 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\mathbb{R}^{2k}$ is Theoretically Large Enough for Embedding-based Top-$k$ Retrieval
Jan 29, 2026This paper studies the minimal dimension required to embed subset memberships ($m$ elements and ${m\choose k}$ subsets of at most $k$ elements) into vector spaces, denoted as Minimal Embeddable Dimension (MED). The tight bounds of MED are derived theoretically and supported empirically for various notions of "distances" or "similarities," including the $\ell_2$ metric, inner product, and cosine similarity. In addition, we conduct numerical simulation in a more achievable setting, where the ${m\choose k}$ subset embeddings are chosen as the centroid of the embeddings of the contained elements. Our simulation easily realizes a logarithmic dependency between the MED and the number of elements to embed. These findings imply that embedding-based retrieval limitations stem primarily from learnability challenges, not geometric constraints, guiding future algorithm design.
ReLA: Representation Learning and Aggregation for Job Scheduling with Reinforcement Learning
Jan 08, 2026Job scheduling is widely used in real-world manufacturing systems to assign ordered job operations to machines under various constraints. Existing solutions remain limited by long running time or insufficient schedule quality, especially when problem scale increases. In this paper, we propose ReLA, a reinforcement-learning (RL) scheduler built on structured representation learning and aggregation. ReLA first learns diverse representations from scheduling entities, including job operations and machines, using two intra-entity learning modules with self-attention and convolution and one inter-entity learning module with cross-attention. These modules are applied in a multi-scale architecture, and their outputs are aggregated to support RL decision-making. Across experiments on small, medium, and large job instances, ReLA achieves the best makespan in most tested settings over the latest solutions. On non-large instances, ReLA reduces the optimality gap of the SOTA baseline by 13.0%, while on large-scale instances it reduces the gap by 78.6%, with the average optimality gaps lowered to 7.3% and 2.1%, respectively. These results confirm that ReLA's learned representations and aggregation provide strong decision support for RL scheduling, and enable fast job completion and decision-making for real-world applications.
NewtonBench: Benchmarking Generalizable Scientific Law Discovery in LLM Agents
Oct 08, 2025Large language models are emerging as powerful tools for scientific law discovery, a foundational challenge in AI-driven science. However, existing benchmarks for this task suffer from a fundamental methodological trilemma, forcing a trade-off between scientific relevance, scalability, and resistance to memorization. Furthermore, they oversimplify discovery as static function fitting, failing to capture the authentic scientific process of uncovering embedded laws through the interactive exploration of complex model systems. To address these critical gaps, we introduce NewtonBench, a benchmark comprising 324 scientific law discovery tasks across 12 physics domains. Our design mitigates the evaluation trilemma by using metaphysical shifts - systematic alterations of canonical laws - to generate a vast suite of problems that are scalable, scientifically relevant, and memorization-resistant. Moreover, we elevate the evaluation from static function fitting to interactive model discovery, requiring agents to experimentally probe simulated complex systems to uncover hidden principles. Our extensive experiment reveals a clear but fragile capability for discovery in frontier LLMs: this ability degrades precipitously with increasing system complexity and exhibits extreme sensitivity to observational noise. Notably, we uncover a paradoxical effect of tool assistance: providing a code interpreter can hinder more capable models by inducing a premature shift from exploration to exploitation, causing them to satisfice on suboptimal solutions. These results demonstrate that robust, generalizable discovery in complex, interactive environments remains the core challenge. By providing a scalable, robust, and scientifically authentic testbed, NewtonBench offers a crucial tool for measuring true progress and guiding the development of next-generation AI agents capable of genuine scientific discovery.
LOBE-GS: Load-Balanced and Efficient 3D Gaussian Splatting for Large-Scale Scene Reconstruction
Oct 02, 20253D Gaussian Splatting (3DGS) has established itself as an efficient representation for real-time, high-fidelity 3D scene reconstruction. However, scaling 3DGS to large and unbounded scenes such as city blocks remains difficult. Existing divide-and-conquer methods alleviate memory pressure by partitioning the scene into blocks, but introduce new bottlenecks: (i) partitions suffer from severe load imbalance since uniform or heuristic splits do not reflect actual computational demands, and (ii) coarse-to-fine pipelines fail to exploit the coarse stage efficiently, often reloading the entire model and incurring high overhead. In this work, we introduce LoBE-GS, a novel Load-Balanced and Efficient 3D Gaussian Splatting framework, that re-engineers the large-scale 3DGS pipeline. LoBE-GS introduces a depth-aware partitioning method that reduces preprocessing from hours to minutes, an optimization-based strategy that balances visible Gaussians -- a strong proxy for computational load -- across blocks, and two lightweight techniques, visibility cropping and selective densification, to further reduce training cost. Evaluations on large-scale urban and outdoor datasets show that LoBE-GS consistently achieves up to $2\times$ faster end-to-end training time than state-of-the-art baselines, while maintaining reconstruction quality and enabling scalability to scenes infeasible with vanilla 3DGS.
SegReConcat: A Data Augmentation Method for Voice Anonymization Attack
Aug 26, 2025Anonymization of voice seeks to conceal the identity of the speaker while maintaining the utility of speech data. However, residual speaker cues often persist, which pose privacy risks. We propose SegReConcat, a data augmentation method for attacker-side enhancement of automatic speaker verification systems. SegReConcat segments anonymized speech at the word level, rearranges segments using random or similarity-based strategies to disrupt long-term contextual cues, and concatenates them with the original utterance, allowing an attacker to learn source speaker traits from multiple perspectives. The proposed method has been evaluated in the VoicePrivacy Attacker Challenge 2024 framework across seven anonymization systems, SegReConcat improves de-anonymization on five out of seven systems.
Align 3D Representation and Text Embedding for 3D Content Personalization
Aug 23, 2025Recent advances in NeRF and 3DGS have significantly enhanced the efficiency and quality of 3D content synthesis. However, efficient personalization of generated 3D content remains a critical challenge. Current 3D personalization approaches predominantly rely on knowledge distillation-based methods, which require computationally expensive retraining procedures. To address this challenge, we propose \textbf{Invert3D}, a novel framework for convenient 3D content personalization. Nowadays, vision-language models such as CLIP enable direct image personalization through aligned vision-text embedding spaces. However, the inherent structural differences between 3D content and 2D images preclude direct application of these techniques to 3D personalization. Our approach bridges this gap by establishing alignment between 3D representations and text embedding spaces. Specifically, we develop a camera-conditioned 3D-to-text inverse mechanism that projects 3D contents into a 3D embedding aligned with text embeddings. This alignment enables efficient manipulation and personalization of 3D content through natural language prompts, eliminating the need for computationally retraining procedures. Extensive experiments demonstrate that Invert3D achieves effective personalization of 3D content. Our work is available at: https://github.com/qsong2001/Invert3D.
MMLongBench: Benchmarking Long-Context Vision-Language Models Effectively and Thoroughly
May 15, 2025The rapid extension of context windows in large vision-language models has given rise to long-context vision-language models (LCVLMs), which are capable of handling hundreds of images with interleaved text tokens in a single forward pass. In this work, we introduce MMLongBench, the first benchmark covering a diverse set of long-context vision-language tasks, to evaluate LCVLMs effectively and thoroughly. MMLongBench is composed of 13,331 examples spanning five different categories of downstream tasks, such as Visual RAG and Many-Shot ICL. It also provides broad coverage of image types, including various natural and synthetic images. To assess the robustness of the models to different input lengths, all examples are delivered at five standardized input lengths (8K-128K tokens) via a cross-modal tokenization scheme that combines vision patches and text tokens. Through a thorough benchmarking of 46 closed-source and open-source LCVLMs, we provide a comprehensive analysis of the current models' vision-language long-context ability. Our results show that: i) performance on a single task is a weak proxy for overall long-context capability; ii) both closed-source and open-source models face challenges in long-context vision-language tasks, indicating substantial room for future improvement; iii) models with stronger reasoning ability tend to exhibit better long-context performance. By offering wide task coverage, various image types, and rigorous length control, MMLongBench provides the missing foundation for diagnosing and advancing the next generation of LCVLMs.
Continual Pre-Training is (not) What You Need in Domain Adaption
Apr 18, 2025The recent advances in Legal Large Language Models (LLMs) have transformed the landscape of legal research and practice by automating tasks, enhancing research precision, and supporting complex decision-making processes. However, effectively adapting LLMs to the legal domain remains challenging due to the complexity of legal reasoning, the need for precise interpretation of specialized language, and the potential for hallucinations. This paper examines the efficacy of Domain-Adaptive Continual Pre-Training (DACP) in improving the legal reasoning capabilities of LLMs. Through a series of experiments on legal reasoning tasks within the Taiwanese legal framework, we demonstrate that while DACP enhances domain-specific knowledge, it does not uniformly improve performance across all legal tasks. We discuss the trade-offs involved in DACP, particularly its impact on model generalization and performance in prompt-based tasks, and propose directions for future research to optimize domain adaptation strategies in legal AI.
Transforming Future Data Center Operations and Management via Physical AI
Apr 07, 2025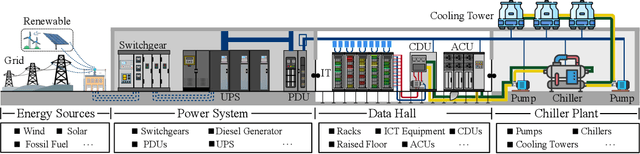
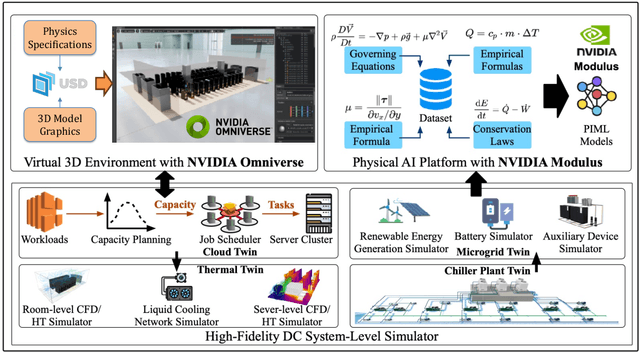
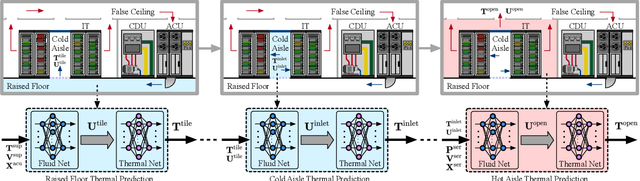
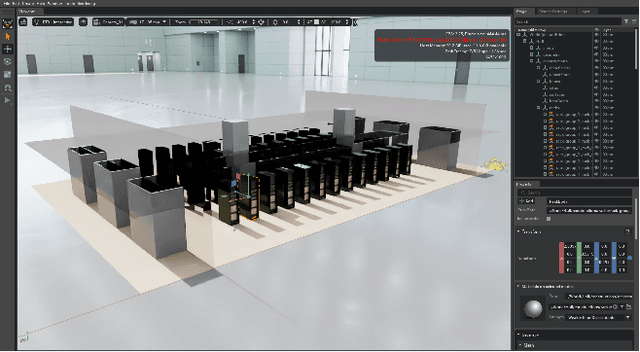
Data centers (DCs) as mission-critical infrastructures are pivotal in powering the growth of artificial intelligence (AI) and the digital economy. The evolution from Internet DC to AI DC has introduced new challenges in operating and managing data centers for improved business resilience and reduced total cost of ownership. As a result, new paradigms, beyond the traditional approaches based on best practices, must be in order for future data centers. In this research, we propose and develop a novel Physical AI (PhyAI) framework for advancing DC operations and management. Our system leverages the emerging capabilities of state-of-the-art industrial products and our in-house research and development. Specifically, it presents three core modules, namely: 1) an industry-grade in-house simulation engine to simulate DC operations in a highly accurate manner, 2) an AI engine built upon NVIDIA PhysicsNemo for the training and evaluation of physics-informed machine learning (PIML) models, and 3) a digital twin platform built upon NVIDIA Omniverse for our proposed 5-tier digital twin framework. This system presents a scalable and adaptable solution to digitalize, optimize, and automate future data center operations and management, by enabling real-time digital twins for future data centers. To illustrate its effectiveness, we present a compelling case study on building a surrogate model for predicting the thermal and airflow profiles of a large-scale DC in a real-time manner. Our results demonstrate its superior performance over traditional time-consuming Computational Fluid Dynamics/Heat Transfer (CFD/HT) simulation, with a median absolute temperature prediction error of 0.18 {\deg}C. This emerging approach would open doors to several potential research directions for advancing Physical AI in future DC operations.
The Curse of CoT: On the Limitations of Chain-of-Thought in In-Context Learning
Apr 07, 2025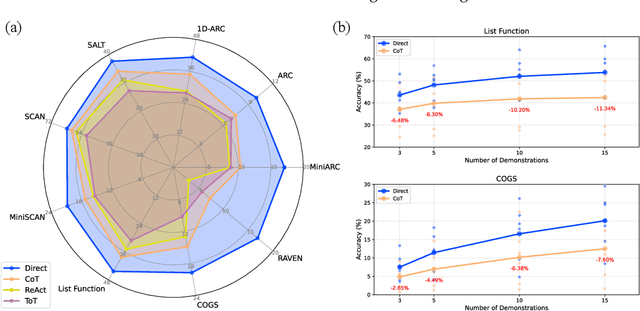
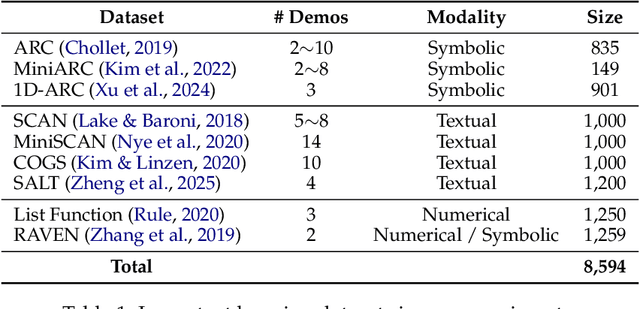
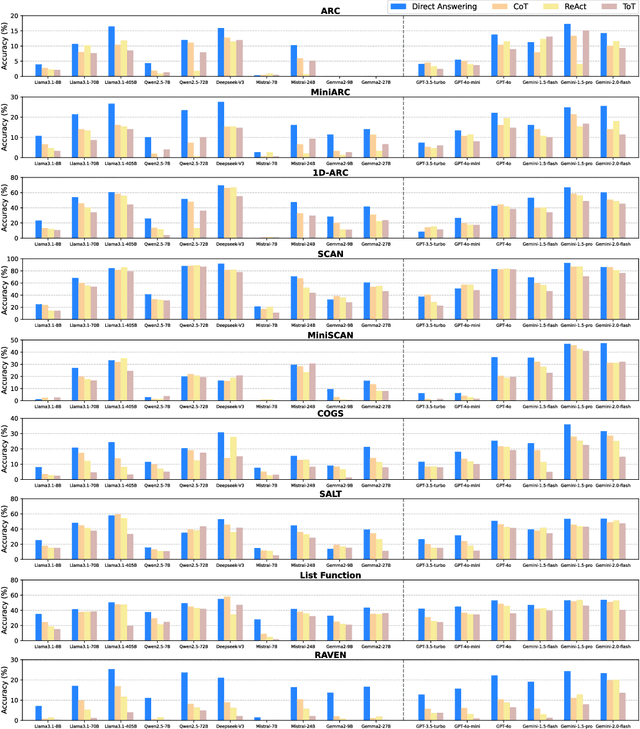
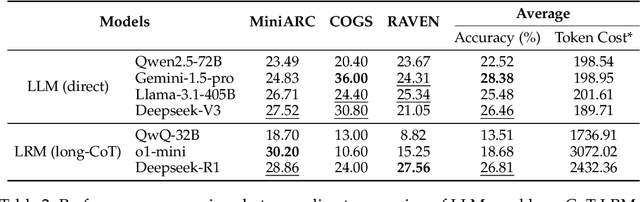
Chain-of-Thought (CoT) prompting has been widely recognized for its ability to enhance reasoning capabilities in large language models (LLMs) through the generation of explicit explanatory rationales. However, our study reveals a surprising contradiction to this prevailing perspective. Through extensive experiments involving 16 state-of-the-art LLMs and nine diverse pattern-based in-context learning (ICL) datasets, we demonstrate that CoT and its reasoning variants consistently underperform direct answering across varying model scales and benchmark complexities. To systematically investigate this unexpected phenomenon, we designed extensive experiments to validate several hypothetical explanations. Our analysis uncovers a fundamental explicit-implicit duality driving CoT's performance in pattern-based ICL: while explicit reasoning falters due to LLMs' struggles to infer underlying patterns from demonstrations, implicit reasoning-disrupted by the increased contextual distance of CoT rationales-often compensates, delivering correct answers despite flawed rationales. This duality explains CoT's relative underperformance, as noise from weak explicit inference undermines the process, even as implicit mechanisms partially salvage outcomes. Notably, even long-CoT reasoning models, which excel in abstract and symbolic reasoning, fail to fully overcome these limitations despite higher computational costs. Our findings challenge existing assumptions regarding the universal efficacy of CoT, yielding novel insights into its limitations and guiding future research toward more nuanced and effective reasoning methodologies for LLMs.