 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Negative Samples Are Equal: LLMs Learn Better from Plausible Reasoning
Feb 03, 2026Learning from negative samples holds great promise for improving Large Language Model (LLM) reasoning capability, yet existing methods treat all incorrect responses as equally informative, overlooking the crucial role of sample quality. To address this, we propose Plausible Negative Samples (PNS), a method that synthesizes high-quality negative samples exhibiting expected format and structural coherence while ultimately yielding incorrect answers. PNS trains a dedicated model via reverse reinforcement learning (RL) guided by a composite reward combining format compliance, accuracy inversion, reward model assessment, and chain-of-thought evaluation, generating responses nearly indistinguishable from correct solutions. We further validate PNS as a plug-and-play data source for preference optimization across three backbone models on seven mathematical reasoning benchmarks. Results demonstrate that PNS consistently outperforms other negative sample synthesis methods, achieving an average improvement of 2.03% over RL-trained models.
Qwen3-ASR Technical Report
Jan 29, 2026In this report, we introduce Qwen3-ASR family, which includes two powerful all-in-one speech recognition models and a novel non-autoregressive speech forced alignment model. Qwen3-ASR-1.7B and Qwen3-ASR-0.6B are ASR models that support language identification and ASR for 52 languages and dialects. Both of them leverage large-scale speech training data and the strong audio understanding ability of their foundation model Qwen3-Omni. We conduct comprehensive internal evaluation besides the open-sourced benchmarks as ASR models might differ little on open-sourced benchmark scores but exhibit significant quality differences in real-world scenarios. The experiments reveal that the 1.7B version achieves SOTA performance among open-sourced ASR models and is competitive with the strongest proprietary APIs while the 0.6B version offers the best accuracy-efficiency trade-off. Qwen3-ASR-0.6B can achieve an average TTFT as low as 92ms and transcribe 2000 seconds speech in 1 second at a concurrency of 128. Qwen3-ForcedAligner-0.6B is an LLM based NAR timestamp predictor that is able to align text-speech pairs in 11 languages. Timestamp accuracy experiments show that the proposed model outperforms the three strongest force alignment models and takes more advantages in efficiency and versatility. To further accelerate the community research of ASR and audio understanding, we release these models under the Apache 2.0 license.
From Atoms to Chains: Divergence-Guided Reasoning Curriculum for Unlabeled LLM Domain Adaptation
Jan 27, 2026Adapting Large Language Models (LLMs) to specialized domains without human-annotated data is a crucial yet formidable challenge. Widely adopted knowledge distillation methods often devolve into coarse-grained mimicry, where the student model inefficiently targets its own weaknesses and risks inheriting the teacher's reasoning flaws. This exposes a critical pedagogical dilemma: how to devise a reliable curriculum when the teacher itself is not an infallible expert. Our work resolves this by capitalizing on a key insight: while LLMs may exhibit fallibility in complex, holistic reasoning, they often exhibit high fidelity on focused, atomic sub-problems. Based on this, we propose Divergence-Guided Reasoning Curriculum (DGRC), which constructs a learning path from atomic knowledge to reasoning chains by dynamically deriving two complementary curricula from disagreements in reasoning pathways. When a student and teacher produce conflicting results, DGRC directs the teacher to perform a diagnostic analysis: it analyzes both reasoning paths to formulate atomic queries that target the specific points of divergence, and then self-answers these queries to create high-confidence atomic question-answer pairs. These pairs then serve a dual purpose: (1) providing an atomic curriculum to rectify the student's knowledge gaps, and (2) serving as factual criteria to filter the teacher's original reasoning chains, yielding a verified CoT curriculum that teaches the student how to integrate atomic knowledge into complete reasoning paths. Experiments across the medical and legal domains on student models of various sizes demonstrate the effectiveness of our DGRC framework. Notably, our method achieves a 7.76% relative improvement for the 1.5B student model in the medical domain over strong unlabeled baseline.
Structured Reasoning for Large Language Models
Jan 12, 2026Large language models (LLMs) achieve strong performance by generating long chains of thought, but longer traces always introduce redundant or ineffective reasoning steps. One typical behavior is that they often perform unnecessary verification and revisions even if they have reached the correct answers. This limitation stems from the unstructured nature of reasoning trajectories and the lack of targeted supervision for critical reasoning abilities. To address this, we propose Structured Reasoning (SCR), a framework that decouples reasoning trajectories into explicit, evaluable, and trainable components. We mainly implement SCR using a Generate-Verify-Revise paradigm. Specifically, we construct structured training data and apply Dynamic Termination Supervision to guide the model in deciding when to terminate reasoning. To avoid interference between learning signals for different reasoning abilities, we adopt a progressive two-stage reinforcement learning strategy: the first stage targets initial generation and self-verification, and the second stage focuses on revision. Extensive experiments on three backbone models show that SCR substantially improves reasoning efficiency and self-verification. Besides, compared with existing reasoning paradigms, it reduces output token length by up to 50%.
METOR: A Unified Framework for Mutual Enhancement of Objects and Relationships in Open-vocabulary Video Visual Relationship Detection
May 10, 2025Open-vocabulary video visual relationship detection aims to detect objects and their relationships in videos without being restricted by predefined object or relationship categories. Existing methods leverage the rich semantic knowledge of pre-trained vision-language models such as CLIP to identify novel categories. They typically adopt a cascaded pipeline to first detect objects and then classify relationships based on the detected objects, which may lead to error propagation and thus suboptimal performance. In this paper, we propose Mutual EnhancemenT of Objects and Relationships (METOR), a query-based unified framework to jointly model and mutually enhance object detection and relationship classification in open-vocabulary scenarios. Under this framework, we first design a CLIP-based contextual refinement encoding module that extracts visual contexts of objects and relationships to refine the encoding of text features and object queries, thus improving the generalization of encoding to novel categories. Then we propose an iterative enhancement module to alternatively enhance the representations of objects and relationships by fully exploiting their interdependence to improve recognition performance. Extensive experiments on two public datasets, VidVRD and VidOR, demonstrate that our framework achieves state-of-the-art performance.
Design of an Expression Recognition Solution Employing the Global Channel-Spatial Attention Mechanism
Mar 15, 2025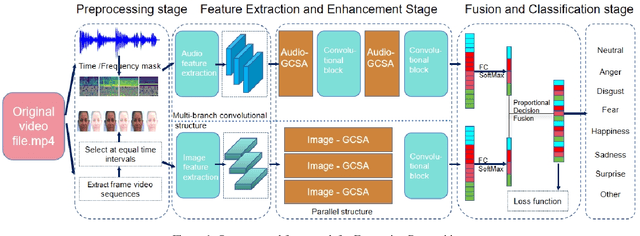
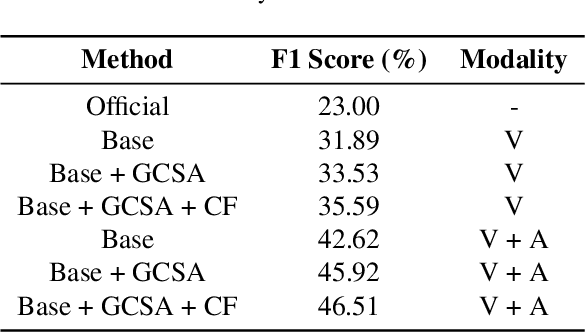
Facial expression recognition is a challenging classification task with broad application prospects in the field of human - computer interaction. This paper aims to introduce the methods of our upcoming 8th Affective Behavior Analysis in the Wild (ABAW) competition to be held at CVPR2025. To address issues such as low recognition accuracy caused by subtle expression changes and multi - scales in facial expression recognition in videos, we propose global channel - spatial attention and median - enhanced spatial - channel attention to strengthen feature processing for speech and images respectively. Secondly, to fully utilize the complementarity between the speech and facial expression modalities, a speech - and - facial - expression key - frame alignment technique is adopted to calculate the weights of speech and facial expressions. These weights are input into the feature fusion layer for multi - scale dilated fusion, which effectively improves the recognition rate of facial expression recognition. In the facial expression recognition task of the 6th ABAW competition, our method achieved excellent results on the official validation set, which fully demonstrates the effectiveness and competitiveness of the proposed method.
Solution for 8th Competition on Affective & Behavior Analysis in-the-wild
Mar 14, 2025In this report, we present our solution for the Action Unit (AU) Detection Challenge, in 8th Competition on Affective Behavior Analysis in-the-wild. In order to achieve robust and accurate classification of facial action unit in the wild environment, we introduce an innovative method that leverages audio-visual multimodal data. Our method employs ConvNeXt as the image encoder and uses Whisper to extract Mel spectrogram features. For these features, we utilize a Transformer encoder-based feature fusion module to integrate the affective information embedded in audio and image features. This ensures the provision of rich high-dimensional feature representations for the subsequent multilayer perceptron (MLP) trained on the Aff-Wild2 dataset, enhancing the accuracy of AU detection.
Interactive Multimodal Fusion with Temporal Modeling
Mar 13, 2025This paper presents our method for the estimation of valence-arousal (VA) in the 8th Affective Behavior Analysis in-the-Wild (ABAW) competition. Our approach integrates visual and audio information through a multimodal framework. The visual branch uses a pre-trained ResNet model to extract spatial features from facial images. The audio branches employ pre-trained VGG models to extract VGGish and LogMel features from speech signals. These features undergo temporal modeling using Temporal Convolutional Networks (TCNs). We then apply cross-modal attention mechanisms, where visual features interact with audio features through query-key-value attention structures. Finally, the features are concatenated and passed through a regression layer to predict valence and arousal. Our method achieves competitive performance on the Aff-Wild2 dataset, demonstrating effective multimodal fusion for VA estimation in-the-wild.
Dual-Stage Cross-Modal Network with Dynamic Feature Fusion for Emotional Mimicry Intensity Estimation
Mar 13, 2025Emotional Mimicry Intensity (EMI) estimation serves as a critical technology for understanding human social behavior and enhancing human-computer interaction experiences, where the core challenge lies in dynamic correlation modeling and robust fusion of multimodal temporal signals. To address the limitations of existing methods in insufficient exploitation of modal synergistic effects, noise sensitivity, and limited fine-grained alignment capabilities, this paper proposes a dual-stage cross-modal alignment framework. First, we construct vision-text and audio-text contrastive learning networks based on an improved CLIP architecture, achieving preliminary alignment in the feature space through modality-decoupled pre-training. Subsequently, we design a temporal-aware dynamic fusion module that combines Temporal Convolutional Networks (TCN) and gated bidirectional LSTM to respectively capture the macro-evolution patterns of facial expressions and local dynamics of acoustic features. Innovatively, we introduce a quality-guided modality fusion strategy that enables modality compensation under occlusion and noisy scenarios through differentiable weight allocation. Experimental results on the Hume-Vidmimic2 dataset demonstrate that our method achieves an average Pearson correlation coefficient of 0.35 across six emotion dimensions, outperforming the best baseline by 40\%. Ablation studies further validate the effectiveness of the dual-stage training strategy and dynamic fusion mechanism, providing a novel technical pathway for fine-grained emotion analysis in open environments.
MoMu-Diffusion: On Learning Long-Term Motion-Music Synchronization and Correspondence
Nov 04, 2024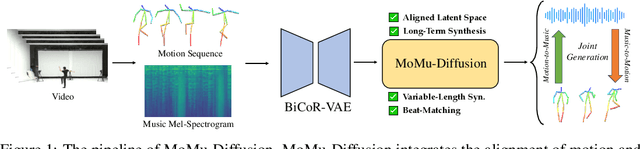

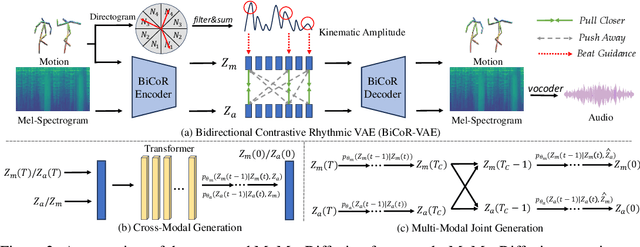
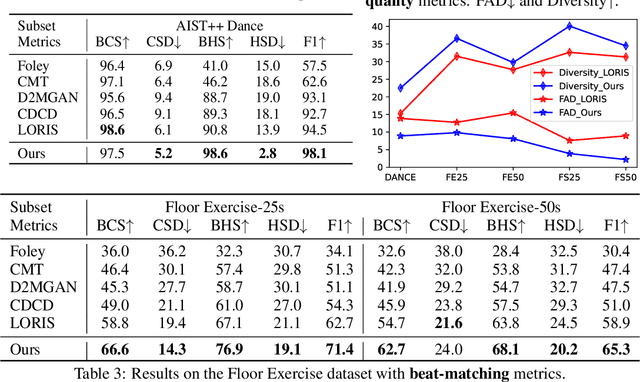
Motion-to-music and music-to-motion have been studied separately, each attracting substantial research interest within their respective domains. The interaction between human motion and music is a reflection of advanced human intelligence, and establishing a unified relationship between them is particularly important. However, to date, there has been no work that considers them jointly to explore the modality alignment within. To bridge this gap, we propose a novel framework, termed MoMu-Diffusion, for long-term and synchronous motion-music generation. Firstly, to mitigate the huge computational costs raised by long sequences, we propose a novel Bidirectional Contrastive Rhythmic Variational Auto-Encoder (BiCoR-VAE) that extracts the modality-aligned latent representations for both motion and music inputs. Subsequently, leveraging the aligned latent spaces, we introduce a multi-modal Transformer-based diffusion model and a cross-guidance sampling strategy to enable various generation tasks, including cross-modal, multi-modal, and variable-length generation. Extensive experiments demonstrate that MoMu-Diffusion surpasses recent state-of-the-art methods both qualitatively and quantitatively, and can synthesize realistic, diverse, long-term, and beat-matched music or motion sequences. The generated samples and codes are available at https://momu-diffusion.github.io/