 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-Captioner: Data Pipeline, Models, and Benchmark for Omni Detailed Perception
Oct 14, 2025Fine-grained perception of multimodal information is critical for advancing human-AI interaction. With recent progress in audio-visual technologies, Omni Language Models (OLMs), capable of processing audio and video signals in parallel, have emerged as a promising paradigm for achieving richer understanding and reasoning. However, their capacity to capture and describe fine-grained details remains limited explored. In this work, we present a systematic and comprehensive investigation of omni detailed perception from the perspectives of the data pipeline, models, and benchmark. We first identify an inherent "co-growth" between detail and hallucination in current OLMs. To address this, we propose Omni-Detective, an agentic data generation pipeline integrating tool-calling, to autonomously produce highly detailed yet minimally hallucinatory multimodal data. Based on the data generated with Omni-Detective, we train two captioning models: Audio-Captioner for audio-only detailed perception, and Omni-Captioner for audio-visual detailed perception. Under the cascade evaluation protocol, Audio-Captioner achieves the best performance on MMAU and MMAR among all open-source models, surpassing Gemini 2.5 Flash and delivering performance comparable to Gemini 2.5 Pro. On existing detailed captioning benchmarks, Omni-Captioner sets a new state-of-the-art on VDC and achieves the best trade-off between detail and hallucination on the video-SALMONN 2 testset. Given the absence of a dedicated benchmark for omni detailed perception, we design Omni-Cloze, a novel cloze-style evaluation for detailed audio, visual, and audio-visual captioning that ensures stable, efficient, and reliable assessment. Experimental results and analysis demonstrate the effectiveness of Omni-Detective in generating high-quality detailed captions, as well as the superiority of Omni-Cloze in evaluating such detailed captions.
WavReward: Spoken Dialogue Models With Generalist Reward Evaluators
May 14, 2025End-to-end spoken dialogue models such as GPT-4o-audio have recently garnered significant attention in the speech domain. However, the evaluation of spoken dialogue models' conversational performance has largely been overlooked. This is primarily due to the intelligent chatbots convey a wealth of non-textual information which cannot be easily measured using text-based language models like ChatGPT. To address this gap, we propose WavReward, a reward feedback model based on audio language models that can evaluate both the IQ and EQ of spoken dialogue systems with speech input. Specifically, 1) based on audio language models, WavReward incorporates the deep reasoning process and the nonlinear reward mechanism for post-training. By utilizing multi-sample feedback via the reinforcement learning algorithm, we construct a specialized evaluator tailored to spoken dialogue models. 2) We introduce ChatReward-30K, a preference dataset used to train WavReward. ChatReward-30K includes both comprehension and generation aspects of spoken dialogue models. These scenarios span various tasks, such as text-based chats, nine acoustic attributes of instruction chats, and implicit chats. WavReward outperforms previous state-of-the-art evaluation models across multiple spoken dialogue scenarios, achieving a substantial improvement about Qwen2.5-Omni in objective accuracy from 55.1$\%$ to 91.5$\%$. In subjective A/B testing, WavReward also leads by a margin of 83$\%$. Comprehensive ablation studies confirm the necessity of each component of WavReward. All data and code will be publicly at https://github.com/jishengpeng/WavReward after the paper is accepted.
Qwen2.5-Omni Technical Report
Mar 26, 2025



In this report, we present Qwen2.5-Omni, an end-to-end multimodal model designed to perceive diverse modalities, including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner. To enable the streaming of multimodal information inputs, both audio and visual encoders utilize a block-wise processing approach. To synchronize the timestamps of video inputs with audio, we organize the audio and video sequentially in an interleaved manner and propose a novel position embedding approach, named TMRoPE(Time-aligned Multimodal RoPE). To concurrently generate text and speech while avoiding interference between the two modalities, we propose \textbf{Thinker-Talker} architecture. In this framework, Thinker functions as a large language model tasked with text generation, while Talker is a dual-track autoregressive model that directly utilizes the hidden representations from the Thinker to produce audio tokens as output. Both the Thinker and Talker models are designed to be trained and inferred in an end-to-end manner. For decoding audio tokens in a streaming manner, we introduce a sliding-window DiT that restricts the receptive field, aiming to reduce the initial package delay. Qwen2.5-Omni is comparable with the similarly sized Qwen2.5-VL and outperforms Qwen2-Audio. Furthermore, Qwen2.5-Omni achieves state-of-the-art performance on multimodal benchmarks like Omni-Bench. Notably, Qwen2.5-Omni's performance in end-to-end speech instruction following is comparable to its capabilities with text inputs, as evidenced by benchmarks such as MMLU and GSM8K. As for speech generation, Qwen2.5-Omni's streaming Talker outperforms most existing streaming and non-streaming alternatives in robustness and naturalness.
WavRAG: Audio-Integrated Retrieval Augmented Generation for Spoken Dialogue Models
Feb 20, 2025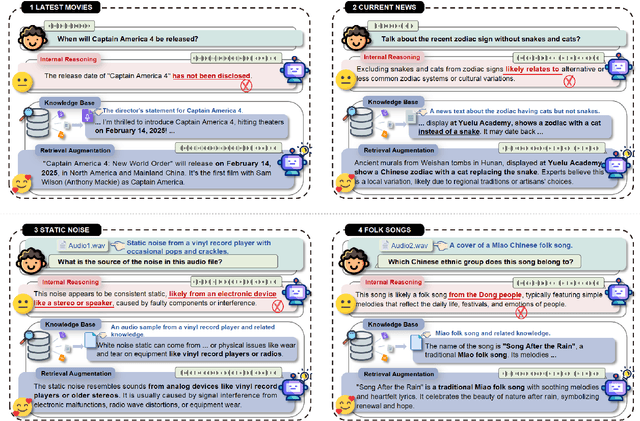
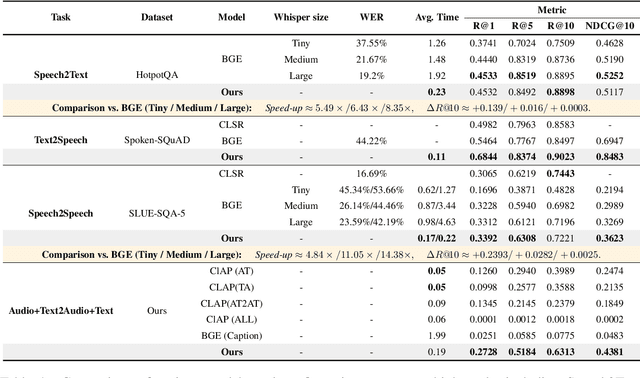
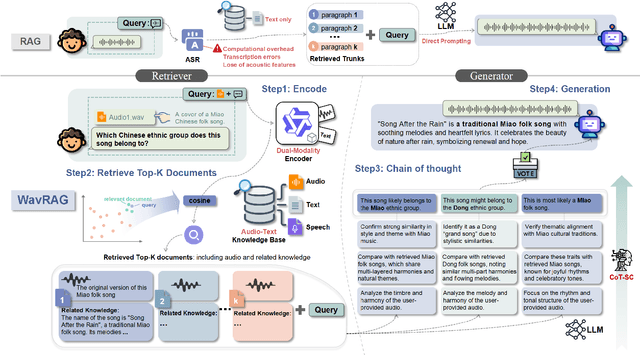
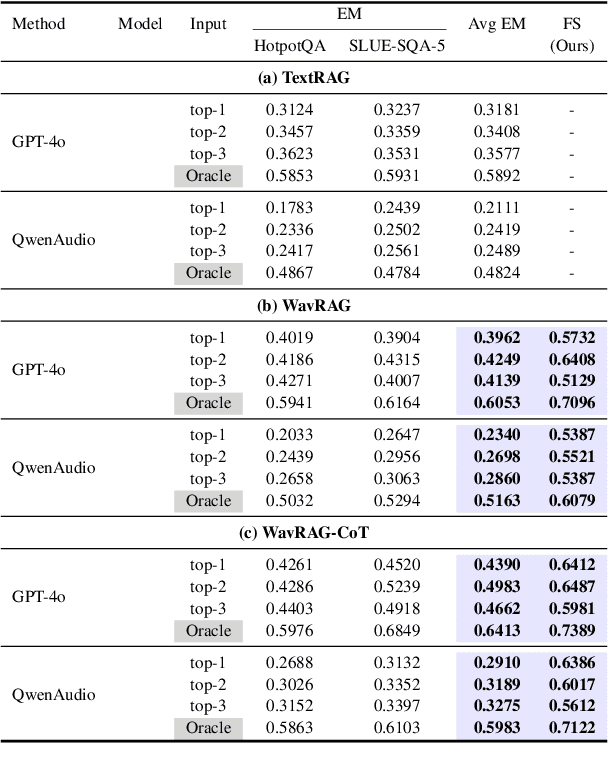
Retrieval Augmented Generation (RAG) has gained widespread adoption owing to its capacity to empower large language models (LLMs) to integrate external knowledge. However, existing RAG frameworks are primarily designed for text-based LLMs and rely on Automatic Speech Recognition to process speech input, which discards crucial audio information, risks transcription errors, and increases computational overhead. Therefore, we introduce WavRAG, the first retrieval augmented generation framework with native, end-to-end audio support. WavRAG offers two key features: 1) Bypassing ASR, WavRAG directly processes raw audio for both embedding and retrieval. 2) WavRAG integrates audio and text into a unified knowledge representation. Specifically, we propose the WavRetriever to facilitate the retrieval from a text-audio hybrid knowledge base, and further enhance the in-context capabilities of spoken dialogue models through the integration of chain-of-thought reasoning. In comparison to state-of-the-art ASR-Text RAG pipelines, WavRAG achieves comparable retrieval performance while delivering a 10x acceleration. Furthermore, WavRAG's unique text-audio hybrid retrieval capability extends the boundaries of RAG to the audio modality.
MimicTalk: Mimicking a personalized and expressive 3D talking face in minutes
Oct 09, 2024



Talking face generation (TFG) aims to animate a target identity's face to create realistic talking videos. Personalized TFG is a variant that emphasizes the perceptual identity similarity of the synthesized result (from the perspective of appearance and talking style). While previous works typically solve this problem by learning an individual neural radiance field (NeRF) for each identity to implicitly store its static and dynamic information, we find it inefficient and non-generalized due to the per-identity-per-training framework and the limited training data. To this end, we propose MimicTalk, the first attempt that exploits the rich knowledge from a NeRF-based person-agnostic generic model for improving the efficiency and robustness of personalized TFG. To be specific, (1) we first come up with a person-agnostic 3D TFG model as the base model and propose to adapt it into a specific identity; (2) we propose a static-dynamic-hybrid adaptation pipeline to help the model learn the personalized static appearance and facial dynamic features; (3) To generate the facial motion of the personalized talking style, we propose an in-context stylized audio-to-motion model that mimics the implicit talking style provided in the reference video without information loss by an explicit style representation. The adaptation process to an unseen identity can be performed in 15 minutes, which is 47 times faster than previous person-dependent methods. Experiments show that our MimicTalk surpasses previous baselines regarding video quality, efficiency, and expressiveness. Source code and video samples are available at https://mimictalk.github.io .
TCSinger: Zero-Shot Singing Voice Synthesis with Style Transfer and Multi-Level Style Control
Sep 26, 2024



Zero-shot singing voice synthesis (SVS) with style transfer and style control aims to generate high-quality singing voices with unseen timbres and styles (including singing method, emotion, rhythm, technique, and pronunciation) from audio and text prompts. However, the multifaceted nature of singing styles poses a significant challenge for effective modeling, transfer, and control. Furthermore, current SVS models often fail to generate singing voices rich in stylistic nuances for unseen singers. To address these challenges, we introduce TCSinger, the first zero-shot SVS model for style transfer across cross-lingual speech and singing styles, along with multi-level style control. Specifically, TCSinger proposes three primary modules: 1) the clustering style encoder employs a clustering vector quantization model to stably condense style information into a compact latent space; 2) the Style and Duration Language Model (S\&D-LM) concurrently predicts style information and phoneme duration, which benefits both; 3) the style adaptive decoder uses a novel mel-style adaptive normalization method to generate singing voices with enhanced details. Experimental results show that TCSinger outperforms all baseline models in synthesis quality, singer similarity, and style controllability across various tasks, including zero-shot style transfer, multi-level style control, cross-lingual style transfer, and speech-to-singing style transfer. Singing voice samples can be accessed at https://tcsinger.github.io/.
GTSinger: A Global Multi-Technique Singing Corpus with Realistic Music Scores for All Singing Tasks
Sep 26, 2024



The scarcity of high-quality and multi-task singing datasets significantly hinders the development of diverse controllable and personalized singing tasks, as existing singing datasets suffer from low quality, limited diversity of languages and singers, absence of multi-technique information and realistic music scores, and poor task suitability. To tackle these problems, we present GTSinger, a large global, multi-technique, free-to-use, high-quality singing corpus with realistic music scores, designed for all singing tasks, along with its benchmarks. Particularly, (1) we collect 80.59 hours of high-quality singing voices, forming the largest recorded singing dataset; (2) 20 professional singers across nine widely spoken languages offer diverse timbres and styles; (3) we provide controlled comparison and phoneme-level annotations of six commonly used singing techniques, helping technique modeling and control; (4) GTSinger offers realistic music scores, assisting real-world musical composition; (5) singing voices are accompanied by manual phoneme-to-audio alignments, global style labels, and 16.16 hours of paired speech for various singing tasks. Moreover, to facilitate the use of GTSinger, we conduct four benchmark experiments: technique-controllable singing voice synthesis, technique recognition, style transfer, and speech-to-singing conversion. The corpus and demos can be found at http://gtsinger.github.io. We provide the dataset and the code for processing data and conducting benchmarks at https://huggingface.co/datasets/GTSinger/GTSinger and https://github.com/GTSinger/GTSinger.
SongTrans: An unified song transcription and alignment method for lyrics and notes
Sep 22, 2024



The quantity of processed data is crucial for advancing the field of singing voice synthesis. While there are tools available for lyric or note transcription tasks, they all need pre-processed data which is relatively time-consuming (e.g., vocal and accompaniment separation). Besides, most of these tools are designed to address a single task and struggle with aligning lyrics and notes (i.e., identifying the corresponding notes of each word in lyrics). To address those challenges, we first design a pipeline by optimizing existing tools and annotating numerous lyric-note pairs of songs. Then, based on the annotated data, we train a unified SongTrans model that can directly transcribe lyrics and notes while aligning them simultaneously, without requiring pre-processing songs. Our SongTrans model consists of two modules: (1) the \textbf{Autoregressive module} predicts the lyrics, along with the duration and note number corresponding to each word in a lyric. (2) the \textbf{Non-autoregressive module} predicts the pitch and duration of the notes. Our experiments demonstrate that SongTrans achieves state-of-the-art (SOTA) results in both lyric and note transcription tasks. Furthermore, it is the first model capable of aligning lyrics with notes. Experimental results demonstrate that the SongTrans model can effectively adapt to different types of songs (e.g., songs with accompaniment), showcasing its versatility for real-world applications.
MulliVC: Multi-lingual Voice Conversion With Cycle Consistency
Aug 08, 2024Voice conversion aims to modify the source speaker's voice to resemble the target speaker while preserving the original speech content. Despite notable advancements in voice conversion these days, multi-lingual voice conversion (including both monolingual and cross-lingual scenarios) has yet to be extensively studied. It faces two main challenges: 1) the considerable variability in prosody and articulation habits across languages; and 2) the rarity of paired multi-lingual datasets from the same speaker. In this paper, we propose MulliVC, a novel voice conversion system that only converts timbre and keeps original content and source language prosody without multi-lingual paired data. Specifically, each training step of MulliVC contains three substeps: In step one the model is trained with monolingual speech data; then, steps two and three take inspiration from back translation, construct a cyclical process to disentangle the timbre and other information (content, prosody, and other language-related information) in the absence of multi-lingual data from the same speaker. Both objective and subjective results indicate that MulliVC significantly surpasses other methods in both monolingual and cross-lingual contexts, demonstrating the system's efficacy and the viability of the three-step approach with cycle consistency. Audio samples can be found on our demo page (mullivc.github.io).
Qwen2 Technical Report
Jul 16, 2024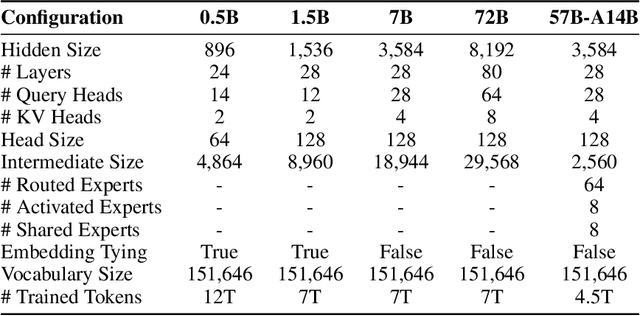
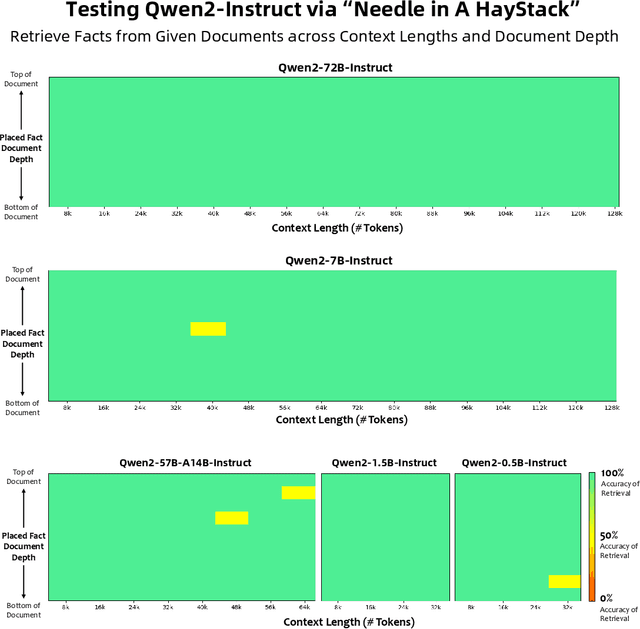
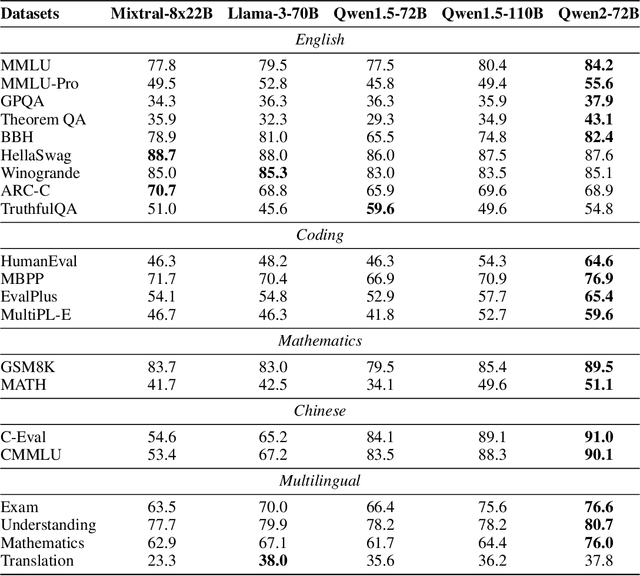
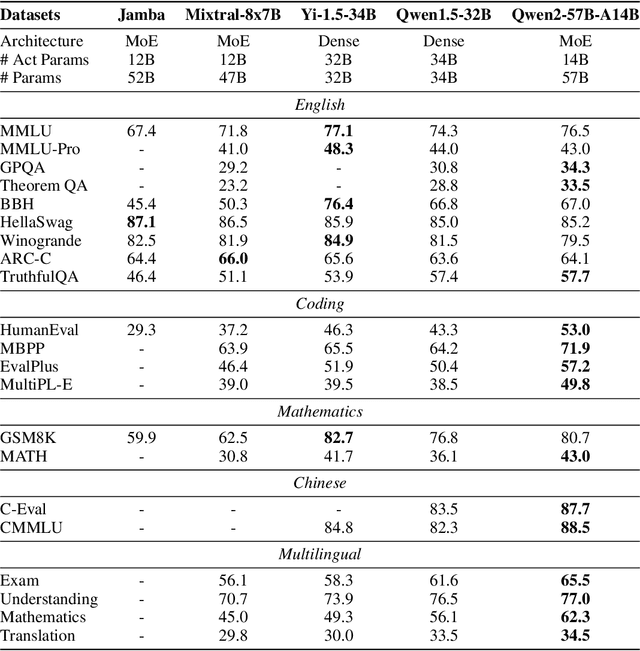
This report introduces the Qwen2 series, the latest addition to our large language models and large multimodal models. We release a comprehensive suite of foundational and instruction-tuned language models, encompassing a parameter range from 0.5 to 72 billion, featuring dense models and a Mixture-of-Experts model. Qwen2 surpasses most prior open-weight models, including its predecessor Qwen1.5, and exhibits competitive performance relative to proprietary models across diverse benchmarks on language understanding, generation, multilingual proficiency, coding, mathematics, and reasoning. The flagship model, Qwen2-72B, showcases remarkable performance: 84.2 on MMLU, 37.9 on GPQA, 64.6 on HumanEval, 89.5 on GSM8K, and 82.4 on BBH as a base language model. The instruction-tuned variant, Qwen2-72B-Instruct, attains 9.1 on MT-Bench, 48.1 on Arena-Hard, and 35.7 on LiveCodeBench. Moreover, Qwen2 demonstrates robust multilingual capabilities, proficient in approximately 30 languages, spanning English, Chinese, Spanish, French, German, Arabic, Russian, Korean, Japanese, Thai, Vietnamese, and more, underscoring its versatility and global reach. To foster community innovation and accessibility, we have made the Qwen2 model weights openly available on Hugging Face and ModelScope, and the supplementary materials including example code on GitHub. These platforms also include resources for quantization, fine-tuning, and deployment, facilitating a wide range of applications and research endeavors.