 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSA-Net: Unified Semantic and Affordance Representations for Robot Memory
Apr 25, 2023



In order for robots to follow open-ended instructions like "go open the brown cabinet over the sink", they require an understanding of both the scene geometry and the semantics of their environment. Robotic systems often handle these through separate pipelines, sometimes using very different representation spaces, which can be suboptimal when the two objectives conflict. In this work, we present USA-Net, a simple method for constructing a world representation that encodes both the semantics and spatial affordances of a scene in a differentiable map. This allows us to build a gradient-based planner which can navigate to locations in the scene specified using open-ended vocabulary. We use this planner to consistently generate trajectories which are both shorter 5-10% shorter and 10-30% closer to our goal query in CLIP embedding space than paths from comparable grid-based planners which don't leverage gradient information. To our knowledge, this is the first end-to-end differentiable planner optimizes for both semantics and affordance in a single implicit map. Code and visuals are available at our website: https://usa.bolte.cc/
HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units
Jun 14, 2021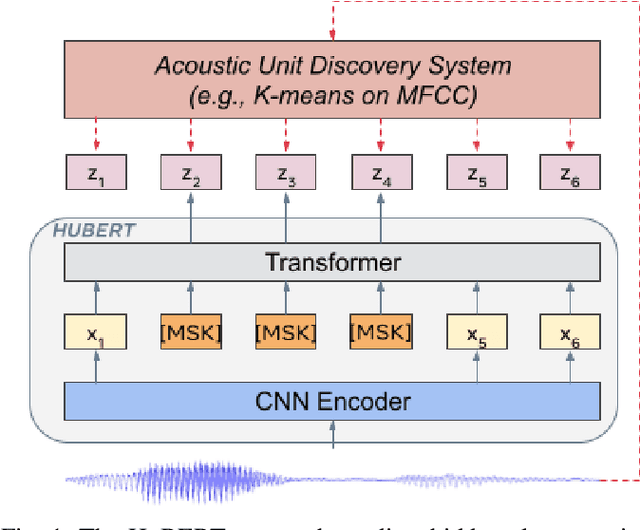
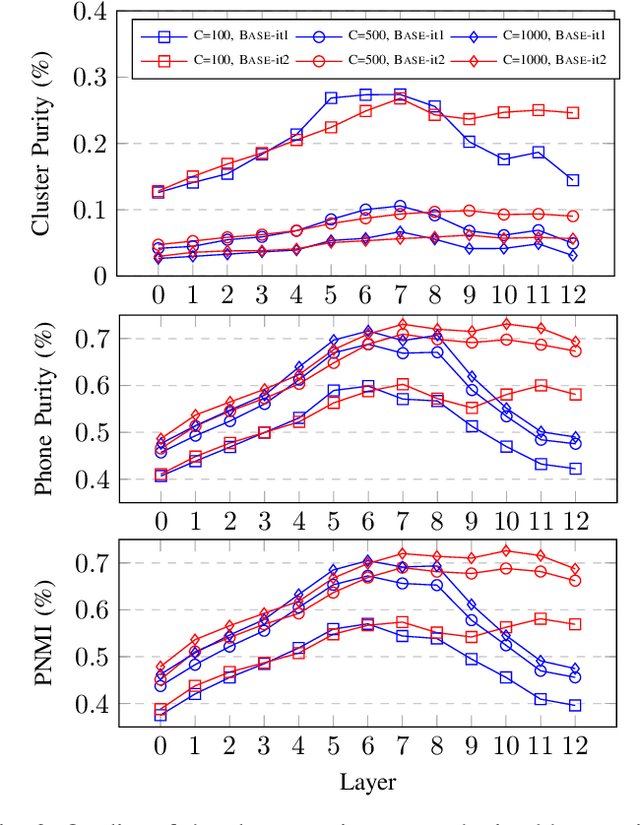
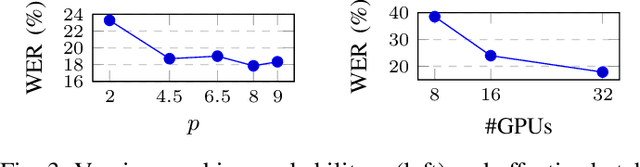
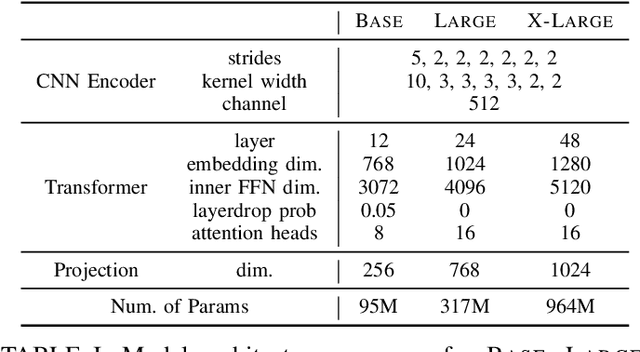
Self-supervised approaches for speech representation learning are challenged by three unique problems: (1) there are multiple sound units in each input utterance, (2) there is no lexicon of input sound units during the pre-training phase, and (3) sound units have variable lengths with no explicit segmentation. To deal with these three problems, we propose the Hidden-Unit BERT (HuBERT) approach for self-supervised speech representation learning, which utilizes an offline clustering step to provide aligned target labels for a BERT-like prediction loss. A key ingredient of our approach is applying the prediction loss over the masked regions only, which forces the model to learn a combined acoustic and language model over the continuous inputs. HuBERT relies primarily on the consistency of the unsupervised clustering step rather than the intrinsic quality of the assigned cluster labels. Starting with a simple k-means teacher of 100 clusters, and using two iterations of clustering, the HuBERT model either matches or improves upon the state-of-the-art wav2vec 2.0 performance on the Librispeech (960h) and Libri-light (60,000h) benchmarks with 10min, 1h, 10h, 100h, and 960h fine-tuning subsets. Using a 1B parameter model, HuBERT shows up to 19% and 13% relative WER reduction on the more challenging dev-other and test-other evaluation subsets.
On the Influence of Masking Policies in Intermediate Pre-training
Apr 18, 2021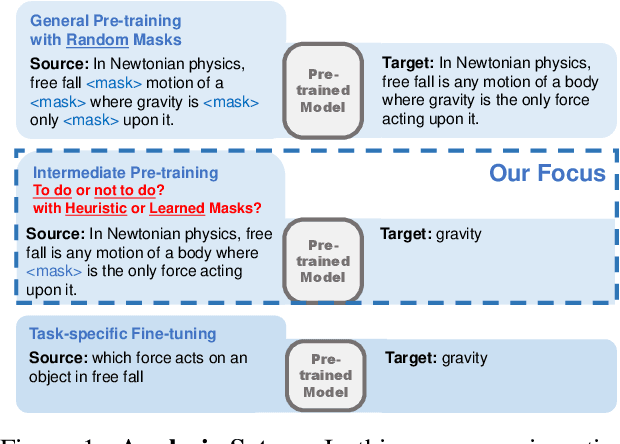
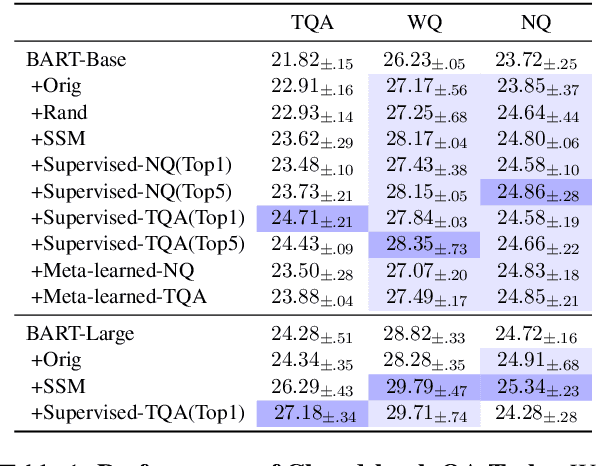
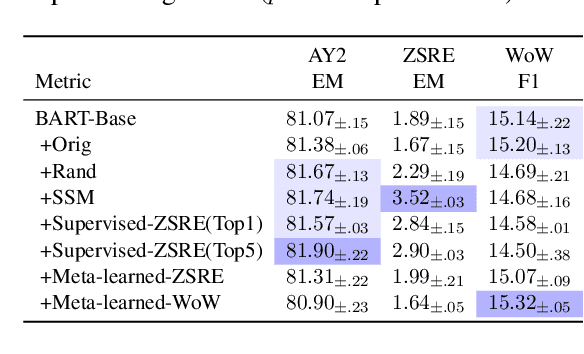
Current NLP models are predominantly trained through a pretrain-then-finetune pipeline, where models are first pretrained on a large text corpus with a masked-language-modelling (MLM) objective, then finetuned on the downstream task. Prior work has shown that inserting an intermediate pre-training phase, with heuristic MLM objectives that resemble downstream tasks, can significantly improve final performance. However, it is still unclear (1) in what cases such intermediate pre-training is helpful, (2) whether hand-crafted heuristic objectives are optimal for a given task, and (3) whether a MLM policy designed for one task is generalizable beyond that task. In this paper, we perform a large-scale empirical study to investigate the effect of various MLM policies in intermediate pre-training. Crucially, we introduce methods to automate discovery of optimal MLM policies, by learning a masking model through either direct supervision or meta-learning on the downstream task. We investigate the effects of using heuristic, directly supervised, and meta-learned MLM policies for intermediate pretraining, on eight selected tasks across three categories (closed-book QA, knowledge-intensive language tasks, and abstractive summarization). Most notably, we show that learned masking policies outperform the heuristic of masking named entities on TriviaQA, and masking policies learned on one task can positively transfer to other tasks in certain cases.
Generative Spoken Language Modeling from Raw Audio
Feb 01, 2021



Generative spoken language modeling involves learning jointly the acoustic and linguistic characteristics of a language from raw audio only (without text or labels). We introduce metrics to automatically evaluate the generated output in terms of acoustic and linguistic quality in two associated end-to-end tasks, respectively: speech resynthesis (repeating the speech input using the system's own voice), and speech generation (producing novel speech outputs conditional on a spoken prompt, or unconditionally), and validate these metrics with human judgment. We test baseline systems consisting of a discrete speech encoder (returning discrete, low bitrate, pseudo-text units), a generative language model (trained on pseudo-text units), and a speech decoder (generating a waveform from pseudo-text). By comparing three state-of-the-art unsupervised speech encoders (Contrastive Predictive Coding (CPC), wav2vec 2.0, HuBERT), and varying the number of discrete units (50, 100, 200), we investigate how the generative performance depends on the quality of the learned units as measured by unsupervised metrics (zero-shot probe tasks). We will open source our evaluation stack and baseline models.
Studying Strategically: Learning to Mask for Closed-book QA
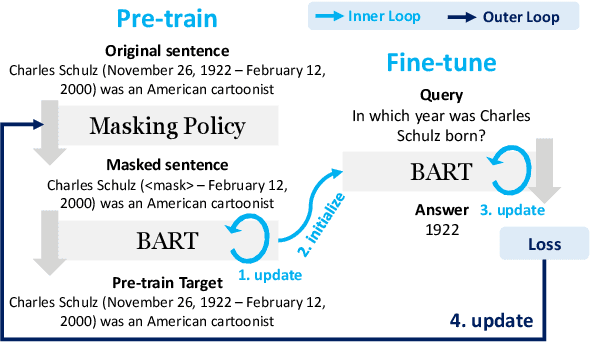
Jan 01, 2021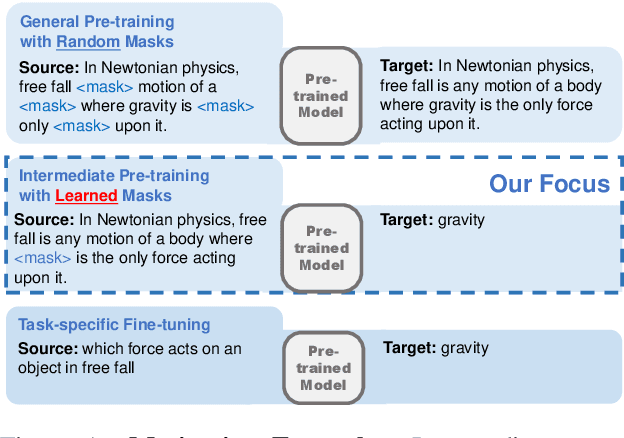
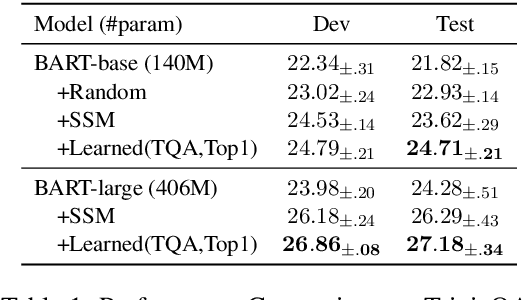
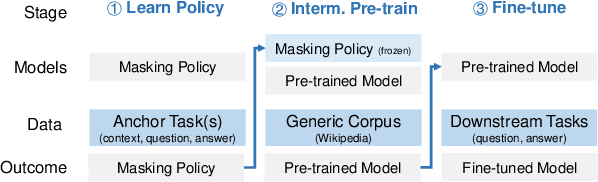

Closed-book question-answering (QA) is a challenging task that requires a model to directly answer questions without access to external knowledge. It has been shown that directly fine-tuning pre-trained language models with (question, answer) examples yields surprisingly competitive performance, which is further improved upon through adding an intermediate pre-training stage between general pre-training and fine-tuning. Prior work used a heuristic during this intermediate stage, whereby named entities and dates are masked, and the model is trained to recover these tokens. In this paper, we aim to learn the optimal masking strategy for the intermediate pre-training stage. We first train our masking policy to extract spans that are likely to be tested, using supervision from the downstream task itself, then deploy the learned policy during intermediate pre-training. Thus, our policy packs task-relevant knowledge into the parameters of a language model. Our approach is particularly effective on TriviaQA, outperforming strong heuristics when used to pre-train BART.