 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFADA: Fast Diffusion Avatar Synthesis with Mixed-Supervised Multi-CFG Distillation
Dec 22, 2024



Diffusion-based audio-driven talking avatar methods have recently gained attention for their high-fidelity, vivid, and expressive results. However, their slow inference speed limits practical applications. Despite the development of various distillation techniques for diffusion models, we found that naive diffusion distillation methods do not yield satisfactory results. Distilled models exhibit reduced robustness with open-set input images and a decreased correlation between audio and video compared to teacher models, undermining the advantages of diffusion models. To address this, we propose FADA (Fast Diffusion Avatar Synthesis with Mixed-Supervised Multi-CFG Distillation). We first designed a mixed-supervised loss to leverage data of varying quality and enhance the overall model capability as well as robustness. Additionally, we propose a multi-CFG distillation with learnable tokens to utilize the correlation between audio and reference image conditions, reducing the threefold inference runs caused by multi-CFG with acceptable quality degradation. Extensive experiments across multiple datasets show that FADA generates vivid videos comparable to recent diffusion model-based methods while achieving an NFE speedup of 4.17-12.5 times. Demos are available at our webpage http://fadavatar.github.io.
MimicTalk: Mimicking a personalized and expressive 3D talking face in minutes
Oct 09, 2024



Talking face generation (TFG) aims to animate a target identity's face to create realistic talking videos. Personalized TFG is a variant that emphasizes the perceptual identity similarity of the synthesized result (from the perspective of appearance and talking style). While previous works typically solve this problem by learning an individual neural radiance field (NeRF) for each identity to implicitly store its static and dynamic information, we find it inefficient and non-generalized due to the per-identity-per-training framework and the limited training data. To this end, we propose MimicTalk, the first attempt that exploits the rich knowledge from a NeRF-based person-agnostic generic model for improving the efficiency and robustness of personalized TFG. To be specific, (1) we first come up with a person-agnostic 3D TFG model as the base model and propose to adapt it into a specific identity; (2) we propose a static-dynamic-hybrid adaptation pipeline to help the model learn the personalized static appearance and facial dynamic features; (3) To generate the facial motion of the personalized talking style, we propose an in-context stylized audio-to-motion model that mimics the implicit talking style provided in the reference video without information loss by an explicit style representation. The adaptation process to an unseen identity can be performed in 15 minutes, which is 47 times faster than previous person-dependent methods. Experiments show that our MimicTalk surpasses previous baselines regarding video quality, efficiency, and expressiveness. Source code and video samples are available at https://mimictalk.github.io .
Loopy: Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency
Sep 04, 2024With the introduction of diffusion-based video generation techniques, audio-conditioned human video generation has recently achieved significant breakthroughs in both the naturalness of motion and the synthesis of portrait details. Due to the limited control of audio signals in driving human motion, existing methods often add auxiliary spatial signals to stabilize movements, which may compromise the naturalness and freedom of motion. In this paper, we propose an end-to-end audio-only conditioned video diffusion model named Loopy. Specifically, we designed an inter- and intra-clip temporal module and an audio-to-latents module, enabling the model to leverage long-term motion information from the data to learn natural motion patterns and improving audio-portrait movement correlation. This method removes the need for manually specified spatial motion templates used in existing methods to constrain motion during inference. Extensive experiments show that Loopy outperforms recent audio-driven portrait diffusion models, delivering more lifelike and high-quality results across various scenarios.
CyberHost: Taming Audio-driven Avatar Diffusion Model with Region Codebook Attention
Sep 03, 2024



Diffusion-based video generation technology has advanced significantly, catalyzing a proliferation of research in human animation. However, the majority of these studies are confined to same-modality driving settings, with cross-modality human body animation remaining relatively underexplored. In this paper, we introduce, an end-to-end audio-driven human animation framework that ensures hand integrity, identity consistency, and natural motion. The key design of CyberHost is the Region Codebook Attention mechanism, which improves the generation quality of facial and hand animations by integrating fine-grained local features with learned motion pattern priors. Furthermore, we have developed a suite of human-prior-guided training strategies, including body movement map, hand clarity score, pose-aligned reference feature, and local enhancement supervision, to improve synthesis results. To our knowledge, CyberHost is the first end-to-end audio-driven human diffusion model capable of facilitating zero-shot video generation within the scope of human body. Extensive experiments demonstrate that CyberHost surpasses previous works in both quantitative and qualitative aspects.
MobilePortrait: Real-Time One-Shot Neural Head Avatars on Mobile Devices
Jul 08, 2024
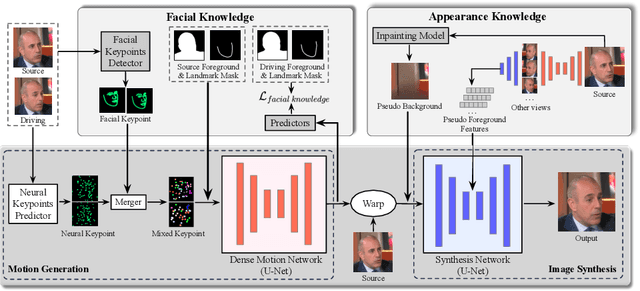


Existing neural head avatars methods have achieved significant progress in the image quality and motion range of portrait animation. However, these methods neglect the computational overhead, and to the best of our knowledge, none is designed to run on mobile devices. This paper presents MobilePortrait, a lightweight one-shot neural head avatars method that reduces learning complexity by integrating external knowledge into both the motion modeling and image synthesis, enabling real-time inference on mobile devices. Specifically, we introduce a mixed representation of explicit and implicit keypoints for precise motion modeling and precomputed visual features for enhanced foreground and background synthesis. With these two key designs and using simple U-Nets as backbones, our method achieves state-of-the-art performance with less than one-tenth the computational demand. It has been validated to reach speeds of over 100 FPS on mobile devices and support both video and audio-driven inputs.
Superior and Pragmatic Talking Face Generation with Teacher-Student Framework
Mar 26, 2024Talking face generation technology creates talking videos from arbitrary appearance and motion signal, with the "arbitrary" offering ease of use but also introducing challenges in practical applications. Existing methods work well with standard inputs but suffer serious performance degradation with intricate real-world ones. Moreover, efficiency is also an important concern in deployment. To comprehensively address these issues, we introduce SuperFace, a teacher-student framework that balances quality, robustness, cost and editability. We first propose a simple but effective teacher model capable of handling inputs of varying qualities to generate high-quality results. Building on this, we devise an efficient distillation strategy to acquire an identity-specific student model that maintains quality with significantly reduced computational load. Our experiments validate that SuperFace offers a more comprehensive solution than existing methods for the four mentioned objectives, especially in reducing FLOPs by 99\% with the student model. SuperFace can be driven by both video and audio and allows for localized facial attributes editing.
Real3D-Portrait: One-shot Realistic 3D Talking Portrait Synthesis
Jan 20, 2024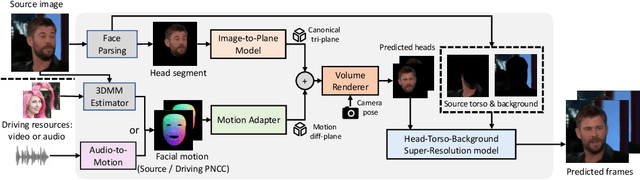

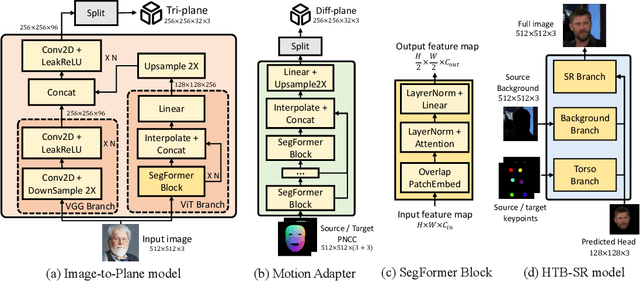
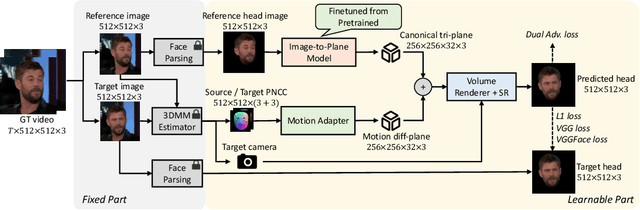
One-shot 3D talking portrait generation aims to reconstruct a 3D avatar from an unseen image, and then animate it with a reference video or audio to generate a talking portrait video. The existing methods fail to simultaneously achieve the goals of accurate 3D avatar reconstruction and stable talking face animation. Besides, while the existing works mainly focus on synthesizing the head part, it is also vital to generate natural torso and background segments to obtain a realistic talking portrait video. To address these limitations, we present Real3D-Potrait, a framework that (1) improves the one-shot 3D reconstruction power with a large image-to-plane model that distills 3D prior knowledge from a 3D face generative model; (2) facilitates accurate motion-conditioned animation with an efficient motion adapter; (3) synthesizes realistic video with natural torso movement and switchable background using a head-torso-background super-resolution model; and (4) supports one-shot audio-driven talking face generation with a generalizable audio-to-motion model. Extensive experiments show that Real3D-Portrait generalizes well to unseen identities and generates more realistic talking portrait videos compared to previous methods. Video samples and source code are available at https://real3dportrait.github.io .
Language Model is a Branch Predictor for Simultaneous Machine Translation
Dec 22, 2023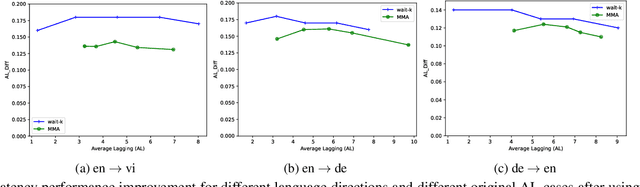

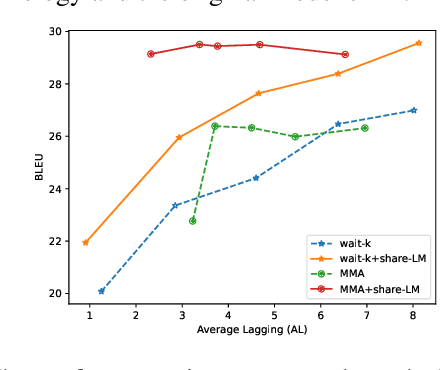

The primary objective of simultaneous machine translation (SiMT) is to minimize latency while preserving the quality of the final translation. Drawing inspiration from CPU branch prediction techniques, we propose incorporating branch prediction techniques in SiMT tasks to reduce translation latency. Specifically, we utilize a language model as a branch predictor to predict potential branch directions, namely, future source words. Subsequently, we utilize the predicted source words to decode the output in advance. When the actual source word deviates from the predicted source word, we use the real source word to decode the output again, replacing the predicted output. To further reduce computational costs, we share the parameters of the encoder and the branch predictor, and utilize a pre-trained language model for initialization. Our proposed method can be seamlessly integrated with any SiMT model. Extensive experimental results demonstrate that our approach can improve translation quality and latency at the same time. Our code is available at https://github.com/YinAoXiong/simt_branch_predictor .
Gloss Attention for Gloss-free Sign Language Translation
Jul 14, 2023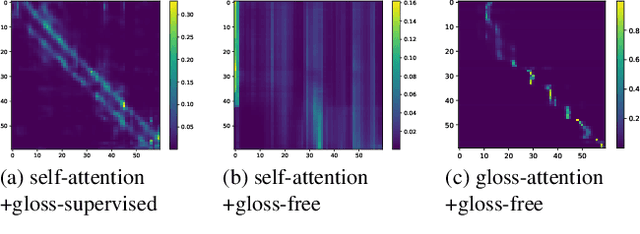
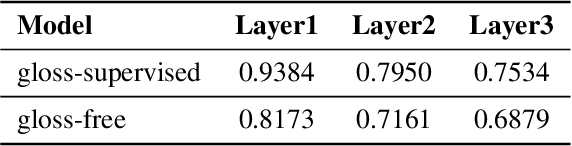

Most sign language translation (SLT) methods to date require the use of gloss annotations to provide additional supervision information, however, the acquisition of gloss is not easy. To solve this problem, we first perform an analysis of existing models to confirm how gloss annotations make SLT easier. We find that it can provide two aspects of information for the model, 1) it can help the model implicitly learn the location of semantic boundaries in continuous sign language videos, 2) it can help the model understand the sign language video globally. We then propose \emph{gloss attention}, which enables the model to keep its attention within video segments that have the same semantics locally, just as gloss helps existing models do. Furthermore, we transfer the knowledge of sentence-to-sentence similarity from the natural language model to our gloss attention SLT network (GASLT) to help it understand sign language videos at the sentence level. Experimental results on multiple large-scale sign language datasets show that our proposed GASLT model significantly outperforms existing methods. Our code is provided in \url{https://github.com/YinAoXiong/GASLT}.