 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpinions Vary? Diagnosis First!
Paper and Code
Feb 14, 2022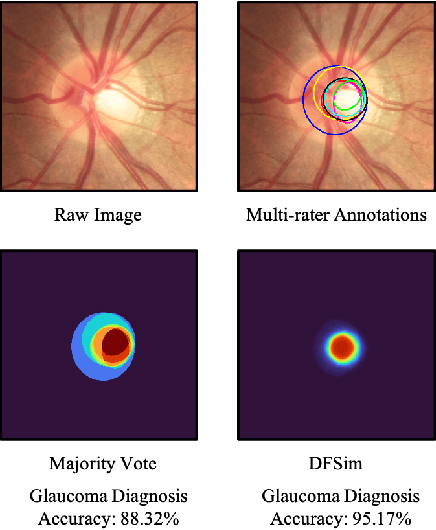
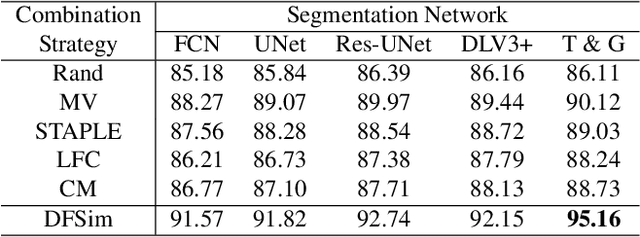
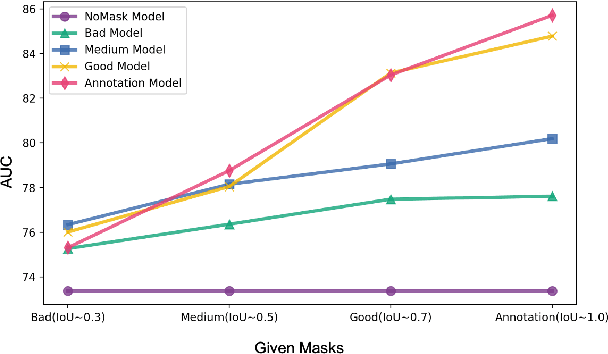
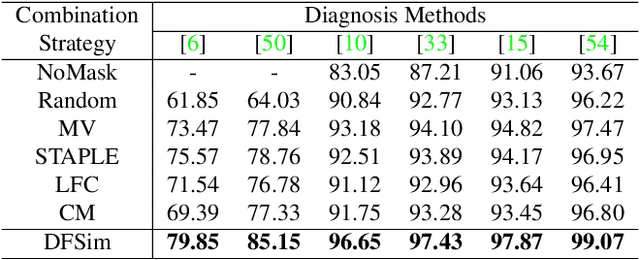
In medical image segmentation, images are usually annotated by several different clinical experts. This clinical routine helps to mitigate the personal bias. However, Computer Vision models often assume there has a unique ground-truth for each of the instance. This research gap between Computer Vision and medical routine is commonly existed but less explored by the current research.In this paper, we try to answer the following two questions: 1. How to learn an optimal combination of the multiple segmentation labels? and 2. How to estimate this segmentation mask from the raw image? We note that in clinical practice, the image segmentation mask usually exists as an auxiliary information for disease diagnosis. Adhering to this mindset, we propose a framework taking the diagnosis result as the gold standard, to estimate the segmentation mask upon the multi-rater segmentation labels, named DiFF (Diagnosis First segmentation Framework).DiFF is implemented by two novelty techniques. First, DFSim (Diagnosis First Simulation of gold label) is learned as an optimal combination of multi-rater segmentation labels for the disease diagnosis. Then, toward estimating DFSim mask from the raw image, we further propose T\&G Module (Take and Give Module) to instill the diagnosis knowledge into the segmentation network. The experiments show that compared with commonly used majority vote, the proposed DiFF is able to segment the masks with 6% improvement on diagnosis AUC score, which also outperforms various state-of-the-art multi-rater methods by a large margin.