 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFCMBench: A Comprehensive Financial Credit Multimodal Benchmark for Real-world Applications
Jan 06, 2026As multimodal AI becomes widely used for credit risk assessment and document review, a domain-specific benchmark is urgently needed that (1) reflects documents and workflows specific to financial credit applications, (2) includes credit-specific understanding and real-world robustness, and (3) preserves privacy compliance without sacrificing practical utility. Here, we introduce FCMBench-V1.0 -- a large-scale financial credit multimodal benchmark for real-world applications, covering 18 core certificate types, with 4,043 privacy-compliant images and 8,446 QA samples. The FCMBench evaluation framework consists of three dimensions: Perception, Reasoning, and Robustness, including 3 foundational perception tasks, 4 credit-specific reasoning tasks that require decision-oriented understanding of visual evidence, and 10 real-world acquisition artifact types for robustness stress testing. To reconcile compliance with realism, we construct all samples via a closed synthesis-capture pipeline: we manually synthesize document templates with virtual content and capture scenario-aware images in-house. This design also mitigates pre-training data leakage by avoiding web-sourced or publicly released images. FCMBench can effectively discriminate performance disparities and robustness across modern vision-language models. Extensive experiments were conducted on 23 state-of-the-art vision-language models (VLMs) from 14 top AI companies and research institutes. Among them, Gemini 3 Pro achieves the best F1(\%) score as a commercial model (64.61), Qwen3-VL-235B achieves the best score as an open-source baseline (57.27), and our financial credit-specific model, Qfin-VL-Instruct, achieves the top overall score (64.92). Robustness evaluations show that even top-performing models suffer noticeable performance drops under acquisition artifacts.
SeATrans: Learning Segmentation-Assisted diagnosis model via Transformer
Jun 22, 2022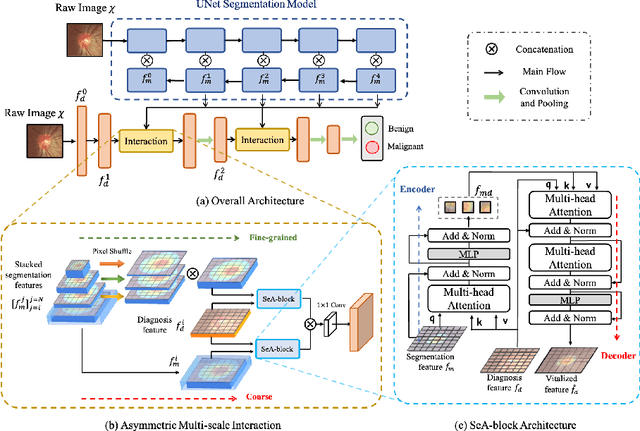
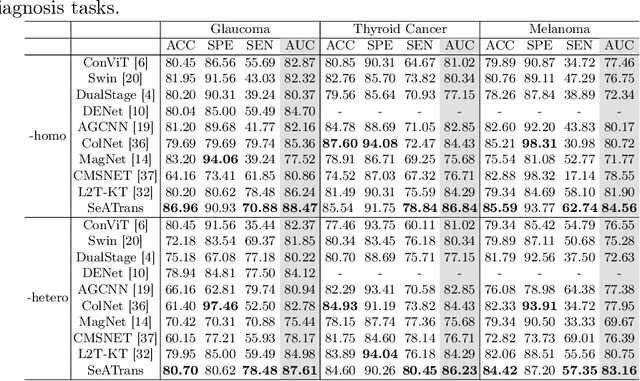
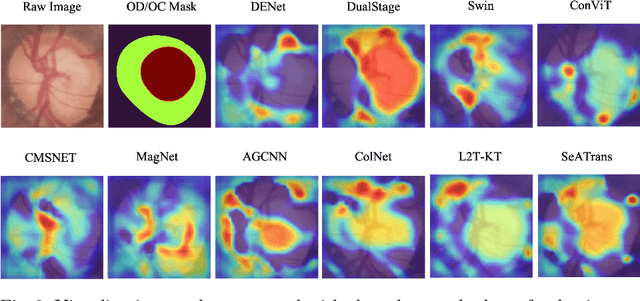
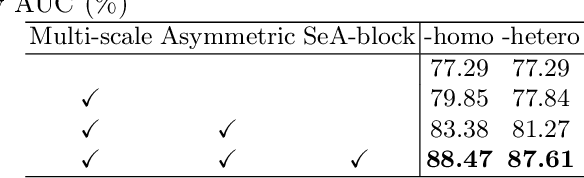
Clinically, the accurate annotation of lesions/tissues can significantly facilitate the disease diagnosis. For example, the segmentation of optic disc/cup (OD/OC) on fundus image would facilitate the glaucoma diagnosis, the segmentation of skin lesions on dermoscopic images is helpful to the melanoma diagnosis, etc. With the advancement of deep learning techniques, a wide range of methods proved the lesions/tissues segmentation can also facilitate the automated disease diagnosis models. However, existing methods are limited in the sense that they can only capture static regional correlations in the images. Inspired by the global and dynamic nature of Vision Transformer, in this paper, we propose Segmentation-Assisted diagnosis Transformer (SeATrans) to transfer the segmentation knowledge to the disease diagnosis network. Specifically, we first propose an asymmetric multi-scale interaction strategy to correlate each single low-level diagnosis feature with multi-scale segmentation features. Then, an effective strategy called SeA-block is adopted to vitalize diagnosis feature via correlated segmentation features. To model the segmentation-diagnosis interaction, SeA-block first embeds the diagnosis feature based on the segmentation information via the encoder, and then transfers the embedding back to the diagnosis feature space by a decoder. Experimental results demonstrate that SeATrans surpasses a wide range of state-of-the-art (SOTA) segmentation-assisted diagnosis methods on several disease diagnosis tasks.
Learning self-calibrated optic disc and cup segmentation from multi-rater annotations
Jun 14, 2022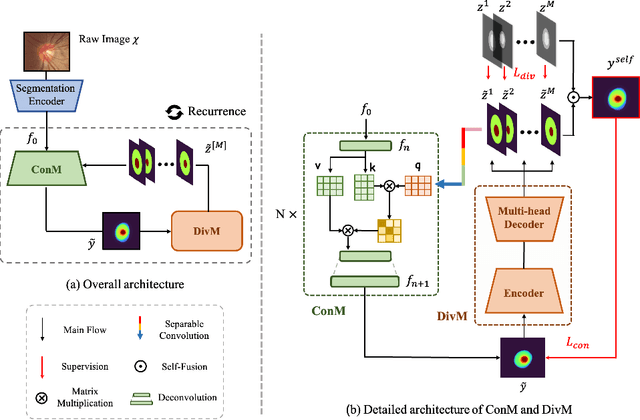
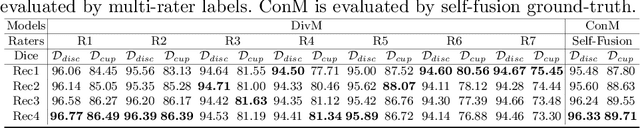
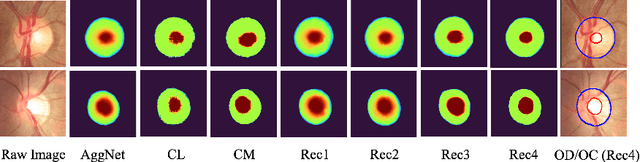
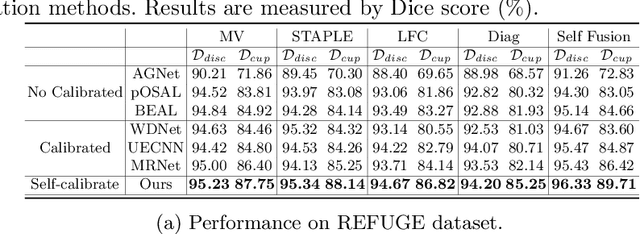
The segmentation of optic disc(OD) and optic cup(OC) from fundus images is an important fundamental task for glaucoma diagnosis. In the clinical practice, it is often necessary to collect opinions from multiple experts to obtain the final OD/OC annotation. This clinical routine helps to mitigate the individual bias. But when data is multiply annotated, standard deep learning models will be inapplicable. In this paper, we propose a novel neural network framework to learn OD/OC segmentation from multi-rater annotations. The segmentation results are self-calibrated through the iterative optimization of multi-rater expertness estimation and calibrated OD/OC segmentation. In this way, the proposed method can realize a mutual improvement of both tasks and finally obtain a refined segmentation result. Specifically, we propose Diverging Model(DivM) and Converging Model(ConM) to process the two tasks respectively. ConM segments the raw image based on the multi-rater expertness map provided by DivM. DivM generates multi-rater expertness map from the segmentation mask provided by ConM. The experiment results show that by recurrently running ConM and DivM, the results can be self-calibrated so as to outperform a range of state-of-the-art(SOTA) multi-rater segmentation methods.
One Hyper-Initializer for All Network Architectures in Medical Image Analysis
Jun 08, 2022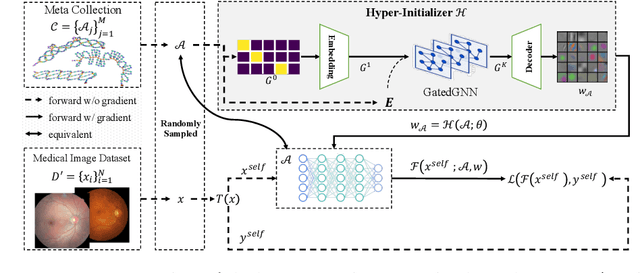
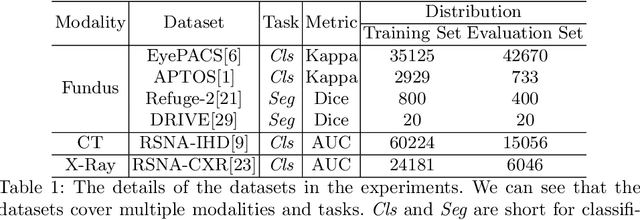
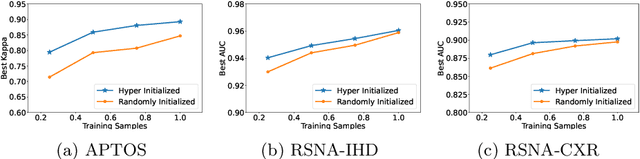
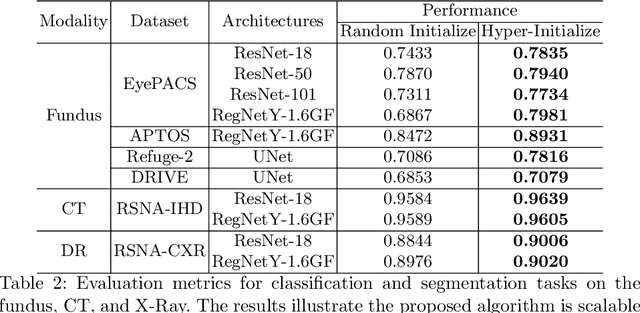
Pre-training is essential to deep learning model performance, especially in medical image analysis tasks where limited training data are available. However, existing pre-training methods are inflexible as the pre-trained weights of one model cannot be reused by other network architectures. In this paper, we propose an architecture-irrelevant hyper-initializer, which can initialize any given network architecture well after being pre-trained for only once. The proposed initializer is a hypernetwork which takes a downstream architecture as input graphs and outputs the initialization parameters of the respective architecture. We show the effectiveness and efficiency of the hyper-initializer through extensive experimental results on multiple medical imaging modalities, especially in data-limited fields. Moreover, we prove that the proposed algorithm can be reused as a favorable plug-and-play initializer for any downstream architecture and task (both classification and segmentation) of the same modality.
Contrastive Centroid Supervision Alleviates Domain Shift in Medical Image Classification
May 31, 2022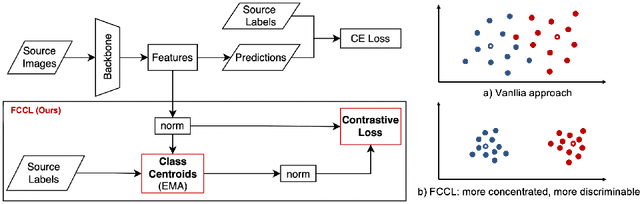


Deep learning based medical imaging classification models usually suffer from the domain shift problem, where the classification performance drops when training data and real-world data differ in imaging equipment manufacturer, image acquisition protocol, patient populations, etc. We propose Feature Centroid Contrast Learning (FCCL), which can improve target domain classification performance by extra supervision during training with contrastive loss between instance and class centroid. Compared with current unsupervised domain adaptation and domain generalization methods, FCCL performs better while only requires labeled image data from a single source domain and no target domain. We verify through extensive experiments that FCCL can achieve superior performance on at least three imaging modalities, i.e. fundus photographs, dermatoscopic images, and H & E tissue images.
Opinions Vary? Diagnosis First!
Feb 14, 2022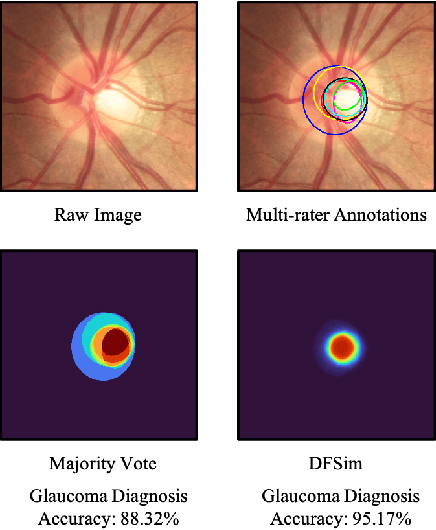
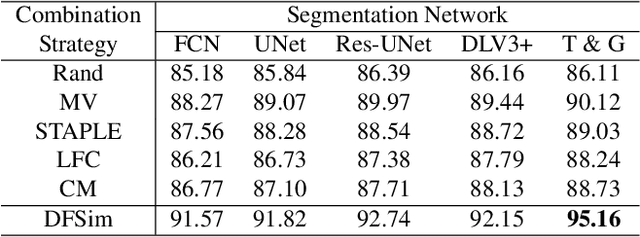
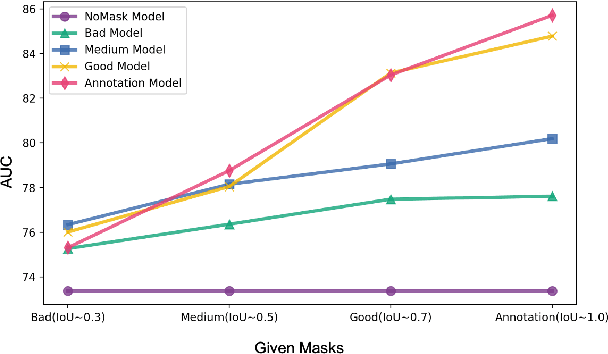
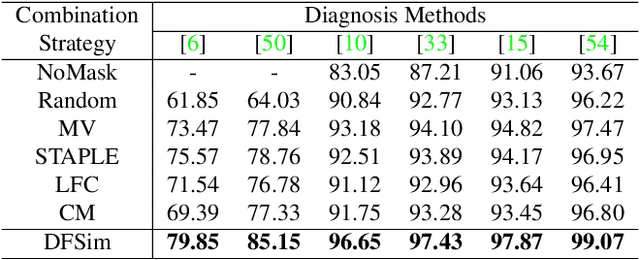
In medical image segmentation, images are usually annotated by several different clinical experts. This clinical routine helps to mitigate the personal bias. However, Computer Vision models often assume there has a unique ground-truth for each of the instance. This research gap between Computer Vision and medical routine is commonly existed but less explored by the current research.In this paper, we try to answer the following two questions: 1. How to learn an optimal combination of the multiple segmentation labels? and 2. How to estimate this segmentation mask from the raw image? We note that in clinical practice, the image segmentation mask usually exists as an auxiliary information for disease diagnosis. Adhering to this mindset, we propose a framework taking the diagnosis result as the gold standard, to estimate the segmentation mask upon the multi-rater segmentation labels, named DiFF (Diagnosis First segmentation Framework).DiFF is implemented by two novelty techniques. First, DFSim (Diagnosis First Simulation of gold label) is learned as an optimal combination of multi-rater segmentation labels for the disease diagnosis. Then, toward estimating DFSim mask from the raw image, we further propose T\&G Module (Take and Give Module) to instill the diagnosis knowledge into the segmentation network. The experiments show that compared with commonly used majority vote, the proposed DiFF is able to segment the masks with 6% improvement on diagnosis AUC score, which also outperforms various state-of-the-art multi-rater methods by a large margin.
Progressive Hard-case Mining across Pyramid Levels in Object Detection
Sep 15, 2021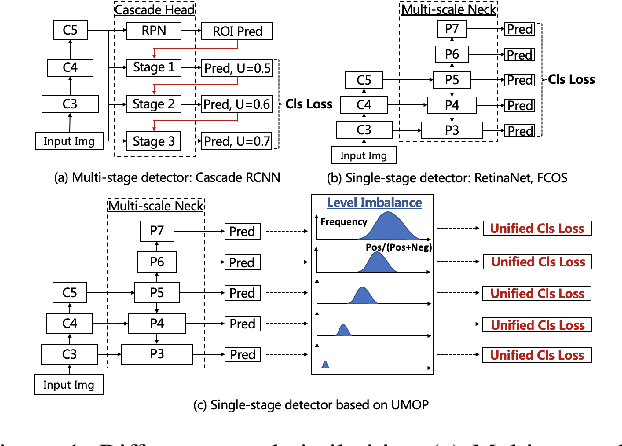
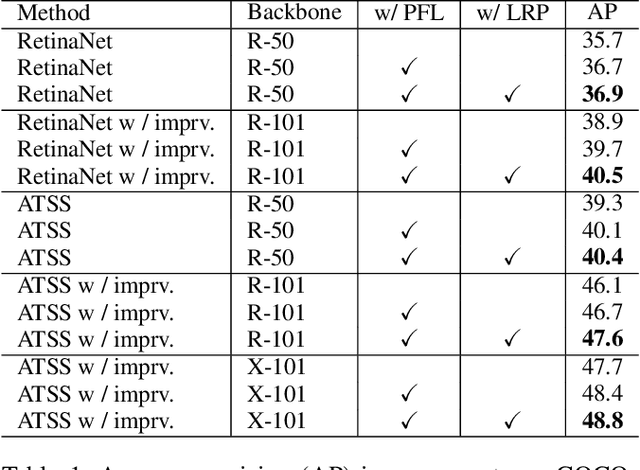
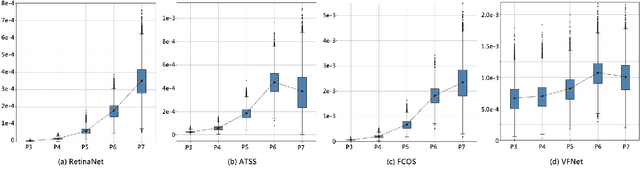

In object detection, multi-level prediction (e.g., FPN, YOLO) and resampling skills (e.g., focal loss, ATSS) have drastically improved one-stage detector performance. However, how to improve the performance by optimizing the feature pyramid level-by-level remains unexplored. We find that, during training, the ratio of positive over negative samples varies across pyramid levels (\emph{level imbalance}), which is not addressed by current one-stage detectors. To mediate the influence of level imbalance, we propose a Unified Multi-level Optimization Paradigm (UMOP) consisting of two components: 1) an independent classification loss supervising each pyramid level with individual resampling considerations; 2) a progressive hard-case mining loss defining all losses across the pyramid levels without extra level-wise settings. With UMOP as a plug-and-play scheme, modern one-stage detectors can attain a ~1.5 AP improvement with fewer training iterations and no additional computation overhead. Our best model achieves 55.1 AP on COCO test-dev. Code is available at https://github.com/zimoqingfeng/UMOP.
Robust Collaborative Learning of Patch-level and Image-level Annotations for Diabetic Retinopathy Grading from Fundus Image
Aug 03, 2020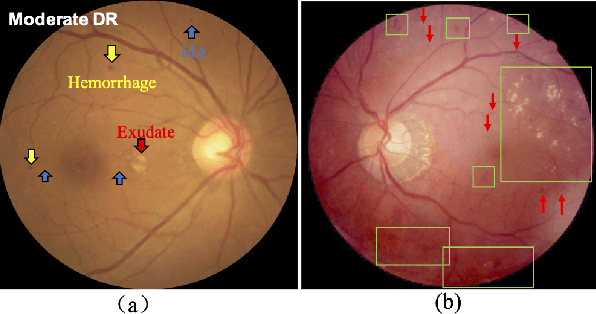
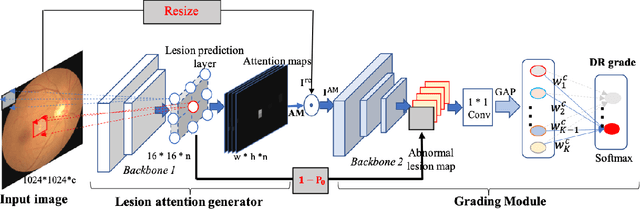
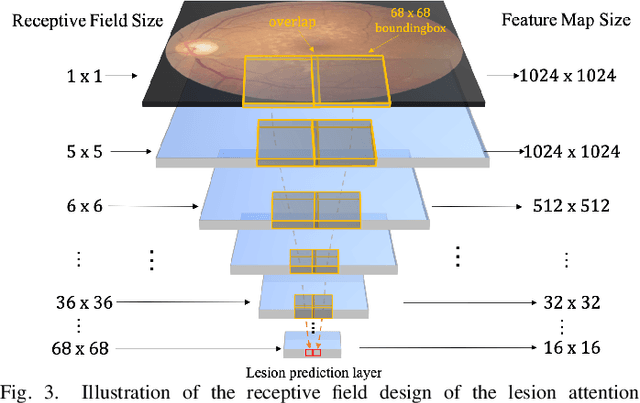
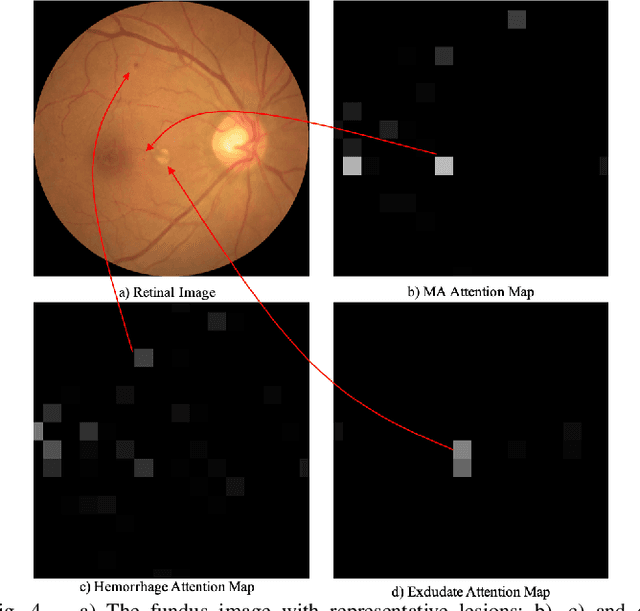
Currently, diabetic retinopathy (DR) grading from fundus images has attracted incremental interests in both academic and industrial communities. Most convolutional neural networks (CNNs) based algorithms treat DR grading as a classification task via image-level annotations. However, they have not fully explored the valuable information from the DR-related lesions. In this paper, we present a robust framework, which can collaboratively utilize both patch-level lesion and image-level grade annotations, for DR severity grading. By end-to-end optimizing the entire framework, the fine-grained lesion and image-level grade information can be bidirectionally exchanged to exploit more discriminative features for DR grading. Compared with the recent state-of-the-art algorithms and three over 9-years clinical experienced ophthalmologists, the proposed algorithm shows favorable performance. Testing on the datasets from totally different scenarios and distributions (such as label and camera), our algorithm is proved robust in facing image quality and distribution problems that commonly exist in real-world practice. Extensive ablation studies dissect the proposed framework and indicate the effectiveness and necessity of each motivation. The code and some valuable annotations are now publicly available.
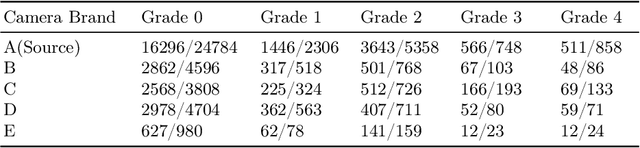
Residual-CycleGAN based Camera Adaptation for Robust Diabetic Retinopathy Screening
Jul 31, 2020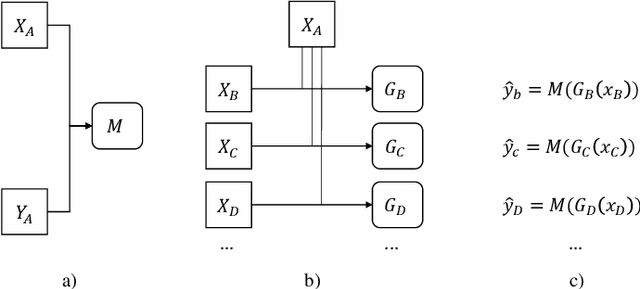
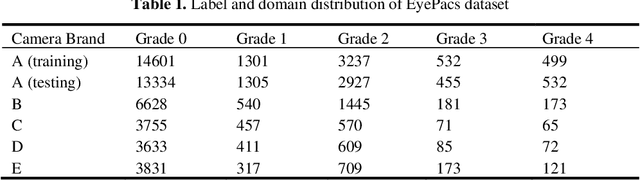
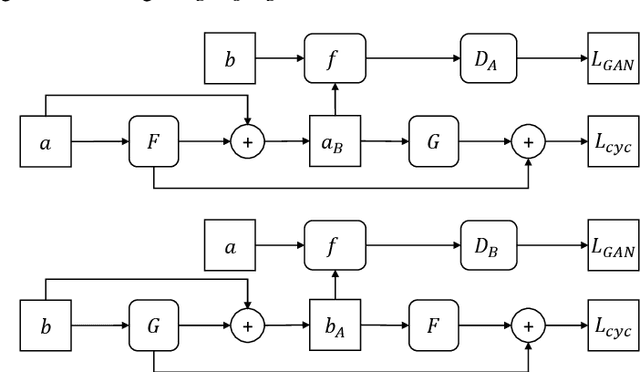
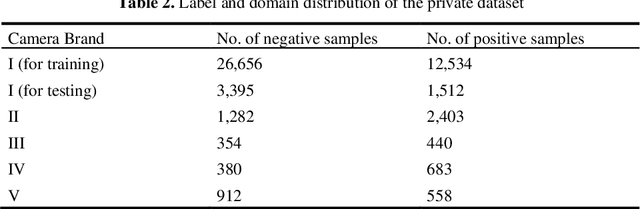
There are extensive researches focusing on automated diabetic reti-nopathy (DR) detection from fundus images. However, the accuracy drop is ob-served when applying these models in real-world DR screening, where the fun-dus camera brands are different from the ones used to capture the training im-ages. How can we train a classification model on labeled fundus images ac-quired from only one camera brand, yet still achieves good performance on im-ages taken by other brands of cameras? In this paper, we quantitatively verify the impact of fundus camera brands related domain shift on the performance of DR classification models, from an experimental perspective. Further, we pro-pose camera-oriented residual-CycleGAN to mitigate the camera brand differ-ence by domain adaptation and achieve increased classification performance on target camera images. Extensive ablation experiments on both the EyePACS da-taset and a private dataset show that the camera brand difference can signifi-cantly impact the classification performance and prove that our proposed meth-od can effectively improve the model performance on the target domain. We have inferred and labeled the camera brand for each image in the EyePACS da-taset and will publicize the camera brand labels for further research on domain adaptation.