manipulation, preventing current systems to push beyond tasks without occlusion. We combine vision and touch sensing on a multi-fingered hand to estimate an object's pose and shape during in-hand manipulation. Our method, NeuralFeels, encodes object geometry by learning a neural field online and jointly tracks it by optimizing a pose graph problem. We study multimodal in-hand perception in simulation and the real-world, interacting with different objects via a proprioception-driven policy. Our experiments show final reconstruction F-scores of $81$% and average pose drifts of $4.7\,\text{mm}$, further reduced to $2.3\,\text{mm}$ with known CAD models. Additionally, we observe that under heavy visual occlusion we can achieve up to $94$% improvements in tracking compared to vision-only methods. Our results demonstrate that touch, at the very least, refines and, at the very best, disambiguates visual estimates during in-hand manipulation. We release our evaluation dataset of 70 experiments, FeelSight, as a step towards benchmarking in this domain. Our neural representation driven by multimodal sensing can serve as a perception backbone towards advancing robot dexterity. Videos can be found on our project website https://suddhu.github.io/neural-feels/
Habitat 3.0: A Co-Habitat for Humans, Avatars and Robots
Oct 19, 2023



We present Habitat 3.0: a simulation platform for studying collaborative human-robot tasks in home environments. Habitat 3.0 offers contributions across three dimensions: (1) Accurate humanoid simulation: addressing challenges in modeling complex deformable bodies and diversity in appearance and motion, all while ensuring high simulation speed. (2) Human-in-the-loop infrastructure: enabling real human interaction with simulated robots via mouse/keyboard or a VR interface, facilitating evaluation of robot policies with human input. (3) Collaborative tasks: studying two collaborative tasks, Social Navigation and Social Rearrangement. Social Navigation investigates a robot's ability to locate and follow humanoid avatars in unseen environments, whereas Social Rearrangement addresses collaboration between a humanoid and robot while rearranging a scene. These contributions allow us to study end-to-end learned and heuristic baselines for human-robot collaboration in-depth, as well as evaluate them with humans in the loop. Our experiments demonstrate that learned robot policies lead to efficient task completion when collaborating with unseen humanoid agents and human partners that might exhibit behaviors that the robot has not seen before. Additionally, we observe emergent behaviors during collaborative task execution, such as the robot yielding space when obstructing a humanoid agent, thereby allowing the effective completion of the task by the humanoid agent. Furthermore, our experiments using the human-in-the-loop tool demonstrate that our automated evaluation with humanoids can provide an indication of the relative ordering of different policies when evaluated with real human collaborators. Habitat 3.0 unlocks interesting new features in simulators for Embodied AI, and we hope it paves the way for a new frontier of embodied human-AI interaction capabilities.
What do we learn from a large-scale study of pre-trained visual representations in sim and real environments?
Oct 03, 2023



We present a large empirical investigation on the use of pre-trained visual representations (PVRs) for training downstream policies that execute real-world tasks. Our study spans five different PVRs, two different policy-learning paradigms (imitation and reinforcement learning), and three different robots for 5 distinct manipulation and indoor navigation tasks. From this effort, we can arrive at three insights: 1) the performance trends of PVRs in the simulation are generally indicative of their trends in the real world, 2) the use of PVRs enables a first-of-its-kind result with indoor ImageNav (zero-shot transfer to a held-out scene in the real world), and 3) the benefits from variations in PVRs, primarily data-augmentation and fine-tuning, also transfer to the real-world performance. See project website for additional details and visuals.
Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators
May 05, 2023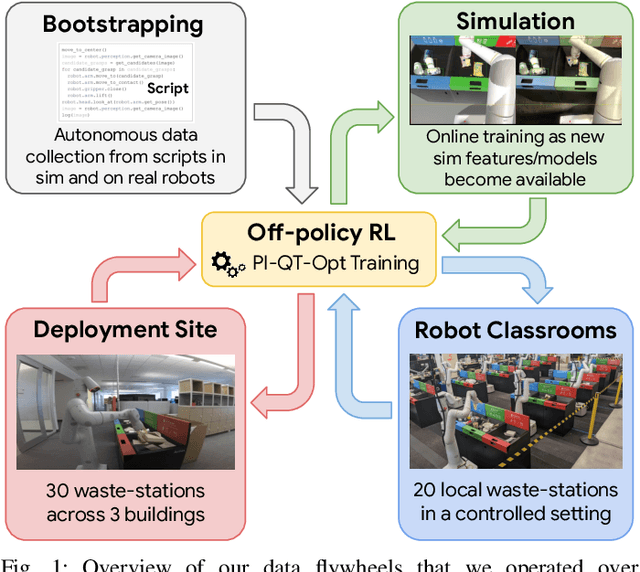


We describe a system for deep reinforcement learning of robotic manipulation skills applied to a large-scale real-world task: sorting recyclables and trash in office buildings. Real-world deployment of deep RL policies requires not only effective training algorithms, but the ability to bootstrap real-world training and enable broad generalization. To this end, our system combines scalable deep RL from real-world data with bootstrapping from training in simulation, and incorporates auxiliary inputs from existing computer vision systems as a way to boost generalization to novel objects, while retaining the benefits of end-to-end training. We analyze the tradeoffs of different design decisions in our system, and present a large-scale empirical validation that includes training on real-world data gathered over the course of 24 months of experimentation, across a fleet of 23 robots in three office buildings, with a total training set of 9527 hours of robotic experience. Our final validation also consists of 4800 evaluation trials across 240 waste station configurations, in order to evaluate in detail the impact of the design decisions in our system, the scaling effects of including more real-world data, and the performance of the method on novel objects. The projects website and videos can be found at \href{http://rl-at-scale.github.io}{rl-at-scale.github.io}.
USA-Net: Unified Semantic and Affordance Representations for Robot Memory
Apr 25, 2023



In order for robots to follow open-ended instructions like "go open the brown cabinet over the sink", they require an understanding of both the scene geometry and the semantics of their environment. Robotic systems often handle these through separate pipelines, sometimes using very different representation spaces, which can be suboptimal when the two objectives conflict. In this work, we present USA-Net, a simple method for constructing a world representation that encodes both the semantics and spatial affordances of a scene in a differentiable map. This allows us to build a gradient-based planner which can navigate to locations in the scene specified using open-ended vocabulary. We use this planner to consistently generate trajectories which are both shorter 5-10% shorter and 10-30% closer to our goal query in CLIP embedding space than paths from comparable grid-based planners which don't leverage gradient information. To our knowledge, this is the first end-to-end differentiable planner optimizes for both semantics and affordance in a single implicit map. Code and visuals are available at our website: https://usa.bolte.cc/
How to Train Your Robot with Deep Reinforcement Learning; Lessons We've Learned
Feb 04, 2021



Deep reinforcement learning (RL) has emerged as a promising approach for autonomously acquiring complex behaviors from low level sensor observations. Although a large portion of deep RL research has focused on applications in video games and simulated control, which does not connect with the constraints of learning in real environments, deep RL has also demonstrated promise in enabling physical robots to learn complex skills in the real world. At the same time,real world robotics provides an appealing domain for evaluating such algorithms, as it connects directly to how humans learn; as an embodied agent in the real world. Learning to perceive and move in the real world presents numerous challenges, some of which are easier to address than others, and some of which are often not considered in RL research that focuses only on simulated domains. In this review article, we present a number of case studies involving robotic deep RL. Building off of these case studies, we discuss commonly perceived challenges in deep RL and how they have been addressed in these works. We also provide an overview of other outstanding challenges, many of which are unique to the real-world robotics setting and are not often the focus of mainstream RL research. Our goal is to provide a resource both for roboticists and machine learning researchers who are interested in furthering the progress of deep RL in the real world.
Action Image Representation: Learning Scalable Deep Grasping Policies with Zero Real World Data
May 13, 2020

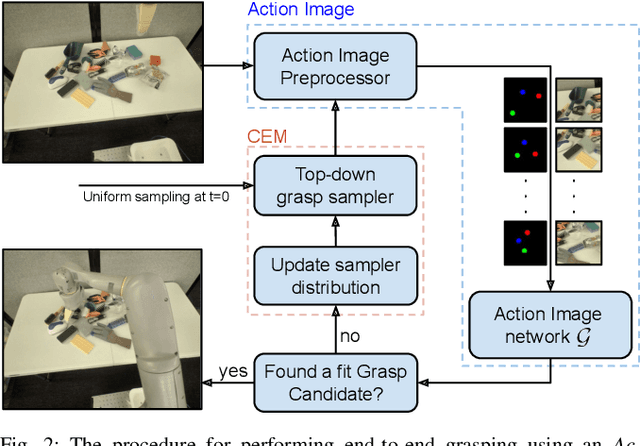
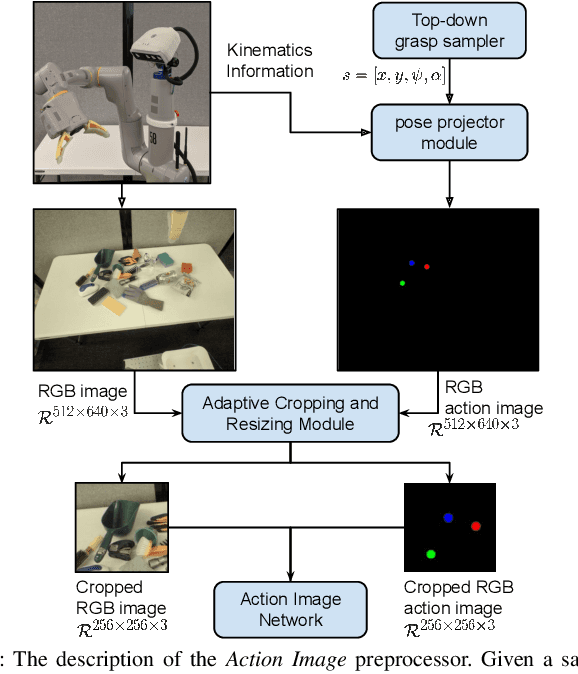
This paper introduces Action Image, a new grasp proposal representation that allows learning an end-to-end deep-grasping policy. Our model achieves $84\%$ grasp success on $172$ real world objects while being trained only in simulation on $48$ objects with just naive domain randomization. Similar to computer vision problems, such as object detection, Action Image builds on the idea that object features are invariant to translation in image space. Therefore, grasp quality is invariant when evaluating the object-gripper relationship; a successful grasp for an object depends on its local context, but is independent of the surrounding environment. Action Image represents a grasp proposal as an image and uses a deep convolutional network to infer grasp quality. We show that by using an Action Image representation, trained networks are able to extract local, salient features of grasping tasks that generalize across different objects and environments. We show that this representation works on a variety of inputs, including color images (RGB), depth images (D), and combined color-depth (RGB-D). Our experimental results demonstrate that networks utilizing an Action Image representation exhibit strong domain transfer between training on simulated data and inference on real-world sensor streams. Finally, our experiments show that a network trained with Action Image improves grasp success ($84\%$ vs. $53\%$) over a baseline model with the same structure, but using actions encoded as vectors.