 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAPTCHA Solving for Native GUI Agents: Automated Reasoning-Action Data Generation and Self-Corrective Training
Mar 23, 2026GUI agents are rapidly shifting from multi-module pipelines to end-to-end, native vision-language models (VLMs) that perceive raw screenshots and directly interact with digital devices. Despite rapid progress on general GUI tasks, CAPTCHA solving remains a major challenge. On the other hand, although specialized CAPTCHA solving pipelines exist, they cannot handle general GUI tasks. To address this gap, we introduce ReCAP: a CAPTCHA-capable native GUI agent that can robustly solve modern, interactive CAPTCHA challenges, while preserving their performance as a general GUI agent. We first develop a dynamic CAPTCHA system spanning seven representative CAPTCHA types, designed to stress primitive and complementary capabilities for CAPTCHA solving (e.g., robust OCR under heavy noise and text stylization, fine-grained visual understanding, and precise control). Then, we develop an automated data collection and curation pipeline that generates large-scale CAPTCHA interaction trajectories paired with reasoning traces. As CAPTCHA solving often requires multi-step interaction and recovery from intermediate mistakes, we further leverage failed trajectories to construct self-correction data, training agents to reflect on errors and correct their actions online. Across held-out test sets, ReCAP improves CAPTCHA-solving success from roughly 30\% to 80\%, while maintaining strong performance on general GUI-agent benchmarks.
SWE-Replay: Efficient Test-Time Scaling for Software Engineering Agents
Jan 29, 2026Test-time scaling has been widely adopted to enhance the capabilities of Large Language Model (LLM) agents in software engineering (SWE) tasks. However, the standard approach of repeatedly sampling trajectories from scratch is computationally expensive. While recent methods have attempted to mitigate costs using specialized value agents, they can suffer from model miscalibration and fail to generalize to modern agents that synthesize custom bash scripts as tools. In this paper, we introduce SWE-Replay, the first efficient and generalizable test-time scaling technique for modern agents without reliance on potentially noisy value estimates. SWE-Replay optimizes the scaling process by recycling trajectories from prior trials, dynamically choosing to either explore from scratch or exploit archived experience by branching at critical intermediate steps. This selection of intermediate steps is driven by the potential and reasoning significance of repository exploration, rather than external LLM-based quality estimates. Our evaluation shows that, on SWE-Bench Verified, SWE-Replay consistently outperforms naive scaling, reducing costs by up to 17.4% while maintaining or even improving performance by up to 3.8%. Further evaluation on SWE-Bench Pro and Multilingual validates the generalizability of SWE-Replay, establishing it as a robust foundation for efficient test-time scaling of software engineering agents.
InfiniteVGGT: Visual Geometry Grounded Transformer for Endless Streams
Jan 05, 2026The grand vision of enabling persistent, large-scale 3D visual geometry understanding is shackled by the irreconcilable demands of scalability and long-term stability. While offline models like VGGT achieve inspiring geometry capability, their batch-based nature renders them irrelevant for live systems. Streaming architectures, though the intended solution for live operation, have proven inadequate. Existing methods either fail to support truly infinite-horizon inputs or suffer from catastrophic drift over long sequences. We shatter this long-standing dilemma with InfiniteVGGT, a causal visual geometry transformer that operationalizes the concept of a rolling memory through a bounded yet adaptive and perpetually expressive KV cache. Capitalizing on this, we devise a training-free, attention-agnostic pruning strategy that intelligently discards obsolete information, effectively ``rolling'' the memory forward with each new frame. Fully compatible with FlashAttention, InfiniteVGGT finally alleviates the compromise, enabling infinite-horizon streaming while outperforming existing streaming methods in long-term stability. The ultimate test for such a system is its performance over a truly infinite horizon, a capability that has been impossible to rigorously validate due to the lack of extremely long-term, continuous benchmarks. To address this critical gap, we introduce the Long3D benchmark, which, for the first time, enables a rigorous evaluation of continuous 3D geometry estimation on sequences about 10,000 frames. This provides the definitive evaluation platform for future research in long-term 3D geometry understanding. Code is available at: https://github.com/AutoLab-SAI-SJTU/InfiniteVGGT
Toward Training Superintelligent Software Agents through Self-Play SWE-RL
Dec 21, 2025While current software agents powered by large language models (LLMs) and agentic reinforcement learning (RL) can boost programmer productivity, their training data (e.g., GitHub issues and pull requests) and environments (e.g., pass-to-pass and fail-to-pass tests) heavily depend on human knowledge or curation, posing a fundamental barrier to superintelligence. In this paper, we present Self-play SWE-RL (SSR), a first step toward training paradigms for superintelligent software agents. Our approach takes minimal data assumptions, only requiring access to sandboxed repositories with source code and installed dependencies, with no need for human-labeled issues or tests. Grounded in these real-world codebases, a single LLM agent is trained via reinforcement learning in a self-play setting to iteratively inject and repair software bugs of increasing complexity, with each bug formally specified by a test patch rather than a natural language issue description. On the SWE-bench Verified and SWE-Bench Pro benchmarks, SSR achieves notable self-improvement (+10.4 and +7.8 points, respectively) and consistently outperforms the human-data baseline over the entire training trajectory, despite being evaluated on natural language issues absent from self-play. Our results, albeit early, suggest a path where agents autonomously gather extensive learning experiences from real-world software repositories, ultimately enabling superintelligent systems that exceed human capabilities in understanding how systems are constructed, solving novel challenges, and autonomously creating new software from scratch.
Live-SWE-agent: Can Software Engineering Agents Self-Evolve on the Fly?
Nov 17, 2025



Large Language Models (LLMs) are reshaping almost all industries, including software engineering. In recent years, a number of LLM agents have been proposed to solve real-world software problems. Such software agents are typically equipped with a suite of coding tools and can autonomously decide the next actions to form complete trajectories to solve end-to-end software tasks. While promising, they typically require dedicated design and may still be suboptimal, since it can be extremely challenging and costly to exhaust the entire agent scaffold design space. Recognizing that software agents are inherently software themselves that can be further refined/modified, researchers have proposed a number of self-improving software agents recently, including the Darwin-Gödel Machine (DGM). Meanwhile, such self-improving agents require costly offline training on specific benchmarks and may not generalize well across different LLMs or benchmarks. In this paper, we propose Live-SWE-agent, the first live software agent that can autonomously and continuously evolve itself on-the-fly during runtime when solving real-world software problems. More specifically, Live-SWE-agent starts with the most basic agent scaffold with only access to bash tools (e.g., mini-SWE-agent), and autonomously evolves its own scaffold implementation while solving real-world software problems. Our evaluation on the widely studied SWE-bench Verified benchmark shows that Live-SWE-agent can achieve an impressive solve rate of 75.4% without test-time scaling, outperforming all existing open-source software agents and approaching the performance of the best proprietary solution. Moreover, Live-SWE-agent outperforms state-of-the-art manually crafted software agents on the recent SWE-Bench Pro benchmark, achieving the best-known solve rate of 45.8%.
SEC-bench: Automated Benchmarking of LLM Agents on Real-World Software Security Tasks
Jun 13, 2025



Rigorous security-focused evaluation of large language model (LLM) agents is imperative for establishing trust in their safe deployment throughout the software development lifecycle. However, existing benchmarks largely rely on synthetic challenges or simplified vulnerability datasets that fail to capture the complexity and ambiguity encountered by security engineers in practice. We introduce SEC-bench, the first fully automated benchmarking framework for evaluating LLM agents on authentic security engineering tasks. SEC-bench employs a novel multi-agent scaffold that automatically constructs code repositories with harnesses, reproduces vulnerabilities in isolated environments, and generates gold patches for reliable evaluation. Our framework automatically creates high-quality software vulnerability datasets with reproducible artifacts at a cost of only $0.87 per instance. Using SEC-bench, we implement two critical software security tasks to rigorously evaluate LLM agents' capabilities: proof-of-concept (PoC) generation and vulnerability patching. A comprehensive evaluation of state-of-the-art LLM code agents reveals significant performance gaps, achieving at most 18.0% success in PoC generation and 34.0% in vulnerability patching on our complete dataset. These results highlight the crucial steps needed toward developing LLM agents that are more practical, intelligent, and autonomous for security engineering.
KNighter: Transforming Static Analysis with LLM-Synthesized Checkers
Mar 12, 2025



Static analysis is a powerful technique for bug detection in critical systems like operating system kernels. However, designing and implementing static analyzers is challenging, time-consuming, and typically limited to predefined bug patterns. While large language models (LLMs) have shown promise for static analysis, directly applying them to scan large codebases remains impractical due to computational constraints and contextual limitations. We present KNighter, the first approach that unlocks practical LLM-based static analysis by automatically synthesizing static analyzers from historical bug patterns. Rather than using LLMs to directly analyze massive codebases, our key insight is leveraging LLMs to generate specialized static analyzers guided by historical patch knowledge. KNighter implements this vision through a multi-stage synthesis pipeline that validates checker correctness against original patches and employs an automated refinement process to iteratively reduce false positives. Our evaluation on the Linux kernel demonstrates that KNighter generates high-precision checkers capable of detecting diverse bug patterns overlooked by existing human-written analyzers. To date, KNighter-synthesized checkers have discovered 70 new bugs/vulnerabilities in the Linux kernel, with 56 confirmed and 41 already fixed. 11 of these findings have been assigned CVE numbers. This work establishes an entirely new paradigm for scalable, reliable, and traceable LLM-based static analysis for real-world systems via checker synthesis.
SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution
Feb 25, 2025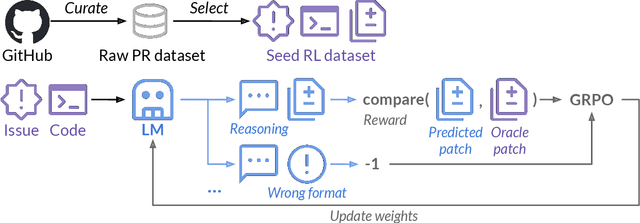


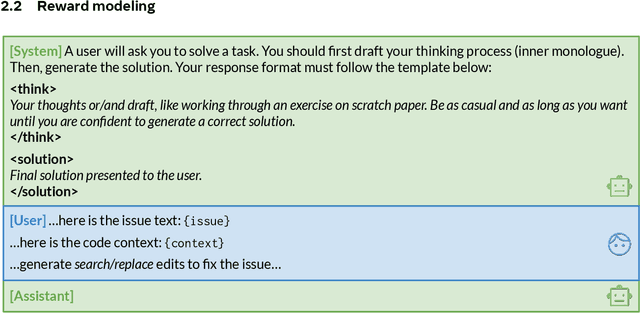
The recent DeepSeek-R1 release has demonstrated the immense potential of reinforcement learning (RL) in enhancing the general reasoning capabilities of large language models (LLMs). While DeepSeek-R1 and other follow-up work primarily focus on applying RL to competitive coding and math problems, this paper introduces SWE-RL, the first approach to scale RL-based LLM reasoning for real-world software engineering. Leveraging a lightweight rule-based reward (e.g., the similarity score between ground-truth and LLM-generated solutions), SWE-RL enables LLMs to autonomously recover a developer's reasoning processes and solutions by learning from extensive open-source software evolution data -- the record of a software's entire lifecycle, including its code snapshots, code changes, and events such as issues and pull requests. Trained on top of Llama 3, our resulting reasoning model, Llama3-SWE-RL-70B, achieves a 41.0% solve rate on SWE-bench Verified -- a human-verified collection of real-world GitHub issues. To our knowledge, this is the best performance reported for medium-sized (<100B) LLMs to date, even comparable to leading proprietary LLMs like GPT-4o. Surprisingly, despite performing RL solely on software evolution data, Llama3-SWE-RL has even emerged with generalized reasoning skills. For example, it shows improved results on five out-of-domain tasks, namely, function coding, library use, code reasoning, mathematics, and general language understanding, whereas a supervised-finetuning baseline even leads to performance degradation on average. Overall, SWE-RL opens up a new direction to improve the reasoning capabilities of LLMs through reinforcement learning on massive software engineering data.
SelfCodeAlign: Self-Alignment for Code Generation
Oct 31, 2024



Instruction tuning is a supervised fine-tuning approach that significantly improves the ability of large language models (LLMs) to follow human instructions. We propose SelfCodeAlign, the first fully transparent and permissive pipeline for self-aligning code LLMs without extensive human annotations or distillation. SelfCodeAlign employs the same base model for inference throughout the data generation process. It first extracts diverse coding concepts from high-quality seed snippets to generate new tasks. It then samples multiple responses per task, pairs each with test cases, and validates them in a sandbox environment. Finally, passing examples are selected for instruction tuning. In our primary experiments, we use SelfCodeAlign with CodeQwen1.5-7B to generate a dataset of 74k instruction-response pairs. Finetuning on this dataset leads to a model that achieves a 67.1 pass@1 on HumanEval+, surpassing CodeLlama-70B-Instruct despite being ten times smaller. Across all benchmarks, this finetuned model consistently outperforms the original version trained with OctoPack, the previous state-of-the-art method for instruction tuning without human annotations or distillation. Additionally, we show that SelfCodeAlign is effective across LLMs of various sizes, from 3B to 33B, and that the base models can benefit more from alignment with their own data distribution. We further validate each component's effectiveness in our pipeline, showing that SelfCodeAlign outperforms both direct distillation from GPT-4o and leading GPT-3.5-based distillation methods, such as OSS-Instruct and Evol-Instruct. SelfCodeAlign has also led to the creation of StarCoder2-Instruct, the first fully transparent, permissively licensed, and self-aligned code LLM that achieves state-of-the-art coding performance.
Large Language Model-Based Agents for Software Engineering: A Survey
Sep 04, 2024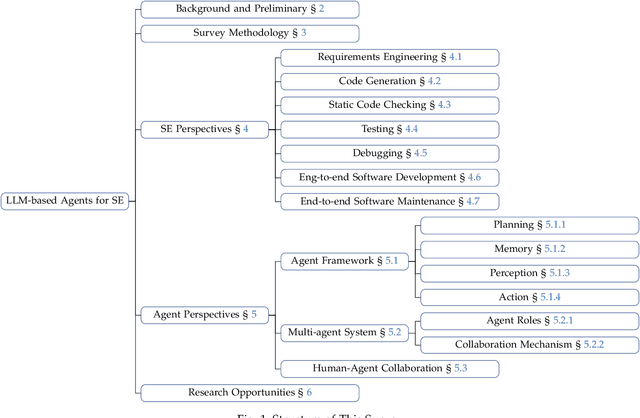



The recent advance in Large Language Models (LLMs) has shaped a new paradigm of AI agents, i.e., LLM-based agents. Compared to standalone LLMs, LLM-based agents substantially extend the versatility and expertise of LLMs by enhancing LLMs with the capabilities of perceiving and utilizing external resources and tools. To date, LLM-based agents have been applied and shown remarkable effectiveness in Software Engineering (SE). The synergy between multiple agents and human interaction brings further promise in tackling complex real-world SE problems. In this work, we present a comprehensive and systematic survey on LLM-based agents for SE. We collect 106 papers and categorize them from two perspectives, i.e., the SE and agent perspectives. In addition, we discuss open challenges and future directions in this critical domain. The repository of this survey is at https://github.com/FudanSELab/Agent4SE-Paper-List.