 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting
May 20, 2025Document image parsing is challenging due to its complexly intertwined elements such as text paragraphs, figures, formulas, and tables. Current approaches either assemble specialized expert models or directly generate page-level content autoregressively, facing integration overhead, efficiency bottlenecks, and layout structure degradation despite their decent performance. To address these limitations, we present \textit{Dolphin} (\textit{\textbf{Do}cument Image \textbf{P}arsing via \textbf{H}eterogeneous Anchor Prompt\textbf{in}g}), a novel multimodal document image parsing model following an analyze-then-parse paradigm. In the first stage, Dolphin generates a sequence of layout elements in reading order. These heterogeneous elements, serving as anchors and coupled with task-specific prompts, are fed back to Dolphin for parallel content parsing in the second stage. To train Dolphin, we construct a large-scale dataset of over 30 million samples, covering multi-granularity parsing tasks. Through comprehensive evaluations on both prevalent benchmarks and self-constructed ones, Dolphin achieves state-of-the-art performance across diverse page-level and element-level settings, while ensuring superior efficiency through its lightweight architecture and parallel parsing mechanism. The code and pre-trained models are publicly available at https://github.com/ByteDance/Dolphin
OCRBench v2: An Improved Benchmark for Evaluating Large Multimodal Models on Visual Text Localization and Reasoning
Dec 31, 2024



Scoring the Optical Character Recognition (OCR) capabilities of Large Multimodal Models (LMMs) has witnessed growing interest recently. Existing benchmarks have highlighted the impressive performance of LMMs in text recognition; however, their abilities on certain challenging tasks, such as text localization, handwritten content extraction, and logical reasoning, remain underexplored. To bridge this gap, we introduce OCRBench v2, a large-scale bilingual text-centric benchmark with currently the most comprehensive set of tasks (4x more tasks than the previous multi-scene benchmark OCRBench), the widest coverage of scenarios (31 diverse scenarios including street scene, receipt, formula, diagram, and so on), and thorough evaluation metrics, with a total of 10,000 human-verified question-answering pairs and a high proportion of difficult samples. After carefully benchmarking state-of-the-art LMMs on OCRBench v2, we find that 20 out of 22 LMMs score below 50 (100 in total) and suffer from five-type limitations, including less frequently encountered text recognition, fine-grained perception, layout perception, complex element parsing, and logical reasoning. The benchmark and evaluation scripts are available at https://github.com/Yuliang-liu/MultimodalOCR.
Harmonizing Visual Text Comprehension and Generation
Jul 23, 2024



In this work, we present TextHarmony, a unified and versatile multimodal generative model proficient in comprehending and generating visual text. Simultaneously generating images and texts typically results in performance degradation due to the inherent inconsistency between vision and language modalities. To overcome this challenge, existing approaches resort to modality-specific data for supervised fine-tuning, necessitating distinct model instances. We propose Slide-LoRA, which dynamically aggregates modality-specific and modality-agnostic LoRA experts, partially decoupling the multimodal generation space. Slide-LoRA harmonizes the generation of vision and language within a singular model instance, thereby facilitating a more unified generative process. Additionally, we develop a high-quality image caption dataset, DetailedTextCaps-100K, synthesized with a sophisticated closed-source MLLM to enhance visual text generation capabilities further. Comprehensive experiments across various benchmarks demonstrate the effectiveness of the proposed approach. Empowered by Slide-LoRA, TextHarmony achieves comparable performance to modality-specific fine-tuning results with only a 2% increase in parameters and shows an average improvement of 2.5% in visual text comprehension tasks and 4.0% in visual text generation tasks. Our work delineates the viability of an integrated approach to multimodal generation within the visual text domain, setting a foundation for subsequent inquiries.
A Bounding Box is Worth One Token: Interleaving Layout and Text in a Large Language Model for Document Understanding
Jul 02, 2024



Recently, many studies have demonstrated that exclusively incorporating OCR-derived text and spatial layouts with large language models (LLMs) can be highly effective for document understanding tasks. However, existing methods that integrate spatial layouts with text have limitations, such as producing overly long text sequences or failing to fully leverage the autoregressive traits of LLMs. In this work, we introduce Interleaving Layout and Text in a Large Language Model (LayTextLLM)} for document understanding. In particular, LayTextLLM projects each bounding box to a single embedding and interleaves it with text, efficiently avoiding long sequence issues while leveraging autoregressive traits of LLMs. LayTextLLM not only streamlines the interaction of layout and textual data but also shows enhanced performance in Key Information Extraction (KIE) and Visual Question Answering (VQA). Comprehensive benchmark evaluations reveal significant improvements, with a 27.0% increase on KIE tasks and 24.1% on VQA tasks compared to previous state-of-the-art document understanding MLLMs, as well as a 15.5% improvement over other SOTA OCR-based LLMs on KIE tasks.
TabPedia: Towards Comprehensive Visual Table Understanding with Concept Synergy
Jun 03, 2024



Tables contain factual and quantitative data accompanied by various structures and contents that pose challenges for machine comprehension. Previous methods generally design task-specific architectures and objectives for individual tasks, resulting in modal isolation and intricate workflows. In this paper, we present a novel large vision-language model, TabPedia, equipped with a concept synergy mechanism. In this mechanism, all the involved diverse visual table understanding (VTU) tasks and multi-source visual embeddings are abstracted as concepts. This unified framework allows TabPedia to seamlessly integrate VTU tasks, such as table detection, table structure recognition, table querying, and table question answering, by leveraging the capabilities of large language models (LLMs). Moreover, the concept synergy mechanism enables table perception-related and comprehension-related tasks to work in harmony, as they can effectively leverage the needed clues from the corresponding source perception embeddings. Furthermore, to better evaluate the VTU task in real-world scenarios, we establish a new and comprehensive table VQA benchmark, ComTQA, featuring approximately 9,000 QA pairs. Extensive quantitative and qualitative experiments on both table perception and comprehension tasks, conducted across various public benchmarks, validate the effectiveness of our TabPedia. The superior performance further confirms the feasibility of using LLMs for understanding visual tables when all concepts work in synergy. The benchmark ComTQA has been open-sourced at https://huggingface.co/datasets/ByteDance/ComTQA. The source code and model will be released later.
TextSquare: Scaling up Text-Centric Visual Instruction Tuning
Apr 19, 2024



Text-centric visual question answering (VQA) has made great strides with the development of Multimodal Large Language Models (MLLMs), yet open-source models still fall short of leading models like GPT4V and Gemini, partly due to a lack of extensive, high-quality instruction tuning data. To this end, we introduce a new approach for creating a massive, high-quality instruction-tuning dataset, Square-10M, which is generated using closed-source MLLMs. The data construction process, termed Square, consists of four steps: Self-Questioning, Answering, Reasoning, and Evaluation. Our experiments with Square-10M led to three key findings: 1) Our model, TextSquare, considerably surpasses open-source previous state-of-the-art Text-centric MLLMs and sets a new standard on OCRBench(62.2%). It even outperforms top-tier models like GPT4V and Gemini in 6 of 10 text-centric benchmarks. 2) Additionally, we demonstrate the critical role of VQA reasoning data in offering comprehensive contextual insights for specific questions. This not only improves accuracy but also significantly mitigates hallucinations. Specifically, TextSquare scores an average of 75.1% across four general VQA and hallucination evaluation datasets, outperforming previous state-of-the-art models. 3) Notably, the phenomenon observed in scaling text-centric VQA datasets reveals a vivid pattern: the exponential increase of instruction tuning data volume is directly proportional to the improvement in model performance, thereby validating the necessity of the dataset scale and the high quality of Square-10M.
Multi-modal In-Context Learning Makes an Ego-evolving Scene Text Recognizer
Nov 23, 2023



Scene text recognition (STR) in the wild frequently encounters challenges when coping with domain variations, font diversity, shape deformations, etc. A straightforward solution is performing model fine-tuning tailored to a specific scenario, but it is computationally intensive and requires multiple model copies for various scenarios. Recent studies indicate that large language models (LLMs) can learn from a few demonstration examples in a training-free manner, termed "In-Context Learning" (ICL). Nevertheless, applying LLMs as a text recognizer is unacceptably resource-consuming. Moreover, our pilot experiments on LLMs show that ICL fails in STR, mainly attributed to the insufficient incorporation of contextual information from diverse samples in the training stage. To this end, we introduce E$^2$STR, a STR model trained with context-rich scene text sequences, where the sequences are generated via our proposed in-context training strategy. E$^2$STR demonstrates that a regular-sized model is sufficient to achieve effective ICL capabilities in STR. Extensive experiments show that E$^2$STR exhibits remarkable training-free adaptation in various scenarios and outperforms even the fine-tuned state-of-the-art approaches on public benchmarks.
Contrastive Centroid Supervision Alleviates Domain Shift in Medical Image Classification
May 31, 2022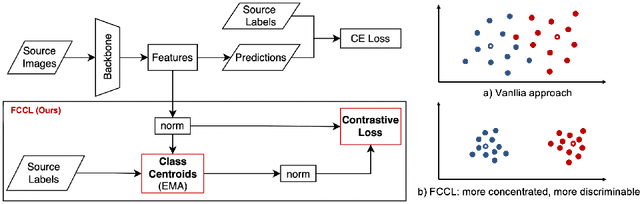


Deep learning based medical imaging classification models usually suffer from the domain shift problem, where the classification performance drops when training data and real-world data differ in imaging equipment manufacturer, image acquisition protocol, patient populations, etc. We propose Feature Centroid Contrast Learning (FCCL), which can improve target domain classification performance by extra supervision during training with contrastive loss between instance and class centroid. Compared with current unsupervised domain adaptation and domain generalization methods, FCCL performs better while only requires labeled image data from a single source domain and no target domain. We verify through extensive experiments that FCCL can achieve superior performance on at least three imaging modalities, i.e. fundus photographs, dermatoscopic images, and H & E tissue images.
Opinions Vary? Diagnosis First!
Feb 14, 2022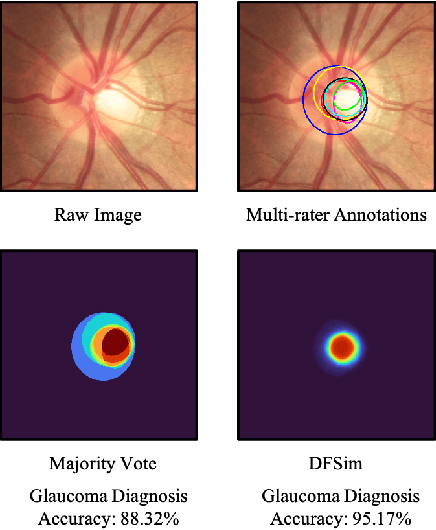
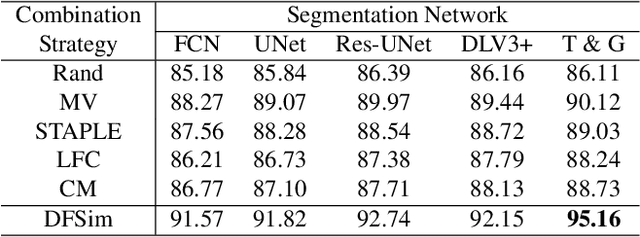
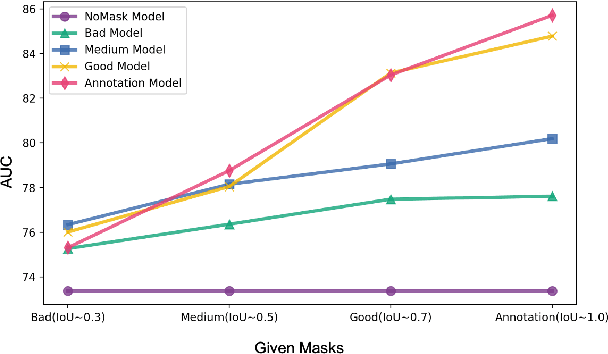
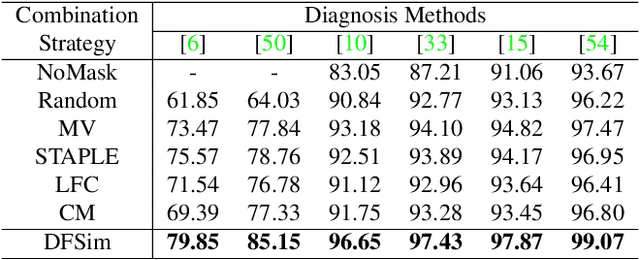
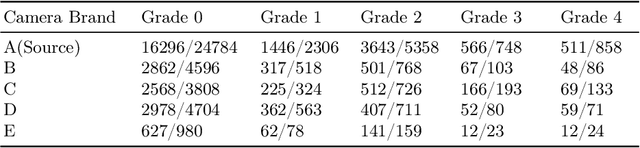
In medical image segmentation, images are usually annotated by several different clinical experts. This clinical routine helps to mitigate the personal bias. However, Computer Vision models often assume there has a unique ground-truth for each of the instance. This research gap between Computer Vision and medical routine is commonly existed but less explored by the current research.In this paper, we try to answer the following two questions: 1. How to learn an optimal combination of the multiple segmentation labels? and 2. How to estimate this segmentation mask from the raw image? We note that in clinical practice, the image segmentation mask usually exists as an auxiliary information for disease diagnosis. Adhering to this mindset, we propose a framework taking the diagnosis result as the gold standard, to estimate the segmentation mask upon the multi-rater segmentation labels, named DiFF (Diagnosis First segmentation Framework).DiFF is implemented by two novelty techniques. First, DFSim (Diagnosis First Simulation of gold label) is learned as an optimal combination of multi-rater segmentation labels for the disease diagnosis. Then, toward estimating DFSim mask from the raw image, we further propose T\&G Module (Take and Give Module) to instill the diagnosis knowledge into the segmentation network. The experiments show that compared with commonly used majority vote, the proposed DiFF is able to segment the masks with 6% improvement on diagnosis AUC score, which also outperforms various state-of-the-art multi-rater methods by a large margin.