 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Pass Rate Tell the Whole Story? Evaluating Design Constraint Compliance in LLM-based Issue Resolution
Apr 07, 2026Repository-level issue resolution benchmarks have become a standard testbed for evaluating LLM-based agents, yet success is still predominantly measured by test pass rates. In practice, however, acceptable patches must also comply with project-specific design constraints, such as architectural conventions, error-handling policies, and maintainability requirements, which are rarely encoded in tests and are often documented only implicitly in code review discussions. This paper introduces \textit{design-aware issue resolution} and presents \bench{}, a benchmark that makes such implicit design constraints explicit and measurable. \bench{} is constructed by mining and validating design constraints from real-world pull requests, linking them to issue instances, and automatically checking patch compliance using an LLM-based verifier, yielding 495 issues and 1,787 validated constraints across six repositories, aligned with SWE-bench-Verified and SWE-bench-Pro. Experiments with state-of-the-art agents show that test-based correctness substantially overestimates patch quality: fewer than half of resolved issues are fully design-satisfying, design violations are widespread, and functional correctness exhibits negligible statistical association with design satisfaction. While providing issue-specific design guidance reduces violations, substantial non-compliance remains, highlighting a fundamental gap in current agent capabilities and motivating design-aware evaluation beyond functional correctness.
PulseMind: A Multi-Modal Medical Model for Real-World Clinical Diagnosis
Jan 12, 2026Recent advances in medical multi-modal models focus on specialized image analysis like dermatology, pathology, or radiology. However, they do not fully capture the complexity of real-world clinical diagnostics, which involve heterogeneous inputs and require ongoing contextual understanding during patient-physician interactions. To bridge this gap, we introduce PulseMind, a new family of multi-modal diagnostic models that integrates a systematically curated dataset, a comprehensive evaluation benchmark, and a tailored training framework. Specifically, we first construct a diagnostic dataset, MediScope, which comprises 98,000 real-world multi-turn consultations and 601,500 medical images, spanning over 10 major clinical departments and more than 200 sub-specialties. Then, to better reflect the requirements of real-world clinical diagnosis, we develop the PulseMind Benchmark, a multi-turn diagnostic consultation benchmark with a four-dimensional evaluation protocol comprising proactiveness, accuracy, usefulness, and language quality. Finally, we design a training framework tailored for multi-modal clinical diagnostics, centered around a core component named Comparison-based Reinforcement Policy Optimization (CRPO). Compared to absolute score rewards, CRPO uses relative preference signals from multi-dimensional com-parisons to provide stable and human-aligned training guidance. Extensive experiments demonstrate that PulseMind achieves competitive performance on both the diagnostic consultation benchmark and public medical benchmarks.
MedDialogRubrics: A Comprehensive Benchmark and Evaluation Framework for Multi-turn Medical Consultations in Large Language Models
Jan 07, 2026Medical conversational AI (AI) plays a pivotal role in the development of safer and more effective medical dialogue systems. However, existing benchmarks and evaluation frameworks for assessing the information-gathering and diagnostic reasoning abilities of medical large language models (LLMs) have not been rigorously evaluated. To address these gaps, we present MedDialogRubrics, a novel benchmark comprising 5,200 synthetically constructed patient cases and over 60,000 fine-grained evaluation rubrics generated by LLMs and subsequently refined by clinical experts, specifically designed to assess the multi-turn diagnostic capabilities of LLM. Our framework employs a multi-agent system to synthesize realistic patient records and chief complaints from underlying disease knowledge without accessing real-world electronic health records, thereby mitigating privacy and data-governance concerns. We design a robust Patient Agent that is limited to a set of atomic medical facts and augmented with a dynamic guidance mechanism that continuously detects and corrects hallucinations throughout the dialogue, ensuring internal coherence and clinical plausibility of the simulated cases. Furthermore, we propose a structured LLM-based and expert-annotated rubric-generation pipeline that retrieves Evidence-Based Medicine (EBM) guidelines and utilizes the reject sampling to derive a prioritized set of rubric items ("must-ask" items) for each case. We perform a comprehensive evaluation of state-of-the-art models and demonstrate that, across multiple assessment dimensions, current models face substantial challenges. Our results indicate that improving medical dialogue will require advances in dialogue management architectures, not just incremental tuning of the base-model.
Multi-Agent Deep Research: Training Multi-Agent Systems with M-GRPO
Nov 18, 2025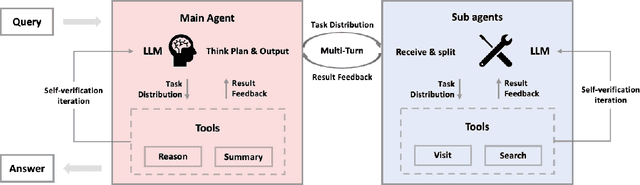
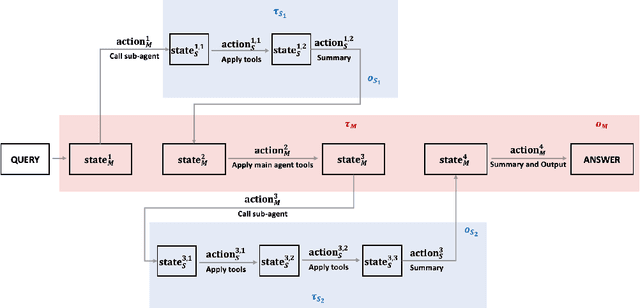
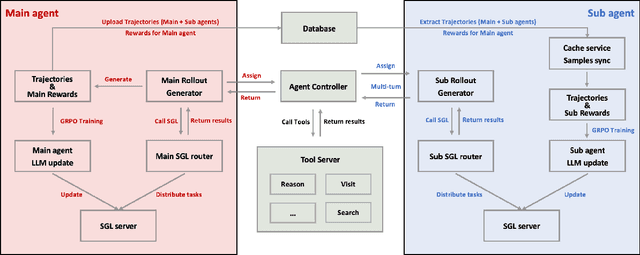
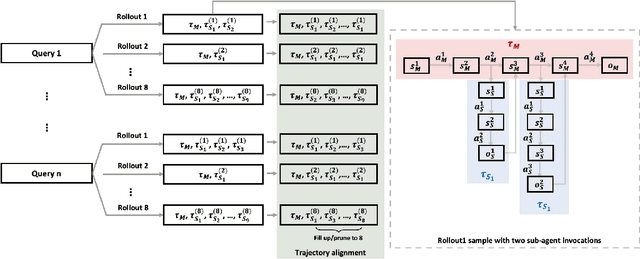
Multi-agent systems perform well on general reasoning tasks. However, the lack of training in specialized areas hinders their accuracy. Current training methods train a unified large language model (LLM) for all agents in the system. This may limit the performances due to different distributions underlying for different agents. Therefore, training multi-agent systems with distinct LLMs should be the next step to solve. However, this approach introduces optimization challenges. For example, agents operate at different frequencies, rollouts involve varying sub-agent invocations, and agents are often deployed across separate servers, disrupting end-to-end gradient flow. To address these issues, we propose M-GRPO, a hierarchical extension of Group Relative Policy Optimization designed for vertical Multi-agent systems with a main agent (planner) and multiple sub-agents (multi-turn tool executors). M-GRPO computes group-relative advantages for both main and sub-agents, maintaining hierarchical credit assignment. It also introduces a trajectory-alignment scheme that generates fixed-size batches despite variable sub-agent invocations. We deploy a decoupled training pipeline in which agents run on separate servers and exchange minimal statistics via a shared store. This enables scalable training without cross-server backpropagation. In experiments on real-world benchmarks (e.g., GAIA, XBench-DeepSearch, and WebWalkerQA), M-GRPO consistently outperforms both single-agent GRPO and multi-agent GRPO with frozen sub-agents, demonstrating improved stability and sample efficiency. These results show that aligning heterogeneous trajectories and decoupling optimization across specialized agents enhances tool-augmented reasoning tasks.
Can Agents Fix Agent Issues?
May 27, 2025LLM-based agent systems are emerging as a new software paradigm and have been widely adopted across diverse domains such as medicine, robotics, and programming. However, maintaining these systems requires substantial effort, as they are inevitably prone to bugs and continually evolve to meet changing external requirements. Therefore, automatically resolving agent issues (i.e., bug reports or feature requests) is a crucial and challenging task. While recent software engineering (SE) agents (e.g., SWE-agent) have shown promise in addressing issues in traditional software systems, it remains unclear how effectively they can resolve real-world issues in agent systems, which differ significantly from traditional software. To fill this gap, we first manually analyze 201 real-world agent issues and identify common categories of agent issues. We then spend 500 person-hours constructing AGENTISSUE-BENCH, a reproducible benchmark comprising 50 agent issue resolution tasks (each with an executable environment and failure-triggering tests). We further evaluate state-of-the-art SE agents on AGENTISSUE-BENCH and reveal their limited effectiveness (i.e., with only 3.33% - 12.67% resolution rates). These results underscore the unique challenges of maintaining agent systems compared to traditional software, highlighting the need for further research to develop advanced SE agents for resolving agent issues. Data and code are available at https://alfin06.github.io/AgentIssue-Bench-Leaderboard/#/ .
Effective Field Neural Network
Feb 24, 2025In recent years, with the rapid development of machine learning, physicists have been exploring its new applications in solving or alleviating the curse of dimensionality in many-body problems. In order to accurately reflect the underlying physics of the problem, domain knowledge must be encoded into the machine learning algorithms. In this work, inspired by field theory, we propose a new set of machine learning models called effective field neural networks (EFNNs) that can automatically and efficiently capture important many-body interactions through multiple self-refining processes. Taking the classical $3$-spin infinite-range model and the quantum double exchange model as case studies, we explicitly demonstrate that EFNNs significantly outperform fully-connected deep neural networks (DNNs) and the effective model. Furthermore, with the help of convolution operations, the EFNNs learned in a small system can be seamlessly used in a larger system without additional training and the relative errors even decrease, which further demonstrates the efficacy of EFNNs in representing core physical behaviors.
Global Estimation of Building-Integrated Facade and Rooftop Photovoltaic Potential by Integrating 3D Building Footprint and Spatio-Temporal Datasets
Dec 02, 2024This research tackles the challenges of estimating Building-Integrated Photovoltaics (BIPV) potential across various temporal and spatial scales, accounting for different geographical climates and urban morphology. We introduce a holistic methodology for evaluating BIPV potential, integrating 3D building footprint models with diverse meteorological data sources to account for dynamic shadow effects. The approach enables the assessment of PV potential on facades and rooftops at different levels-individual buildings, urban blocks, and cities globally. Through an analysis of 120 typical cities, we highlight the importance of 3D building forms, cityscape morphology, and geographic positioning in measuring BIPV potential at various levels. In particular, our simulation study reveals that among cities with optimal facade PV performance, the average ratio of facade PV potential to rooftop PV potential is approximately 68.2%. Additionally, approximately 17.5% of the analyzed samples demonstrate even higher facade PV potentials compared to rooftop installations. This finding underscores the strategic value of incorporating facade PV applications into urban sustainable energy systems.
Large Language Model-Based Agents for Software Engineering: A Survey
Sep 04, 2024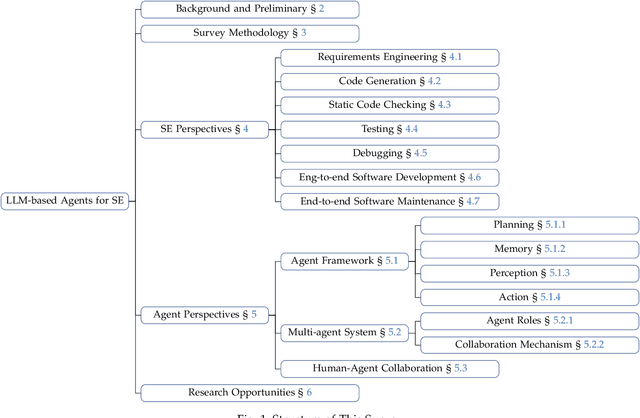



The recent advance in Large Language Models (LLMs) has shaped a new paradigm of AI agents, i.e., LLM-based agents. Compared to standalone LLMs, LLM-based agents substantially extend the versatility and expertise of LLMs by enhancing LLMs with the capabilities of perceiving and utilizing external resources and tools. To date, LLM-based agents have been applied and shown remarkable effectiveness in Software Engineering (SE). The synergy between multiple agents and human interaction brings further promise in tackling complex real-world SE problems. In this work, we present a comprehensive and systematic survey on LLM-based agents for SE. We collect 106 papers and categorize them from two perspectives, i.e., the SE and agent perspectives. In addition, we discuss open challenges and future directions in this critical domain. The repository of this survey is at https://github.com/FudanSELab/Agent4SE-Paper-List.
A Refer-and-Ground Multimodal Large Language Model for Biomedicine
Jun 26, 2024With the rapid development of multimodal large language models (MLLMs), especially their capabilities in visual chat through refer and ground functionalities, their significance is increasingly recognized. However, the biomedical field currently exhibits a substantial gap in this area, primarily due to the absence of a dedicated refer and ground dataset for biomedical images. To address this challenge, we devised the Med-GRIT-270k dataset. It comprises 270k question-and-answer pairs and spans eight distinct medical imaging modalities. Most importantly, it is the first dedicated to the biomedical domain and integrating refer and ground conversations. The key idea is to sample large-scale biomedical image-mask pairs from medical segmentation datasets and generate instruction datasets from text using chatGPT. Additionally, we introduce a Refer-and-Ground Multimodal Large Language Model for Biomedicine (BiRD) by using this dataset and multi-task instruction learning. Extensive experiments have corroborated the efficacy of the Med-GRIT-270k dataset and the multi-modal, fine-grained interactive capabilities of the BiRD model. This holds significant reference value for the exploration and development of intelligent biomedical assistants.
ClassEval: A Manually-Crafted Benchmark for Evaluating LLMs on Class-level Code Generation
Aug 14, 2023



In this work, we make the first attempt to evaluate LLMs in a more challenging code generation scenario, i.e. class-level code generation. We first manually construct the first class-level code generation benchmark ClassEval of 100 class-level Python code generation tasks with approximately 500 person-hours. Based on it, we then perform the first study of 11 state-of-the-art LLMs on class-level code generation. Based on our results, we have the following main findings. First, we find that all existing LLMs show much worse performance on class-level code generation compared to on standalone method-level code generation benchmarks like HumanEval; and the method-level coding ability cannot equivalently reflect the class-level coding ability among LLMs. Second, we find that GPT-4 and GPT-3.5 still exhibit dominate superior than other LLMs on class-level code generation, and the second-tier models includes Instruct-Starcoder, Instruct-Codegen, and Wizardcoder with very similar performance. Third, we find that generating the entire class all at once (i.e. holistic generation strategy) is the best generation strategy only for GPT-4 and GPT-3.5, while method-by-method generation (i.e. incremental and compositional) is better strategies for the other models with limited ability of understanding long instructions and utilizing the middle information. Lastly, we find the limited model ability of generating method-dependent code and discuss the frequent error types in generated classes. Our benchmark is available at https://github.com/FudanSELab/ClassEval.