 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2A-Feedback: Improving Basic Capabilities of Text-to-Audio Generation via Fine-grained AI Feedback
May 15, 2025

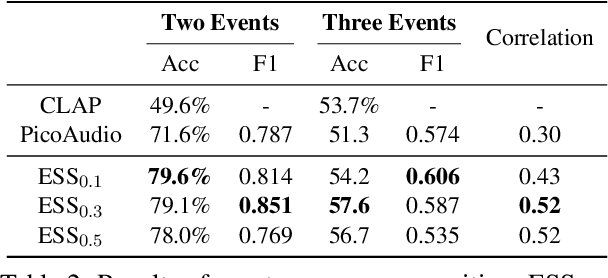

Text-to-audio (T2A) generation has achieved remarkable progress in generating a variety of audio outputs from language prompts. However, current state-of-the-art T2A models still struggle to satisfy human preferences for prompt-following and acoustic quality when generating complex multi-event audio. To improve the performance of the model in these high-level applications, we propose to enhance the basic capabilities of the model with AI feedback learning. First, we introduce fine-grained AI audio scoring pipelines to: 1) verify whether each event in the text prompt is present in the audio (Event Occurrence Score), 2) detect deviations in event sequences from the language description (Event Sequence Score), and 3) assess the overall acoustic and harmonic quality of the generated audio (Acoustic&Harmonic Quality). We evaluate these three automatic scoring pipelines and find that they correlate significantly better with human preferences than other evaluation metrics. This highlights their value as both feedback signals and evaluation metrics. Utilizing our robust scoring pipelines, we construct a large audio preference dataset, T2A-FeedBack, which contains 41k prompts and 249k audios, each accompanied by detailed scores. Moreover, we introduce T2A-EpicBench, a benchmark that focuses on long captions, multi-events, and story-telling scenarios, aiming to evaluate the advanced capabilities of T2A models. Finally, we demonstrate how T2A-FeedBack can enhance current state-of-the-art audio model. With simple preference tuning, the audio generation model exhibits significant improvements in both simple (AudioCaps test set) and complex (T2A-EpicBench) scenarios.
Improving Long-Text Alignment for Text-to-Image Diffusion Models
Oct 15, 2024



The rapid advancement of text-to-image (T2I) diffusion models has enabled them to generate unprecedented results from given texts. However, as text inputs become longer, existing encoding methods like CLIP face limitations, and aligning the generated images with long texts becomes challenging. To tackle these issues, we propose LongAlign, which includes a segment-level encoding method for processing long texts and a decomposed preference optimization method for effective alignment training. For segment-level encoding, long texts are divided into multiple segments and processed separately. This method overcomes the maximum input length limits of pretrained encoding models. For preference optimization, we provide decomposed CLIP-based preference models to fine-tune diffusion models. Specifically, to utilize CLIP-based preference models for T2I alignment, we delve into their scoring mechanisms and find that the preference scores can be decomposed into two components: a text-relevant part that measures T2I alignment and a text-irrelevant part that assesses other visual aspects of human preference. Additionally, we find that the text-irrelevant part contributes to a common overfitting problem during fine-tuning. To address this, we propose a reweighting strategy that assigns different weights to these two components, thereby reducing overfitting and enhancing alignment. After fine-tuning $512 \times 512$ Stable Diffusion (SD) v1.5 for about 20 hours using our method, the fine-tuned SD outperforms stronger foundation models in T2I alignment, such as PixArt-$\alpha$ and Kandinsky v2.2. The code is available at https://github.com/luping-liu/LongAlign.
OmniBind: Large-scale Omni Multimodal Representation via Binding Spaces
Jul 16, 2024



Recently, human-computer interaction with various modalities has shown promising applications, like GPT-4o and Gemini. Given the foundational role of multimodal joint representation in understanding and generation pipelines, high-quality omni joint representations would be a step toward co-processing more diverse multimodal information. In this work, we present OmniBind, large-scale multimodal joint representation models ranging in scale from 7 billion to 30 billion parameters, which support 3D, audio, image, and language inputs. Due to the scarcity of data pairs across all modalities, instead of training large models from scratch, we propose remapping and binding the spaces of various pre-trained specialist models together. This approach enables "scaling up" by indirectly increasing the model parameters and the amount of seen data. To effectively integrate various spaces, we dynamically assign weights to different spaces by learning routers with two objectives: cross-modal overall alignment and language representation decoupling. Notably, since binding and routing spaces both only require lightweight networks, OmniBind is extremely training-efficient. Learning the largest 30B model requires merely unpaired unimodal data and approximately 3 days on a single 8-4090 node. Extensive experiments demonstrate the versatility and superiority of OmniBind as an omni representation model, highlighting its great potential for diverse applications, such as any-query and composable multimodal understanding.
FreeBind: Free Lunch in Unified Multimodal Space via Knowledge Fusion
May 10, 2024



Unified multi-model representation spaces are the foundation of multimodal understanding and generation. However, the billions of model parameters and catastrophic forgetting problems make it challenging to further enhance pre-trained unified spaces. In this work, we propose FreeBind, an idea that treats multimodal representation spaces as basic units, and freely augments pre-trained unified space by integrating knowledge from extra expert spaces via "space bonds". Specifically, we introduce two kinds of basic space bonds: 1) Space Displacement Bond and 2) Space Combination Bond. Based on these basic bonds, we design Complex Sequential & Parallel Bonds to effectively integrate multiple spaces simultaneously. Benefiting from the modularization concept, we further propose a coarse-to-fine customized inference strategy to flexibly adjust the enhanced unified space for different purposes. Experimentally, we bind ImageBind with extra image-text and audio-text expert spaces, resulting in three main variants: ImageBind++, InternVL_IB, and InternVL_IB++. These resulting spaces outperform ImageBind on 5 audio-image-text downstream tasks across 9 datasets. Moreover, via customized inference, it even surpasses the advanced audio-text and image-text expert spaces.
Molecule-Space: Free Lunch in Unified Multimodal Space via Knowledge Fusion
May 08, 2024Unified multi-model representation spaces are the foundation of multimodal understanding and generation. However, the billions of model parameters and catastrophic forgetting problems make it challenging to further enhance pre-trained unified spaces. In this work, we propose Molecule-Space, an idea that treats multimodal representation spaces as "molecules", and augments pre-trained unified space by integrating knowledge from extra expert spaces via "molecules space reactions". Specifically, we introduce two kinds of basic space reactions: 1) Space Displacement Reaction and 2) Space Combination Reaction. Based on these defined basic reactions, we design Complex Sequential & Parallel Reactions to effectively integrate multiple spaces simultaneously. Benefiting from the modularization concept, we further propose a coarse-to-fine customized inference strategy to flexibly adjust the enhanced unified space for different purposes. Experimentally, we fuse the audio-image-text space of ImageBind with the image-text and audio-text expert spaces. The resulting space outperforms ImageBind on 5 downstream tasks across 9 datasets. Moreover, via customized inference, it even surpasses the used image-text and audio-text expert spaces.
Chat-3D v2: Bridging 3D Scene and Large Language Models with Object Identifiers
Dec 15, 2023



Recent research has evidenced the significant potentials of Large Language Models (LLMs) in handling challenging tasks within 3D scenes. However, current models are constrained to addressing object-centric tasks, where each question-answer pair focuses solely on an individual object. In real-world applications, users may pose queries involving multiple objects or expect for answers that precisely reference various objects. We introduce the use of object identifiers to freely reference objects during a conversation. While this solution appears straightforward, it presents two main challenges: 1) How to establish a reliable one-to-one correspondence between each object and its identifier? 2) How to incorporate complex spatial relationships among dozens of objects into the embedding space of the LLM? To address these challenges, we propose a two-stage alignment method, which involves learning an attribute-aware token and a relation-aware token for each object. These tokens capture the object's attributes and spatial relationships with surrounding objects in the 3D scene. Once the alignment is established, we can fine-tune our model on various downstream tasks using instruction tuning. Experiments conducted on traditional datasets like ScanQA, ScanRefer, and Nr3D/Sr3D showcase the effectiveness of our proposed method. Additionally, we create a 3D scene captioning dataset annotated with rich object identifiers, with the assistant of GPT-4. This dataset aims to further explore the capability of object identifiers in effective object referencing and precise scene understanding.
Extending Multi-modal Contrastive Representations
Oct 13, 2023



Multi-modal contrastive representation (MCR) of more than three modalities is critical in multi-modal learning. Although recent methods showcase impressive achievements, the high dependence on large-scale, high-quality paired data and the expensive training costs limit their further development. Inspired by recent C-MCR, this paper proposes Extending Multimodal Contrastive Representation (Ex-MCR), a training-efficient and paired-data-free method to flexibly learn unified contrastive representation space for more than three modalities by integrating the knowledge of existing MCR spaces. Specifically, Ex-MCR aligns multiple existing MCRs into the same based MCR, which can effectively preserve the original semantic alignment of the based MCR. Besides, we comprehensively enhance the entire learning pipeline for aligning MCR spaces from the perspectives of training data, architecture, and learning objectives. With the preserved original modality alignment and the enhanced space alignment, Ex-MCR shows superior representation learning performance and excellent modality extensibility. To demonstrate the effectiveness of Ex-MCR, we align the MCR spaces of CLAP (audio-text) and ULIP (3D-vision) into the CLIP (vision-text), leveraging the overlapping text and image modality, respectively. Remarkably, without using any paired data, Ex-MCR learns a 3D-image-text-audio unified contrastive representation, and it achieves state-of-the-art performance on audio-visual, 3D-image, audio-text, visual-text retrieval, and 3D object classification tasks. More importantly, extensive qualitative results further demonstrate the emergent semantic alignment between the extended modalities (e.g., audio and 3D), which highlights the great potential of modality extensibility.
Detector Guidance for Multi-Object Text-to-Image Generation
Jun 04, 2023



Diffusion models have demonstrated impressive performance in text-to-image generation. They utilize a text encoder and cross-attention blocks to infuse textual information into images at a pixel level. However, their capability to generate images with text containing multiple objects is still restricted. Previous works identify the problem of information mixing in the CLIP text encoder and introduce the T5 text encoder or incorporate strong prior knowledge to assist with the alignment. We find that mixing problems also occur on the image side and in the cross-attention blocks. The noisy images can cause different objects to appear similar, and the cross-attention blocks inject information at a pixel level, leading to leakage of global object understanding and resulting in object mixing. In this paper, we introduce Detector Guidance (DG), which integrates a latent object detection model to separate different objects during the generation process. DG first performs latent object detection on cross-attention maps (CAMs) to obtain object information. Based on this information, DG then masks conflicting prompts and enhances related prompts by manipulating the following CAMs. We evaluate the effectiveness of DG using Stable Diffusion on COCO, CC, and a novel multi-related object benchmark, MRO. Human evaluations demonstrate that DG provides an 8-22\% advantage in preventing the amalgamation of conflicting concepts and ensuring that each object possesses its unique region without any human involvement and additional iterations. Our implementation is available at \url{https://github.com/luping-liu/Detector-Guidance}.
Make-A-Voice: Unified Voice Synthesis With Discrete Representation
May 30, 2023



Various applications of voice synthesis have been developed independently despite the fact that they generate "voice" as output in common. In addition, the majority of voice synthesis models currently rely on annotated audio data, but it is crucial to scale them to self-supervised datasets in order to effectively capture the wide range of acoustic variations present in human voice, including speaker identity, emotion, and prosody. In this work, we propose Make-A-Voice, a unified framework for synthesizing and manipulating voice signals from discrete representations. Make-A-Voice leverages a "coarse-to-fine" approach to model the human voice, which involves three stages: 1) semantic stage: model high-level transformation between linguistic content and self-supervised semantic tokens, 2) acoustic stage: introduce varying control signals as acoustic conditions for semantic-to-acoustic modeling, and 3) generation stage: synthesize high-fidelity waveforms from acoustic tokens. Make-A-Voice offers notable benefits as a unified voice synthesis framework: 1) Data scalability: the major backbone (i.e., acoustic and generation stage) does not require any annotations, and thus the training data could be scaled up. 2) Controllability and conditioning flexibility: we investigate different conditioning mechanisms and effectively handle three voice synthesis applications, including text-to-speech (TTS), voice conversion (VC), and singing voice synthesis (SVS) by re-synthesizing the discrete voice representations with prompt guidance. Experimental results demonstrate that Make-A-Voice exhibits superior audio quality and style similarity compared with competitive baseline models. Audio samples are available at https://Make-A-Voice.github.io
PTQD: Accurate Post-Training Quantization for Diffusion Models
May 18, 2023



Diffusion models have recently dominated image synthesis and other related generative tasks. However, the iterative denoising process is expensive in computations at inference time, making diffusion models less practical for low-latency and scalable real-world applications. Post-training quantization of diffusion models can significantly reduce the model size and accelerate the sampling process without requiring any re-training. Nonetheless, applying existing post-training quantization methods directly to low-bit diffusion models can significantly impair the quality of generated samples. Specifically, for each denoising step, quantization noise leads to deviations in the estimated mean and mismatches with the predetermined variance schedule. Moreover, as the sampling process proceeds, the quantization noise may accumulate, resulting in a low signal-to-noise ratio (SNR) in late denoising steps. To address these challenges, we propose a unified formulation for the quantization noise and diffusion perturbed noise in the quantized denoising process. We first disentangle the quantization noise into its correlated and residual uncorrelated parts regarding its full-precision counterpart. The correlated part can be easily corrected by estimating the correlation coefficient. For the uncorrelated part, we calibrate the denoising variance schedule to absorb the excess variance resulting from quantization. Moreover, we propose a mixed-precision scheme to choose the optimal bitwidth for each denoising step, which prefers low bits to accelerate the early denoising steps while high bits maintain the high SNR for the late steps. Extensive experiments demonstrate that our method outperforms previous post-training quantized diffusion models in generating high-quality samples, with only a 0.06 increase in FID score compared to full-precision LDM-4 on ImageNet 256x256, while saving 19.9x bit operations.