 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCP-ITP: An Automated Framework for Implicit Tool Poisoning in MCP
Jan 12, 2026To standardize interactions between LLM-based agents and their environments, the Model Context Protocol (MCP) was proposed and has since been widely adopted. However, integrating external tools expands the attack surface, exposing agents to tool poisoning attacks. In such attacks, malicious instructions embedded in tool metadata are injected into the agent context during MCP registration phase, thereby manipulating agent behavior. Prior work primarily focuses on explicit tool poisoning or relied on manually crafted poisoned tools. In contrast, we focus on a particularly stealthy variant: implicit tool poisoning, where the poisoned tool itself remains uninvoked. Instead, the instructions embedded in the tool metadata induce the agent to invoke a legitimate but high-privilege tool to perform malicious operations. We propose MCP-ITP, the first automated and adaptive framework for implicit tool poisoning within the MCP ecosystem. MCP-ITP formulates poisoned tool generation as a black-box optimization problem and employs an iterative optimization strategy that leverages feedback from both an evaluation LLM and a detection LLM to maximize Attack Success Rate (ASR) while evading current detection mechanisms. Experimental results on the MCPTox dataset across 12 LLM agents demonstrate that MCP-ITP consistently outperforms the manually crafted baseline, achieving up to 84.2% ASR while suppressing the Malicious Tool Detection Rate (MDR) to as low as 0.3%.
STARS: A Unified Framework for Singing Transcription, Alignment, and Refined Style Annotation
Jul 09, 2025Recent breakthroughs in singing voice synthesis (SVS) have heightened the demand for high-quality annotated datasets, yet manual annotation remains prohibitively labor-intensive and resource-intensive. Existing automatic singing annotation (ASA) methods, however, primarily tackle isolated aspects of the annotation pipeline. To address this fundamental challenge, we present STARS, which is, to our knowledge, the first unified framework that simultaneously addresses singing transcription, alignment, and refined style annotation. Our framework delivers comprehensive multi-level annotations encompassing: (1) precise phoneme-audio alignment, (2) robust note transcription and temporal localization, (3) expressive vocal technique identification, and (4) global stylistic characterization including emotion and pace. The proposed architecture employs hierarchical acoustic feature processing across frame, word, phoneme, note, and sentence levels. The novel non-autoregressive local acoustic encoders enable structured hierarchical representation learning. Experimental validation confirms the framework's superior performance across multiple evaluation dimensions compared to existing annotation approaches. Furthermore, applications in SVS training demonstrate that models utilizing STARS-annotated data achieve significantly enhanced perceptual naturalness and precise style control. This work not only overcomes critical scalability challenges in the creation of singing datasets but also pioneers new methodologies for controllable singing voice synthesis. Audio samples are available at https://gwx314.github.io/stars-demo/.
Versatile Framework for Song Generation with Prompt-based Control
Apr 29, 2025Song generation focuses on producing controllable high-quality songs based on various prompts. However, existing methods struggle to generate vocals and accompaniments with prompt-based control and proper alignment. Additionally, they fall short in supporting various tasks. To address these challenges, we introduce VersBand, a multi-task song generation framework for synthesizing high-quality, aligned songs with prompt-based control. VersBand comprises these primary models: 1) VocalBand, a decoupled model, leverages the flow-matching method for generating singing styles, pitches, and mel-spectrograms, allowing fast, high-quality vocal generation with style control. 2) AccompBand, a flow-based transformer model, incorporates the Band-MOE, selecting suitable experts for enhanced quality, alignment, and control. This model allows for generating controllable, high-quality accompaniments aligned with vocals. 3) Two generation models, LyricBand for lyrics and MelodyBand for melodies, contribute to the comprehensive multi-task song generation system, allowing for extensive control based on multiple prompts. Experimental results demonstrate that VersBand performs better over baseline models across multiple song generation tasks using objective and subjective metrics. Audio samples are available at https://aaronz345.github.io/VersBandDemo.
Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis
Feb 26, 2025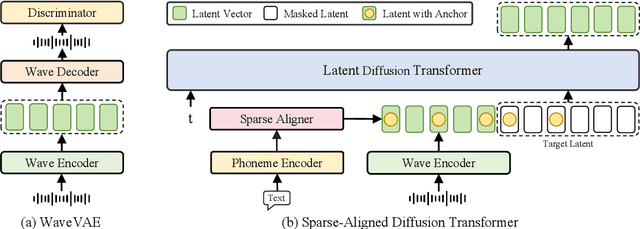
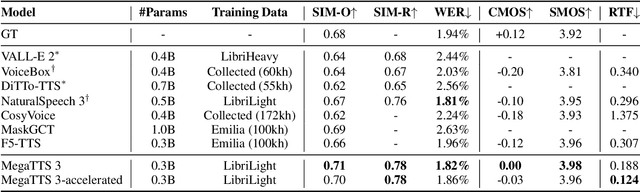
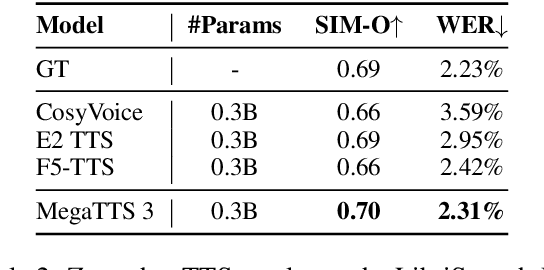

While recent zero-shot text-to-speech (TTS) models have significantly improved speech quality and expressiveness, mainstream systems still suffer from issues related to speech-text alignment modeling: 1) models without explicit speech-text alignment modeling exhibit less robustness, especially for hard sentences in practical applications; 2) predefined alignment-based models suffer from naturalness constraints of forced alignments. This paper introduces \textit{S-DiT}, a TTS system featuring an innovative sparse alignment algorithm that guides the latent diffusion transformer (DiT). Specifically, we provide sparse alignment boundaries to S-DiT to reduce the difficulty of alignment learning without limiting the search space, thereby achieving high naturalness. Moreover, we employ a multi-condition classifier-free guidance strategy for accent intensity adjustment and adopt the piecewise rectified flow technique to accelerate the generation process. Experiments demonstrate that S-DiT achieves state-of-the-art zero-shot TTS speech quality and supports highly flexible control over accent intensity. Notably, our system can generate high-quality one-minute speech with only 8 sampling steps. Audio samples are available at https://sditdemo.github.io/sditdemo/.
A Learnable Multi-views Contrastive Framework with Reconstruction Discrepancy for Medical Time-Series
Jan 30, 2025



In medical time series disease diagnosis, two key challenges are identified.First, the high annotation cost of medical data leads to overfitting in models trained on label-limited, single-center datasets. To address this, we propose incorporating external data from related tasks and leveraging AE-GAN to extract prior knowledge,providing valuable references for downstream tasks. Second, many existing studies employ contrastive learning to derive more generalized medical sequence representations for diagnostic tasks, usually relying on manually designed diverse positive and negative sample pairs.However, these approaches are complex, lack generalizability, and fail to adaptively capture disease-specific features across different conditions.To overcome this, we introduce LMCF (Learnable Multi-views Contrastive Framework), a framework that integrates a multi-head attention mechanism and adaptively learns representations from different views through inter-view and intra-view contrastive learning strategies.Additionally, the pre-trained AE-GAN is used to reconstruct discrepancies in the target data as disease probabilities, which are then integrated into the contrastive learning process.Experiments on three target datasets demonstrate that our method consistently outperforms seven other baselines, highlighting its significant impact on healthcare applications such as the diagnosis of myocardial infarction, Alzheimer's disease, and Parkinson's disease.
GaussianMarker: Uncertainty-Aware Copyright Protection of 3D Gaussian Splatting
Oct 31, 2024



3D Gaussian Splatting (3DGS) has become a crucial method for acquiring 3D assets. To protect the copyright of these assets, digital watermarking techniques can be applied to embed ownership information discreetly within 3DGS models. However, existing watermarking methods for meshes, point clouds, and implicit radiance fields cannot be directly applied to 3DGS models, as 3DGS models use explicit 3D Gaussians with distinct structures and do not rely on neural networks. Naively embedding the watermark on a pre-trained 3DGS can cause obvious distortion in rendered images. In our work, we propose an uncertainty-based method that constrains the perturbation of model parameters to achieve invisible watermarking for 3DGS. At the message decoding stage, the copyright messages can be reliably extracted from both 3D Gaussians and 2D rendered images even under various forms of 3D and 2D distortions. We conduct extensive experiments on the Blender, LLFF and MipNeRF-360 datasets to validate the effectiveness of our proposed method, demonstrating state-of-the-art performance on both message decoding accuracy and view synthesis quality.
MuVi: Video-to-Music Generation with Semantic Alignment and Rhythmic Synchronization
Oct 16, 2024



Generating music that aligns with the visual content of a video has been a challenging task, as it requires a deep understanding of visual semantics and involves generating music whose melody, rhythm, and dynamics harmonize with the visual narratives. This paper presents MuVi, a novel framework that effectively addresses these challenges to enhance the cohesion and immersive experience of audio-visual content. MuVi analyzes video content through a specially designed visual adaptor to extract contextually and temporally relevant features. These features are used to generate music that not only matches the video's mood and theme but also its rhythm and pacing. We also introduce a contrastive music-visual pre-training scheme to ensure synchronization, based on the periodicity nature of music phrases. In addition, we demonstrate that our flow-matching-based music generator has in-context learning ability, allowing us to control the style and genre of the generated music. Experimental results show that MuVi demonstrates superior performance in both audio quality and temporal synchronization. The generated music video samples are available at https://muvi-v2m.github.io.
TCSinger: Zero-Shot Singing Voice Synthesis with Style Transfer and Multi-Level Style Control
Sep 26, 2024



Zero-shot singing voice synthesis (SVS) with style transfer and style control aims to generate high-quality singing voices with unseen timbres and styles (including singing method, emotion, rhythm, technique, and pronunciation) from audio and text prompts. However, the multifaceted nature of singing styles poses a significant challenge for effective modeling, transfer, and control. Furthermore, current SVS models often fail to generate singing voices rich in stylistic nuances for unseen singers. To address these challenges, we introduce TCSinger, the first zero-shot SVS model for style transfer across cross-lingual speech and singing styles, along with multi-level style control. Specifically, TCSinger proposes three primary modules: 1) the clustering style encoder employs a clustering vector quantization model to stably condense style information into a compact latent space; 2) the Style and Duration Language Model (S\&D-LM) concurrently predicts style information and phoneme duration, which benefits both; 3) the style adaptive decoder uses a novel mel-style adaptive normalization method to generate singing voices with enhanced details. Experimental results show that TCSinger outperforms all baseline models in synthesis quality, singer similarity, and style controllability across various tasks, including zero-shot style transfer, multi-level style control, cross-lingual style transfer, and speech-to-singing style transfer. Singing voice samples can be accessed at https://tcsinger.github.io/.
GTSinger: A Global Multi-Technique Singing Corpus with Realistic Music Scores for All Singing Tasks
Sep 26, 2024



The scarcity of high-quality and multi-task singing datasets significantly hinders the development of diverse controllable and personalized singing tasks, as existing singing datasets suffer from low quality, limited diversity of languages and singers, absence of multi-technique information and realistic music scores, and poor task suitability. To tackle these problems, we present GTSinger, a large global, multi-technique, free-to-use, high-quality singing corpus with realistic music scores, designed for all singing tasks, along with its benchmarks. Particularly, (1) we collect 80.59 hours of high-quality singing voices, forming the largest recorded singing dataset; (2) 20 professional singers across nine widely spoken languages offer diverse timbres and styles; (3) we provide controlled comparison and phoneme-level annotations of six commonly used singing techniques, helping technique modeling and control; (4) GTSinger offers realistic music scores, assisting real-world musical composition; (5) singing voices are accompanied by manual phoneme-to-audio alignments, global style labels, and 16.16 hours of paired speech for various singing tasks. Moreover, to facilitate the use of GTSinger, we conduct four benchmark experiments: technique-controllable singing voice synthesis, technique recognition, style transfer, and speech-to-singing conversion. The corpus and demos can be found at http://gtsinger.github.io. We provide the dataset and the code for processing data and conducting benchmarks at https://huggingface.co/datasets/GTSinger/GTSinger and https://github.com/GTSinger/GTSinger.
WavTokenizer: an Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling
Aug 29, 2024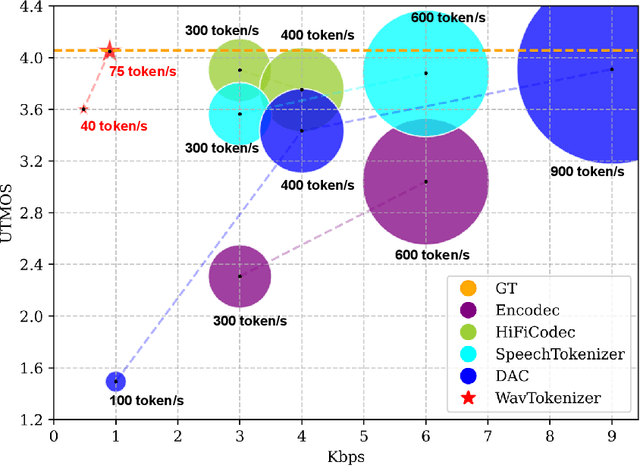
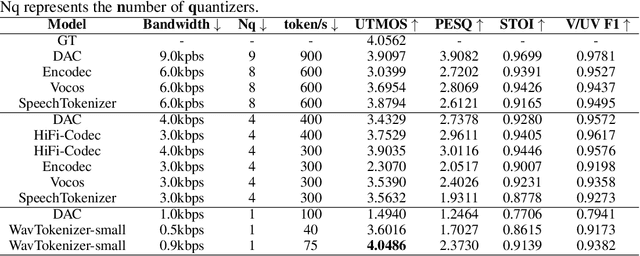
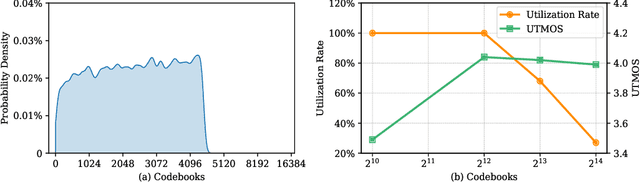
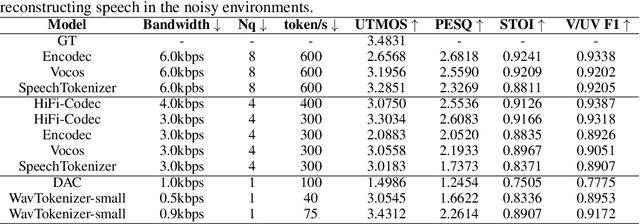
Language models have been effectively applied to modeling natural signals, such as images, video, speech, and audio. A crucial component of these models is the codec tokenizer, which compresses high-dimensional natural signals into lower-dimensional discrete tokens. In this paper, we introduce WavTokenizer, which offers several advantages over previous SOTA acoustic codec models in the audio domain: 1)extreme compression. By compressing the layers of quantizers and the temporal dimension of the discrete codec, one-second audio of 24kHz sampling rate requires only a single quantizer with 40 or 75 tokens. 2)improved subjective quality. Despite the reduced number of tokens, WavTokenizer achieves state-of-the-art reconstruction quality with outstanding UTMOS scores and inherently contains richer semantic information. Specifically, we achieve these results by designing a broader VQ space, extended contextual windows, and improved attention networks, as well as introducing a powerful multi-scale discriminator and an inverse Fourier transform structure. We conducted extensive reconstruction experiments in the domains of speech, audio, and music. WavTokenizer exhibited strong performance across various objective and subjective metrics compared to state-of-the-art models. We also tested semantic information, VQ utilization, and adaptability to generative models. Comprehensive ablation studies confirm the necessity of each module in WavTokenizer. The related code, demos, and pre-trained models are available at https://github.com/jishengpeng/WavTokenizer.