 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKiToke: Kernel-based Interval-aware Token Compression for Video Large Language Models
Apr 03, 2026Video Large Language Models (Video LLMs) achieve strong performance on video understanding tasks but suffer from high inference costs due to the large number of visual tokens. We propose KiToke, a training-free, query-agnostic token compression approach that reduces spatiotemporal redundancy while preserving critical visual information. Our method estimates token diversity globally using a kernel-based redundancy measure, enabling content-adaptive selection that remains effective under extreme token budgets, and further introduces a lightweight temporal interval construction with interval-aware token merging to maintain temporal coherence. Unlike prior methods that rely on local or segment-level heuristics, KiToke explicitly captures global redundancy across an entire video, leading to more efficient token utilization. Extensive experiments on multiple video understanding benchmarks and Video LLM backbones demonstrate that KiToke consistently outperforms existing training-free compression methods, with particularly large gains at aggressive retention ratios down to 1%.
Chat-Scene++: Exploiting Context-Rich Object Identification for 3D LLM
Mar 29, 2026Recent advancements in multi-modal large language models (MLLMs) have shown strong potential for 3D scene understanding. However, existing methods struggle with fine-grained object grounding and contextual reasoning, limiting their ability to interpret and interact with complex 3D environments. In this paper, we present Chat-Scene++, an MLLM framework that represents 3D scenes as context-rich object sequences. By structuring scenes as sequences of objects with contextual semantics, Chat-Scene++ enables object-centric representation and interaction. It decomposes a 3D scene into object representations paired with identifier tokens, allowing LLMs to follow instructions across diverse 3D vision-language tasks. To capture inter-object relationships and global semantics, Chat-Scene++ extracts context-rich object features using large-scale pre-trained 3D scene-level and 2D image-level encoders, unlike the isolated per-object features in Chat-Scene. Its flexible object-centric design also supports grounded chain-of-thought (G-CoT) reasoning, enabling the model to distinguish objects at both category and spatial levels during multi-step inference. Without the need for additional task-specific heads or fine-tuning, Chat-Scene++ achieves state-of-the-art performance on five major 3D vision-language benchmarks: ScanRefer, Multi3DRefer, Scan2Cap, ScanQA, and SQA3D. These results highlight its effectiveness in scene comprehension, object grounding, and spatial reasoning. Additionally, without reconstructing 3D worlds through computationally expensive processes, we demonstrate its applicability to real-world scenarios using only 2D inputs.
GENMANIP: LLM-driven Simulation for Generalizable Instruction-Following Manipulation
Jun 12, 2025
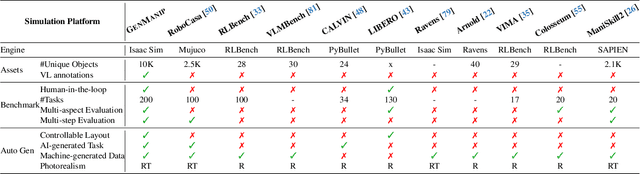

Robotic manipulation in real-world settings remains challenging, especially regarding robust generalization. Existing simulation platforms lack sufficient support for exploring how policies adapt to varied instructions and scenarios. Thus, they lag behind the growing interest in instruction-following foundation models like LLMs, whose adaptability is crucial yet remains underexplored in fair comparisons. To bridge this gap, we introduce GenManip, a realistic tabletop simulation platform tailored for policy generalization studies. It features an automatic pipeline via LLM-driven task-oriented scene graph to synthesize large-scale, diverse tasks using 10K annotated 3D object assets. To systematically assess generalization, we present GenManip-Bench, a benchmark of 200 scenarios refined via human-in-the-loop corrections. We evaluate two policy types: (1) modular manipulation systems integrating foundation models for perception, reasoning, and planning, and (2) end-to-end policies trained through scalable data collection. Results show that while data scaling benefits end-to-end methods, modular systems enhanced with foundation models generalize more effectively across diverse scenarios. We anticipate this platform to facilitate critical insights for advancing policy generalization in realistic conditions. Project Page: https://genmanip.axi404.top/.
RoboGround: Robotic Manipulation with Grounded Vision-Language Priors
Apr 30, 2025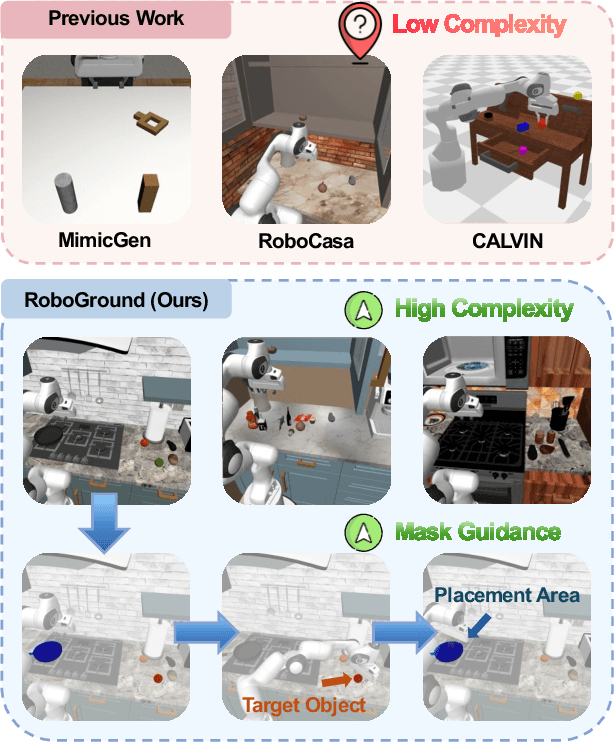

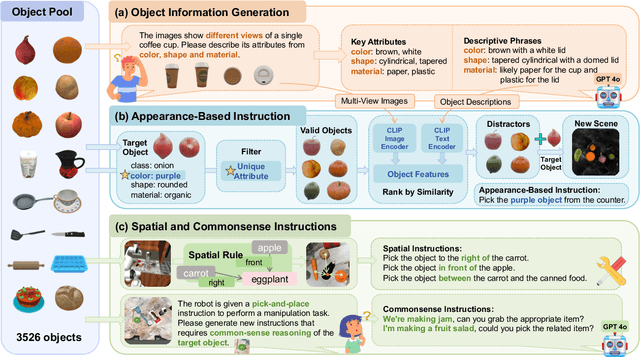
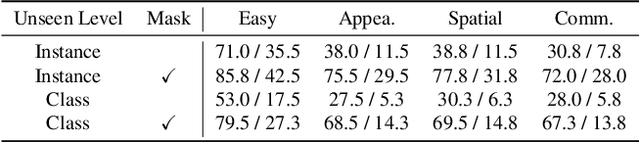
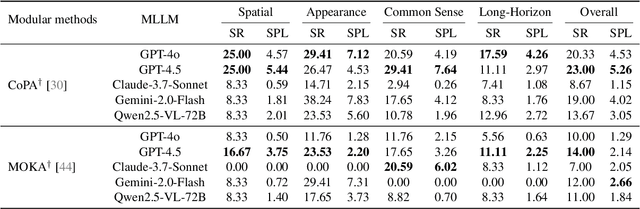
Recent advancements in robotic manipulation have highlighted the potential of intermediate representations for improving policy generalization. In this work, we explore grounding masks as an effective intermediate representation, balancing two key advantages: (1) effective spatial guidance that specifies target objects and placement areas while also conveying information about object shape and size, and (2) broad generalization potential driven by large-scale vision-language models pretrained on diverse grounding datasets. We introduce RoboGround, a grounding-aware robotic manipulation system that leverages grounding masks as an intermediate representation to guide policy networks in object manipulation tasks. To further explore and enhance generalization, we propose an automated pipeline for generating large-scale, simulated data with a diverse set of objects and instructions. Extensive experiments show the value of our dataset and the effectiveness of grounding masks as intermediate guidance, significantly enhancing the generalization abilities of robot policies.
Towards a Multimodal Large Language Model with Pixel-Level Insight for Biomedicine
Dec 12, 2024In recent years, Multimodal Large Language Models (MLLM) have achieved notable advancements, demonstrating the feasibility of developing an intelligent biomedical assistant. However, current biomedical MLLMs predominantly focus on image-level understanding and restrict interactions to textual commands, thus limiting their capability boundaries and the flexibility of usage. In this paper, we introduce a novel end-to-end multimodal large language model for the biomedical domain, named MedPLIB, which possesses pixel-level understanding. Excitingly, it supports visual question answering (VQA), arbitrary pixel-level prompts (points, bounding boxes, and free-form shapes), and pixel-level grounding. We propose a novel Mixture-of-Experts (MoE) multi-stage training strategy, which divides MoE into separate training phases for a visual-language expert model and a pixel-grounding expert model, followed by fine-tuning using MoE. This strategy effectively coordinates multitask learning while maintaining the computational cost at inference equivalent to that of a single expert model. To advance the research of biomedical MLLMs, we introduce the Medical Complex Vision Question Answering Dataset (MeCoVQA), which comprises an array of 8 modalities for complex medical imaging question answering and image region understanding. Experimental results indicate that MedPLIB has achieved state-of-the-art outcomes across multiple medical visual language tasks. More importantly, in zero-shot evaluations for the pixel grounding task, MedPLIB leads the best small and large models by margins of 19.7 and 15.6 respectively on the mDice metric. The codes, data, and model checkpoints will be made publicly available at https://github.com/ShawnHuang497/MedPLIB.
Improving Retrieval Augmented Language Model with Self-Reasoning
Jul 29, 2024The Retrieval-Augmented Language Model (RALM) has shown remarkable performance on knowledge-intensive tasks by incorporating external knowledge during inference, which mitigates the factual hallucinations inherited in large language models (LLMs). Despite these advancements, challenges persist in the implementation of RALMs, particularly concerning their reliability and traceability. To be specific, the irrelevant document retrieval may result in unhelpful response generation or even deteriorate the performance of LLMs, while the lack of proper citations in generated outputs complicates efforts to verify the trustworthiness of the models. To this end, we propose a novel self-reasoning framework aimed at improving the reliability and traceability of RALMs, whose core idea is to leverage reasoning trajectories generated by the LLM itself. The framework involves constructing self-reason trajectories with three processes: a relevance-aware process, an evidence-aware selective process, and a trajectory analysis process. We have evaluated our framework across four public datasets (two short-form QA datasets, one long-form QA dataset, and one fact verification dataset) to demonstrate the superiority of our method, which can outperform existing state-of-art models and can achieve comparable performance with GPT-4, while only using 2,000 training samples.
A Refer-and-Ground Multimodal Large Language Model for Biomedicine
Jun 26, 2024With the rapid development of multimodal large language models (MLLMs), especially their capabilities in visual chat through refer and ground functionalities, their significance is increasingly recognized. However, the biomedical field currently exhibits a substantial gap in this area, primarily due to the absence of a dedicated refer and ground dataset for biomedical images. To address this challenge, we devised the Med-GRIT-270k dataset. It comprises 270k question-and-answer pairs and spans eight distinct medical imaging modalities. Most importantly, it is the first dedicated to the biomedical domain and integrating refer and ground conversations. The key idea is to sample large-scale biomedical image-mask pairs from medical segmentation datasets and generate instruction datasets from text using chatGPT. Additionally, we introduce a Refer-and-Ground Multimodal Large Language Model for Biomedicine (BiRD) by using this dataset and multi-task instruction learning. Extensive experiments have corroborated the efficacy of the Med-GRIT-270k dataset and the multi-modal, fine-grained interactive capabilities of the BiRD model. This holds significant reference value for the exploration and development of intelligent biomedical assistants.
MMScan: A Multi-Modal 3D Scene Dataset with Hierarchical Grounded Language Annotations
Jun 13, 2024



With the emergence of LLMs and their integration with other data modalities, multi-modal 3D perception attracts more attention due to its connectivity to the physical world and makes rapid progress. However, limited by existing datasets, previous works mainly focus on understanding object properties or inter-object spatial relationships in a 3D scene. To tackle this problem, this paper builds the first largest ever multi-modal 3D scene dataset and benchmark with hierarchical grounded language annotations, MMScan. It is constructed based on a top-down logic, from region to object level, from a single target to inter-target relationships, covering holistic aspects of spatial and attribute understanding. The overall pipeline incorporates powerful VLMs via carefully designed prompts to initialize the annotations efficiently and further involve humans' correction in the loop to ensure the annotations are natural, correct, and comprehensive. Built upon existing 3D scanning data, the resulting multi-modal 3D dataset encompasses 1.4M meta-annotated captions on 109k objects and 7.7k regions as well as over 3.04M diverse samples for 3D visual grounding and question-answering benchmarks. We evaluate representative baselines on our benchmarks, analyze their capabilities in different aspects, and showcase the key problems to be addressed in the future. Furthermore, we use this high-quality dataset to train state-of-the-art 3D visual grounding and LLMs and obtain remarkable performance improvement both on existing benchmarks and in-the-wild evaluation. Codes, datasets, and benchmarks will be available at https://github.com/OpenRobotLab/EmbodiedScan.
Grounded 3D-LLM with Referent Tokens
May 16, 2024Prior studies on 3D scene understanding have primarily developed specialized models for specific tasks or required task-specific fine-tuning. In this study, we propose Grounded 3D-LLM, which explores the potential of 3D large multi-modal models (3D LMMs) to consolidate various 3D vision tasks within a unified generative framework. The model uses scene referent tokens as special noun phrases to reference 3D scenes, enabling the handling of sequences that interleave 3D and textual data. It offers a natural approach for translating 3D vision tasks into language formats using task-specific instruction templates. To facilitate the use of referent tokens in subsequent language modeling, we have curated large-scale grounded language datasets that offer finer scene-text correspondence at the phrase level by bootstrapping existing object labels. Subsequently, we introduced Contrastive LAnguage-Scene Pre-training (CLASP) to effectively leverage this data, thereby integrating 3D vision with language models. Our comprehensive evaluation covers open-ended tasks like dense captioning and 3D QA, alongside close-ended tasks such as object detection and language grounding. Experiments across multiple 3D benchmarks reveal the leading performance and the broad applicability of Grounded 3D-LLM. Code and datasets will be released on the project page: https://groundedscenellm.github.io/grounded_3d-llm.github.io.
FreeBind: Free Lunch in Unified Multimodal Space via Knowledge Fusion
May 10, 2024



Unified multi-model representation spaces are the foundation of multimodal understanding and generation. However, the billions of model parameters and catastrophic forgetting problems make it challenging to further enhance pre-trained unified spaces. In this work, we propose FreeBind, an idea that treats multimodal representation spaces as basic units, and freely augments pre-trained unified space by integrating knowledge from extra expert spaces via "space bonds". Specifically, we introduce two kinds of basic space bonds: 1) Space Displacement Bond and 2) Space Combination Bond. Based on these basic bonds, we design Complex Sequential & Parallel Bonds to effectively integrate multiple spaces simultaneously. Benefiting from the modularization concept, we further propose a coarse-to-fine customized inference strategy to flexibly adjust the enhanced unified space for different purposes. Experimentally, we bind ImageBind with extra image-text and audio-text expert spaces, resulting in three main variants: ImageBind++, InternVL_IB, and InternVL_IB++. These resulting spaces outperform ImageBind on 5 audio-image-text downstream tasks across 9 datasets. Moreover, via customized inference, it even surpasses the advanced audio-text and image-text expert spaces.