 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic activations
Sep 26, 2025We introduce stochastic activations. This novel strategy randomly selects between several non-linear functions in the feed-forward layer of a large language model. In particular, we choose between SILU or RELU depending on a Bernoulli draw. This strategy circumvents the optimization problem associated with RELU, namely, the constant shape for negative inputs that prevents the gradient flow. We leverage this strategy in two ways: (1) We use stochastic activations during pre-training and fine-tune the model with RELU, which is used at inference time to provide sparse latent vectors. This reduces the inference FLOPs and translates into a significant speedup in the CPU. Interestingly, this leads to much better results than training from scratch with the RELU activation function. (2) We evaluate stochastic activations for generation. This strategy performs reasonably well: it is only slightly inferior to the best deterministic non-linearity, namely SILU combined with temperature scaling. This offers an alternative to existing strategies by providing a controlled way to increase the diversity of the generated text.
SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution
Feb 25, 2025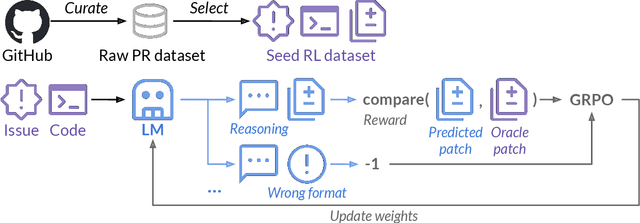


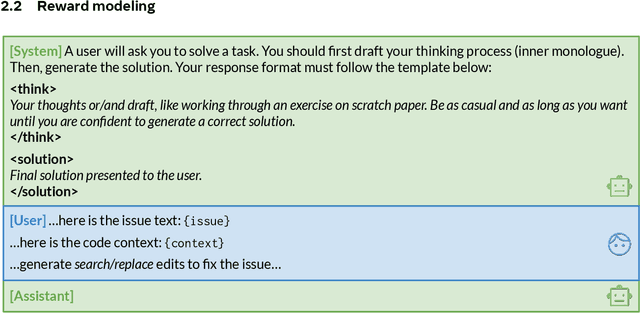
The recent DeepSeek-R1 release has demonstrated the immense potential of reinforcement learning (RL) in enhancing the general reasoning capabilities of large language models (LLMs). While DeepSeek-R1 and other follow-up work primarily focus on applying RL to competitive coding and math problems, this paper introduces SWE-RL, the first approach to scale RL-based LLM reasoning for real-world software engineering. Leveraging a lightweight rule-based reward (e.g., the similarity score between ground-truth and LLM-generated solutions), SWE-RL enables LLMs to autonomously recover a developer's reasoning processes and solutions by learning from extensive open-source software evolution data -- the record of a software's entire lifecycle, including its code snapshots, code changes, and events such as issues and pull requests. Trained on top of Llama 3, our resulting reasoning model, Llama3-SWE-RL-70B, achieves a 41.0% solve rate on SWE-bench Verified -- a human-verified collection of real-world GitHub issues. To our knowledge, this is the best performance reported for medium-sized (<100B) LLMs to date, even comparable to leading proprietary LLMs like GPT-4o. Surprisingly, despite performing RL solely on software evolution data, Llama3-SWE-RL has even emerged with generalized reasoning skills. For example, it shows improved results on five out-of-domain tasks, namely, function coding, library use, code reasoning, mathematics, and general language understanding, whereas a supervised-finetuning baseline even leads to performance degradation on average. Overall, SWE-RL opens up a new direction to improve the reasoning capabilities of LLMs through reinforcement learning on massive software engineering data.
RLEF: Grounding Code LLMs in Execution Feedback with Reinforcement Learning
Oct 02, 2024


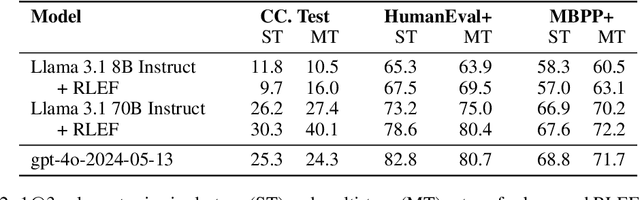
Large language models (LLMs) deployed as agents solve user-specified tasks over multiple steps while keeping the required manual engagement to a minimum. Crucially, such LLMs need to ground their generations in any feedback obtained to reliably achieve desired outcomes. We propose an end-to-end reinforcement learning method for teaching models to leverage execution feedback in the realm of code synthesis, where state-of-the-art LLMs struggle to improve code iteratively compared to independent sampling. We benchmark on competitive programming tasks, where we achieve new start-of-the art results with both small (8B parameters) and large (70B) models while reducing the amount of samples required by an order of magnitude. Our analysis of inference-time behavior demonstrates that our method produces LLMs that effectively leverage automatic feedback over multiple steps.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Audio Conditioning for Music Generation via Discrete Bottleneck Features
Jul 17, 2024



While most music generation models use textual or parametric conditioning (e.g. tempo, harmony, musical genre), we propose to condition a language model based music generation system with audio input. Our exploration involves two distinct strategies. The first strategy, termed textual inversion, leverages a pre-trained text-to-music model to map audio input to corresponding "pseudowords" in the textual embedding space. For the second model we train a music language model from scratch jointly with a text conditioner and a quantized audio feature extractor. At inference time, we can mix textual and audio conditioning and balance them thanks to a novel double classifier free guidance method. We conduct automatic and human studies that validates our approach. We will release the code and we provide music samples on https://musicgenstyle.github.io in order to show the quality of our model.
An Independence-promoting Loss for Music Generation with Language Models
Jun 04, 2024Music generation schemes using language modeling rely on a vocabulary of audio tokens, generally provided as codes in a discrete latent space learnt by an auto-encoder. Multi-stage quantizers are often employed to produce these tokens, therefore the decoding strategy used for token prediction must be adapted to account for multiple codebooks: either it should model the joint distribution over all codebooks, or fit the product of the codebook marginal distributions. Modelling the joint distribution requires a costly increase in the number of auto-regressive steps, while fitting the product of the marginals yields an inexact model unless the codebooks are mutually independent. In this work, we introduce an independence-promoting loss to regularize the auto-encoder used as the tokenizer in language models for music generation. The proposed loss is a proxy for mutual information based on the maximum mean discrepancy principle, applied in reproducible kernel Hilbert spaces. Our criterion is simple to implement and train, and it is generalizable to other multi-stream codecs. We show that it reduces the statistical dependence between codebooks during auto-encoding. This leads to an increase in the generated music quality when modelling the product of the marginal distributions, while generating audio much faster than the joint distribution model.
Masked Audio Generation using a Single Non-Autoregressive Transformer
Jan 09, 2024



We introduce MAGNeT, a masked generative sequence modeling method that operates directly over several streams of audio tokens. Unlike prior work, MAGNeT is comprised of a single-stage, non-autoregressive transformer. During training, we predict spans of masked tokens obtained from a masking scheduler, while during inference we gradually construct the output sequence using several decoding steps. To further enhance the quality of the generated audio, we introduce a novel rescoring method in which, we leverage an external pre-trained model to rescore and rank predictions from MAGNeT, which will be then used for later decoding steps. Lastly, we explore a hybrid version of MAGNeT, in which we fuse between autoregressive and non-autoregressive models to generate the first few seconds in an autoregressive manner while the rest of the sequence is being decoded in parallel. We demonstrate the efficiency of MAGNeT for the task of text-to-music and text-to-audio generation and conduct an extensive empirical evaluation, considering both objective metrics and human studies. The proposed approach is comparable to the evaluated baselines, while being significantly faster (x7 faster than the autoregressive baseline). Through ablation studies and analysis, we shed light on the importance of each of the components comprising MAGNeT, together with pointing to the trade-offs between autoregressive and non-autoregressive modeling, considering latency, throughput, and generation quality. Samples are available on our demo page https://pages.cs.huji.ac.il/adiyoss-lab/MAGNeT.
Generative Spoken Language Model based on continuous word-sized audio tokens
Oct 08, 2023



In NLP, text language models based on words or subwords are known to outperform their character-based counterparts. Yet, in the speech community, the standard input of spoken LMs are 20ms or 40ms-long discrete units (shorter than a phoneme). Taking inspiration from word-based LM, we introduce a Generative Spoken Language Model (GSLM) based on word-size continuous-valued audio embeddings that can generate diverse and expressive language output. This is obtained by replacing lookup table for lexical types with a Lexical Embedding function, the cross entropy loss by a contrastive loss, and multinomial sampling by k-NN sampling. The resulting model is the first generative language model based on word-size continuous embeddings. Its performance is on par with discrete unit GSLMs regarding generation quality as measured by automatic metrics and subjective human judgements. Moreover, it is five times more memory efficient thanks to its large 200ms units. In addition, the embeddings before and after the Lexical Embedder are phonetically and semantically interpretable.
Low-Resource Self-Supervised Learning with SSL-Enhanced TTS
Sep 29, 2023



Self-supervised learning (SSL) techniques have achieved remarkable results in various speech processing tasks. Nonetheless, a significant challenge remains in reducing the reliance on vast amounts of speech data for pre-training. This paper proposes to address this challenge by leveraging synthetic speech to augment a low-resource pre-training corpus. We construct a high-quality text-to-speech (TTS) system with limited resources using SSL features and generate a large synthetic corpus for pre-training. Experimental results demonstrate that our proposed approach effectively reduces the demand for speech data by 90\% with only slight performance degradation. To the best of our knowledge, this is the first work aiming to enhance low-resource self-supervised learning in speech processing.
Code Llama: Open Foundation Models for Code
Aug 25, 2023
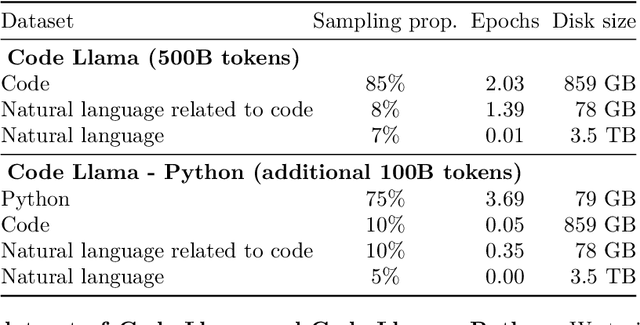
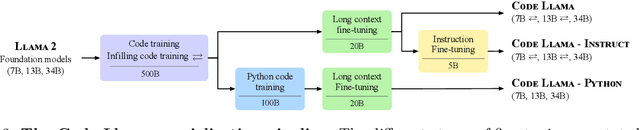
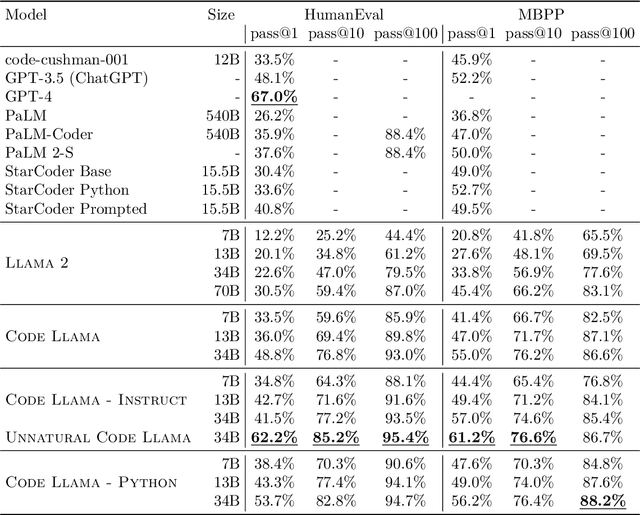
We release Code Llama, a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programming tasks. We provide multiple flavors to cover a wide range of applications: foundation models (Code Llama), Python specializations (Code Llama - Python), and instruction-following models (Code Llama - Instruct) with 7B, 13B and 34B parameters each. All models are trained on sequences of 16k tokens and show improvements on inputs with up to 100k tokens. 7B and 13B Code Llama and Code Llama - Instruct variants support infilling based on surrounding content. Code Llama reaches state-of-the-art performance among open models on several code benchmarks, with scores of up to 53% and 55% on HumanEval and MBPP, respectively. Notably, Code Llama - Python 7B outperforms Llama 2 70B on HumanEval and MBPP, and all our models outperform every other publicly available model on MultiPL-E. We release Code Llama under a permissive license that allows for both research and commercial use.