 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign of an Expression Recognition Solution Employing the Global Channel-Spatial Attention Mechanism
Mar 15, 2025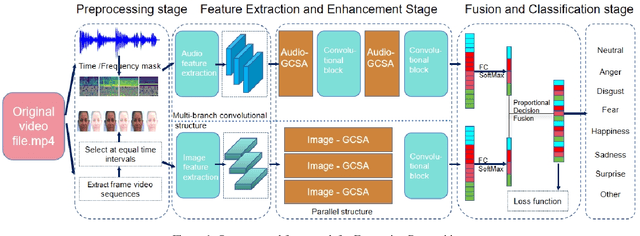
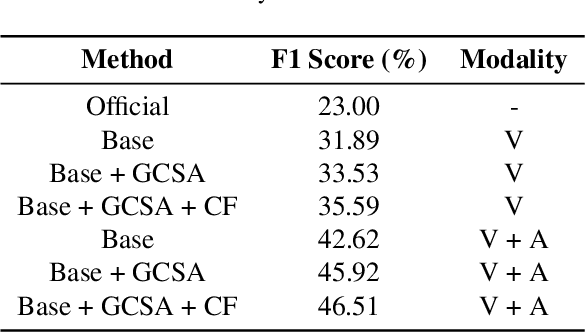
Facial expression recognition is a challenging classification task with broad application prospects in the field of human - computer interaction. This paper aims to introduce the methods of our upcoming 8th Affective Behavior Analysis in the Wild (ABAW) competition to be held at CVPR2025. To address issues such as low recognition accuracy caused by subtle expression changes and multi - scales in facial expression recognition in videos, we propose global channel - spatial attention and median - enhanced spatial - channel attention to strengthen feature processing for speech and images respectively. Secondly, to fully utilize the complementarity between the speech and facial expression modalities, a speech - and - facial - expression key - frame alignment technique is adopted to calculate the weights of speech and facial expressions. These weights are input into the feature fusion layer for multi - scale dilated fusion, which effectively improves the recognition rate of facial expression recognition. In the facial expression recognition task of the 6th ABAW competition, our method achieved excellent results on the official validation set, which fully demonstrates the effectiveness and competitiveness of the proposed method.
Interactive Multimodal Fusion with Temporal Modeling
Mar 13, 2025This paper presents our method for the estimation of valence-arousal (VA) in the 8th Affective Behavior Analysis in-the-Wild (ABAW) competition. Our approach integrates visual and audio information through a multimodal framework. The visual branch uses a pre-trained ResNet model to extract spatial features from facial images. The audio branches employ pre-trained VGG models to extract VGGish and LogMel features from speech signals. These features undergo temporal modeling using Temporal Convolutional Networks (TCNs). We then apply cross-modal attention mechanisms, where visual features interact with audio features through query-key-value attention structures. Finally, the features are concatenated and passed through a regression layer to predict valence and arousal. Our method achieves competitive performance on the Aff-Wild2 dataset, demonstrating effective multimodal fusion for VA estimation in-the-wild.