 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
Multi-cam Multi-map Visual Inertial Localization: System, Validation and Dataset
Dec 05, 2024



Map-based localization is crucial for the autonomous movement of robots as it provides real-time positional feedback. However, existing VINS and SLAM systems cannot be directly integrated into the robot's control loop. Although VINS offers high-frequency position estimates, it suffers from drift in long-term operation. And the drift-free trajectory output by SLAM is post-processed with loop correction, which is non-causal. In practical control, it is impossible to update the current pose with future information. Furthermore, existing SLAM evaluation systems measure accuracy after aligning the entire trajectory, which overlooks the transformation error between the odometry start frame and the ground truth frame. To address these issues, we propose a multi-cam multi-map visual inertial localization system, which provides real-time, causal and drift-free position feedback to the robot control loop. Additionally, we analyze the error composition of map-based localization systems and propose a set of evaluation metric suitable for measuring causal localization performance. To validate our system, we design a multi-camera IMU hardware setup and collect a long-term challenging campus dataset. Experimental results demonstrate the higher real-time localization accuracy of the proposed system. To foster community development, both the system and the dataset have been made open source https://github.com/zoeylove/Multi-cam-Multi-map-VILO/tree/main.
MoMu-Diffusion: On Learning Long-Term Motion-Music Synchronization and Correspondence
Nov 04, 2024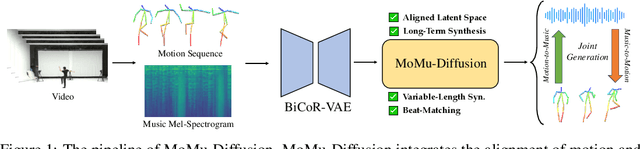

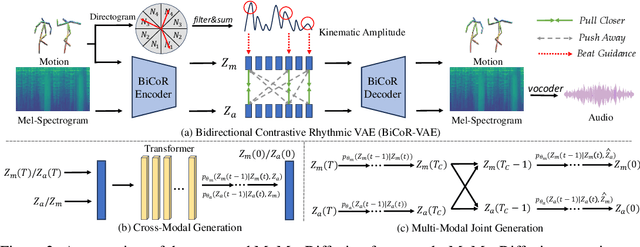
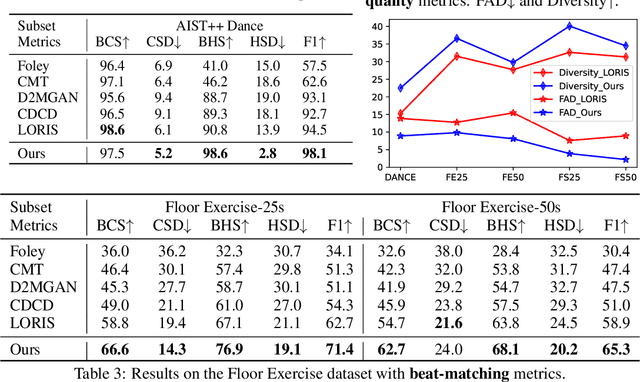
Motion-to-music and music-to-motion have been studied separately, each attracting substantial research interest within their respective domains. The interaction between human motion and music is a reflection of advanced human intelligence, and establishing a unified relationship between them is particularly important. However, to date, there has been no work that considers them jointly to explore the modality alignment within. To bridge this gap, we propose a novel framework, termed MoMu-Diffusion, for long-term and synchronous motion-music generation. Firstly, to mitigate the huge computational costs raised by long sequences, we propose a novel Bidirectional Contrastive Rhythmic Variational Auto-Encoder (BiCoR-VAE) that extracts the modality-aligned latent representations for both motion and music inputs. Subsequently, leveraging the aligned latent spaces, we introduce a multi-modal Transformer-based diffusion model and a cross-guidance sampling strategy to enable various generation tasks, including cross-modal, multi-modal, and variable-length generation. Extensive experiments demonstrate that MoMu-Diffusion surpasses recent state-of-the-art methods both qualitatively and quantitatively, and can synthesize realistic, diverse, long-term, and beat-matched music or motion sequences. The generated samples and codes are available at https://momu-diffusion.github.io/
Cross-modal Prompts: Adapting Large Pre-trained Models for Audio-Visual Downstream Tasks
Nov 09, 2023In recent years, the deployment of large-scale pre-trained models in audio-visual downstream tasks has yielded remarkable outcomes. However, these models, primarily trained on single-modality unconstrained datasets, still encounter challenges in feature extraction for multi-modal tasks, leading to suboptimal performance. This limitation arises due to the introduction of irrelevant modality-specific information during encoding, which adversely affects the performance of downstream tasks. To address this challenge, this paper proposes a novel Dual-Guided Spatial-Channel-Temporal (DG-SCT) attention mechanism. This mechanism leverages audio and visual modalities as soft prompts to dynamically adjust the parameters of pre-trained models based on the current multi-modal input features. Specifically, the DG-SCT module incorporates trainable cross-modal interaction layers into pre-trained audio-visual encoders, allowing adaptive extraction of crucial information from the current modality across spatial, channel, and temporal dimensions, while preserving the frozen parameters of large-scale pre-trained models. Experimental evaluations demonstrate that our proposed model achieves state-of-the-art results across multiple downstream tasks, including AVE, AVVP, AVS, and AVQA. Furthermore, our model exhibits promising performance in challenging few-shot and zero-shot scenarios. The source code and pre-trained models are available at https://github.com/haoyi-duan/DG-SCT.
Gloss Attention for Gloss-free Sign Language Translation
Jul 14, 2023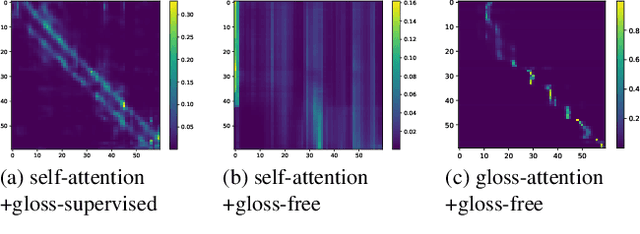
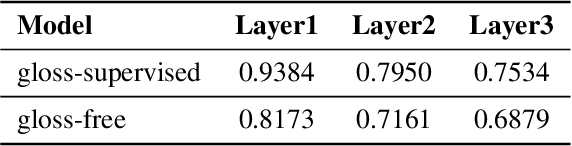

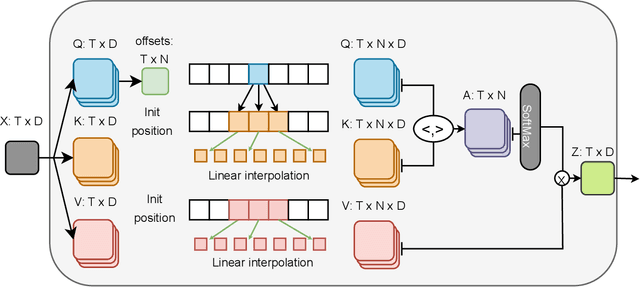
Most sign language translation (SLT) methods to date require the use of gloss annotations to provide additional supervision information, however, the acquisition of gloss is not easy. To solve this problem, we first perform an analysis of existing models to confirm how gloss annotations make SLT easier. We find that it can provide two aspects of information for the model, 1) it can help the model implicitly learn the location of semantic boundaries in continuous sign language videos, 2) it can help the model understand the sign language video globally. We then propose \emph{gloss attention}, which enables the model to keep its attention within video segments that have the same semantics locally, just as gloss helps existing models do. Furthermore, we transfer the knowledge of sentence-to-sentence similarity from the natural language model to our gloss attention SLT network (GASLT) to help it understand sign language videos at the sentence level. Experimental results on multiple large-scale sign language datasets show that our proposed GASLT model significantly outperforms existing methods. Our code is provided in \url{https://github.com/YinAoXiong/GASLT}.
Connecting Multi-modal Contrastive Representations
May 22, 2023Multi-modal Contrastive Representation (MCR) learning aims to encode different modalities into a semantically aligned shared space. This paradigm shows remarkable generalization ability on numerous downstream tasks across various modalities. However, the reliance on massive high-quality data pairs limits its further development on more modalities. This paper proposes a novel training-efficient method for learning MCR without paired data called Connecting Multi-modal Contrastive Representations (C-MCR). Specifically, given two existing MCRs pre-trained on (A, B) and (B, C) modality pairs, we project them to a new space and use the data from the overlapping modality B to aligning the two MCRs in the new space. Meanwhile, since the modality pairs (A, B) and (B, C) are already aligned within each MCR, the connection learned by overlapping modality can also be transferred to non-overlapping modality pair (A, C). To unleash the potential of C-MCR, we further introduce a semantic-enhanced inter- and intra-MCR connection method. We first enhance the semantic consistency and completion of embeddings across different modalities for more robust alignment. Then we utilize the inter-MCR alignment to establish the connection, and employ the intra-MCR alignment to better maintain the connection for inputs from non-overlapping modalities. We take the field of audio-visual contrastive learning as an example to demonstrate the effectiveness of C-MCR. We connect pre-trained CLIP and CLAP models via texts to derive audio-visual contrastive representations. Remarkably, without using any paired audio-visual data and further tuning, C-MCR achieves state-of-the-art performance on six datasets across three audio-visual downstream tasks.
Time Interval-enhanced Graph Neural Network for Shared-account Cross-domain Sequential Recommendation
Jun 16, 2022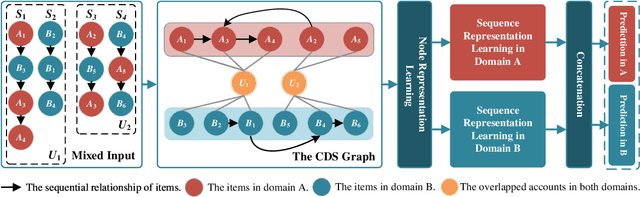
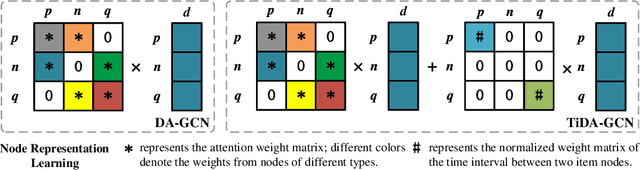
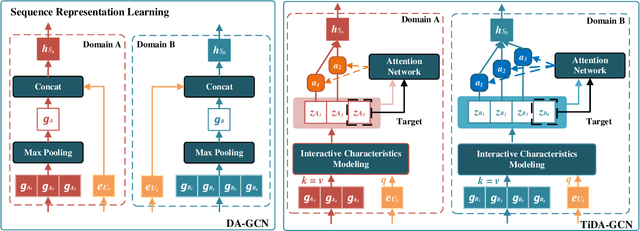
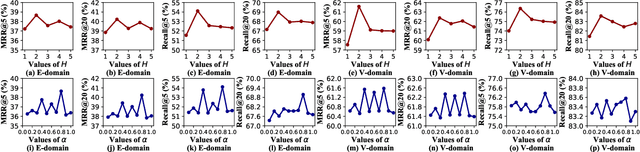
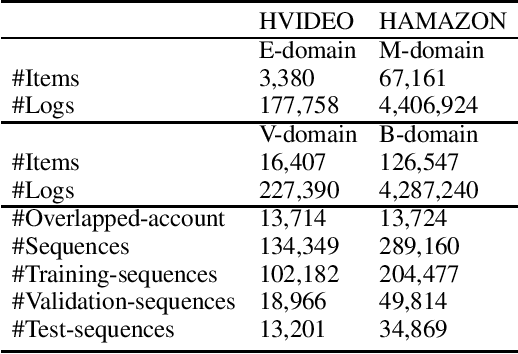
Shared-account Cross-domain Sequential Recommendation (SCSR) task aims to recommend the next item via leveraging the mixed user behaviors in multiple domains. It is gaining immense research attention as more and more users tend to sign up on different platforms and share accounts with others to access domain-specific services. Existing works on SCSR mainly rely on mining sequential patterns via Recurrent Neural Network (RNN)-based models, which suffer from the following limitations: 1) RNN-based methods overwhelmingly target discovering sequential dependencies in single-user behaviors. They are not expressive enough to capture the relationships among multiple entities in SCSR. 2) All existing methods bridge two domains via knowledge transfer in the latent space, and ignore the explicit cross-domain graph structure. 3) None existing studies consider the time interval information among items, which is essential in the sequential recommendation for characterizing different items and learning discriminative representations for them. In this work, we propose a new graph-based solution, namely TiDA-GCN, to address the above challenges. Specifically, we first link users and items in each domain as a graph. Then, we devise a domain-aware graph convolution network to learn userspecific node representations. To fully account for users' domainspecific preferences on items, two effective attention mechanisms are further developed to selectively guide the message passing process. Moreover, to further enhance item- and account-level representation learning, we incorporate the time interval into the message passing, and design an account-aware self-attention module for learning items' interactive characteristics. Experiments demonstrate the superiority of our proposed method from various aspects.
DA-GCN: A Domain-aware Attentive Graph Convolution Network for Shared-account Cross-domain Sequential Recommendation
May 07, 2021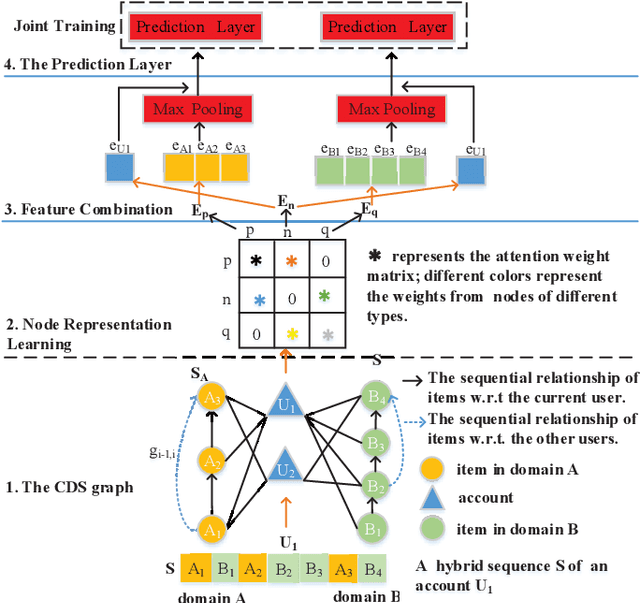

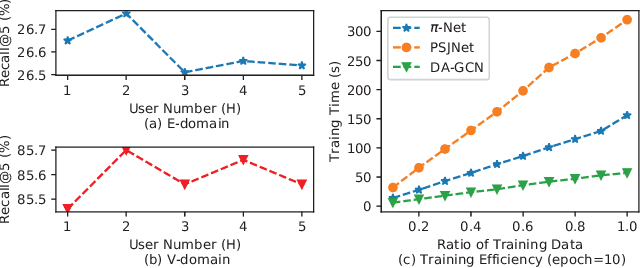
Shared-account Cross-domain Sequential recommendation (SCSR) is the task of recommending the next item based on a sequence of recorded user behaviors, where multiple users share a single account, and their behaviours are available in multiple domains. Existing work on solving SCSR mainly relies on mining sequential patterns via RNN-based models, which are not expressive enough to capture the relationships among multiple entities. Moreover, all existing algorithms try to bridge two domains via knowledge transfer in the latent space, and the explicit cross-domain graph structure is unexploited. In this work, we propose a novel graph-based solution, namely DA-GCN, to address the above challenges. Specifically, we first link users and items in each domain as a graph. Then, we devise a domain-aware graph convolution network to learn user-specific node representations. To fully account for users' domain-specific preferences on items, two novel attention mechanisms are further developed to selectively guide the message passing process. Extensive experiments on two real-world datasets are conducted to demonstrate the superiority of our DA-GCN method.
Improving the generalization of network based relative pose regression: dimension reduction as a regularizer
Oct 24, 2020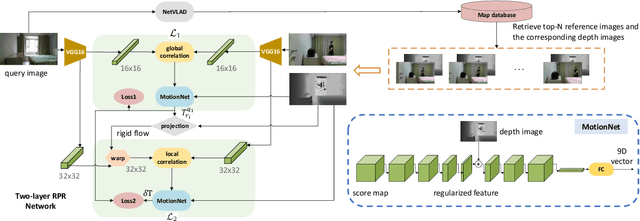
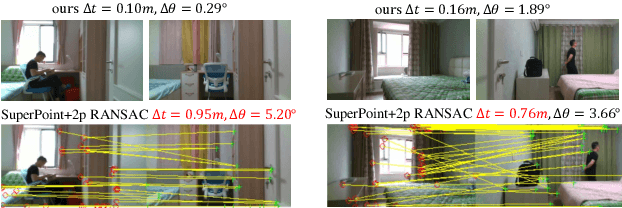
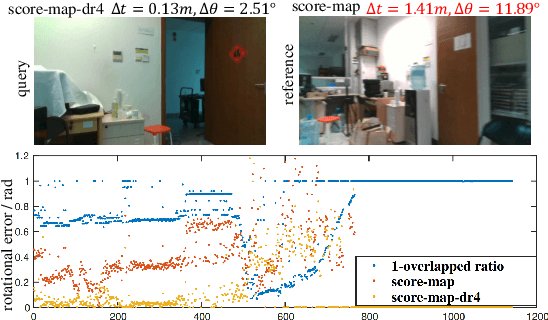

Visual localization occupies an important position in many areas such as Augmented Reality, robotics and 3D reconstruction. The state-of-the-art visual localization methods perform pose estimation using geometry based solver within the RANSAC framework. However, these methods require accurate pixel-level matching at high image resolution, which is hard to satisfy under significant changes from appearance, dynamics or perspective of view. End-to-end learning based regression networks provide a solution to circumvent the requirement for precise pixel-level correspondences, but demonstrate poor performance towards cross-scene generalization. In this paper, we explicitly add a learnable matching layer within the network to isolate the pose regression solver from the absolute image feature values, and apply dimension regularization on both the correlation feature channel and the image scale to further improve performance towards generalization and large viewpoint change. We implement this dimension regularization strategy within a two-layer pyramid based framework to regress the localization results from coarse to fine. In addition, the depth information is fused for absolute translational scale recovery. Through experiments on real world RGBD datasets we validate the effectiveness of our design in terms of improving both generalization performance and robustness towards viewpoint change, and also show the potential of regression based visual localization networks towards challenging occasions that are difficult for geometry based visual localization methods.